Введение: От понимания слов к пониманию мира
Привет, друзья! 👋 На связи manyachat.ru!
Мы уже говорили о том, что генеративные модели искусственного интеллекта способны не просто анализировать, но и создавать контент, а также поддерживать осмысленный диалог. Но возможности современного ИИ простираются гораздо дальше текстового взаимодействия. Сегодня передовые системы могут "видеть" и "понимать" визуальную информацию: распознавать текст на изображениях, анализировать сложные чертежи и даже выдавать по ним математические обоснования. 🤯
Это стало возможным благодаря развитию мультимодальных ИИ-моделей, таких как Gemini, на базе которой работает чат-бот Маня. Приготовьтесь удивляться!
Фундамент знаний: Откуда ИИ черпает информацию? 📚
Чтобы ИИ мог "понимать" и "рассуждать" о чем-либо, он должен быть обучен на колоссальных объемах данных. Этот процесс обучения формирует его "знания" о мире. Источники данных невероятно разнообразны:
- Текстовые данные: Миллиарды страниц книг, научных статей, веб-сайтов, энциклопедий, новостных лент, форумов и переписок. Это позволяет ИИ освоить язык, логику, факты и причинно-следственные связи
- Визуальные данные: Огромные коллекции изображений и видеороликов, часто сопровождаемые текстовыми описаниями (подписями, тегами). Сюда входят фотографии, иллюстрации, графики, диаграммы, карты, а также специализированные наборы данных, такие как медицинские снимки, спутниковые изображения или, что важно для нашего примера, инженерные чертежи и схемы
- Аудио данные: Записи речи, музыки, звуков окружающей среды, часто с текстовой транскрипцией
- Код: Миллионы строк программного кода на различных языках программирования
ИИ не просто запоминает эти данные. Он выявляет в них скрытые закономерности, статистические корреляции, концепции и абстракции, которые позволяют ему обобщать информацию и применять ее в новых, ранее не встречавшихся ситуациях.
Мультимодальный ИИ: Как происходит "зрение" и "понимание" изображений? 👁️
Ключевым прорывом, позволившим ИИ анализировать изображения, стала разработка мультимодальных архитектур. Это означает, что модель способна одновременно обрабатывать информацию из различных модальностей (текст, изображение, звук) и устанавливать связи между ними.
Рассмотрим процесс на примере загрузки чертежа в формате JPG в чат-бот Маня:
- Визуальное кодирование (Vision Encoder): Изображение, будь то фотография или чертеж, сначала поступает в специализированную часть нейронной сети – визуальный энкодер. Этот энкодер не просто "смотрит" на пиксели. Он последовательно обрабатывает изображение, извлекая из него все более сложные и абстрактные признаки:
- Базовые признаки: Края, углы, текстуры, цветовые переходы.
- Средние признаки: Обнаружение простых форм (круги, квадраты, линии), распознавание объектов (например, "гайка", "вал", "кнопка").
- Высокоуровневые признаки: Понимание композиции, структуры изображения, распознавание текста, встроенного в изображение (например, размеры, надписи на чертеже) - Объединение модальностей (Cross-Modal Alignment): Извлеченные визуальные признаки преобразуются в векторные представления (эмбеддинги), которые "понятны" основной языковой модели. Это критически важный этап: визуальная информация "переводится" на тот же "язык", на котором модель обрабатывает текстовые запросы. Это позволяет ИИ устанавливать прямые связи между тем, что он "видит", и тем, что он "знает" из текстовых описаний
- Контекстуальное понимание: На этом этапе ИИ не просто видит набор линий и цифр. Он понимает, что перед ним не абстрактный рисунок, а технический документ, содержащий информацию о форме, размерах и взаиморасположении элементов. Благодаря обучению на огромных массивах инженерных чертежей, схем и технической документации, он распознает в загруженном JPG-файле *концепцию* чертежа. Он способен идентифицировать стандартные обозначения, проекции, разрезы, интерпретируя их в рамках общей инженерной или дизайнерской логики
От "видения" к "математическому обоснованию": Как ИИ генерирует расчеты? ➕➖✖️➗
Способность ИИ выдавать математическое обоснование или рассчитывать параметры по изображению — это вершина его мультимодального и генеративного потенциала:
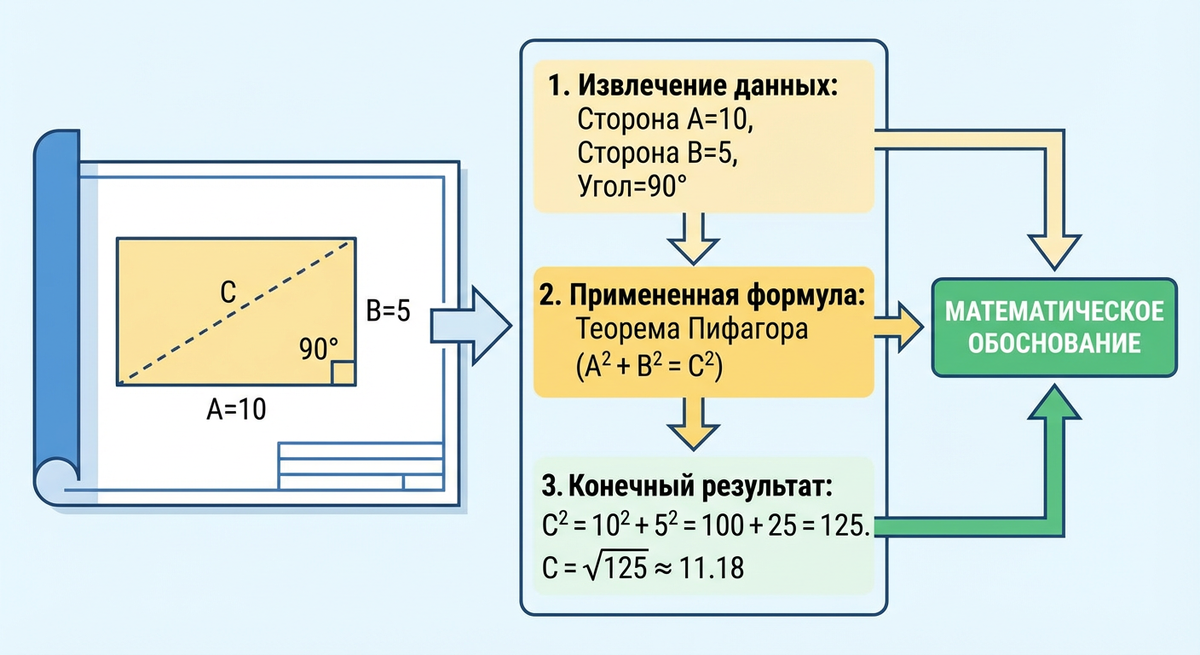
- Активация знаний: После "понимания" чертежа, Маня активирует свои внутренние знания в области геометрии, тригонометрии, физики, инженерных принципов. Она соотносит распознанные визуальные элементы (линии, дуги, точки пересечения) с соответствующими математическими концепциями
- Выявление связей и зависимостей: ИИ выявляет отношения между элементами чертежа: параллельность, перпендикулярность линий, углы между ними, радиусы окружностей. Он "видит" эти отношения не как человек, а как статистические паттерны, выученные из миллионов примеров
- Генерация обоснования: ИИ не выполняет расчеты в прямом смысле, как инженерный софт. Он *генерирует* текст, который является математическим обоснованием или описанием параметров, основываясь на своей обученности. Например, если он "видит" две перпендикулярные линии, он "знает", что между ними угол 90 градусов, и может сформулировать это, или, если видит треугольник с известными сторонами, может "предложить" расчет третьего угла, основываясь на тригонометрических функциях, которые он "выучил" из текстовых и визуальных данных
Маня в действии: Как мультимодальный ИИ Gemini решает ваши задачи? 🚀
Возможность мультимодального анализа кардинально расширяет спектр задач, которые можно поручить ИИ, делая эти удивительные возможности доступными прямо в вашем телефоне — у вас в мессенджере, без сложных настроек и специализированного ПО. Это позволяет вам использовать ИИ для решения задач, которые еще недавно казались уделом узких специалистов.
- Быстрый анализ документов: Извлечение данных из сканов или фотографий документов, мгновенное понимание содержимого
- Помощь в инженерных задачах: Получение первичного анализа, обоснования или проверки по чертежам
- Образование: Разъяснение принципов на основе схем и диаграмм, помощь в понимании сложных визуальных материалов
- Креатив: Генерация описаний для изображений или создание изображений по тексту, вдохновение для творческих проектов
- Для студентов и инженеров: Загрузите чертеж или схему в чат-бот - ИИ-модель Gemini поможет:
- Распознать элементы и их обозначения
- Проверить размеры и выполнить расчеты
- Найти ошибки или неточности в проекте
- Объяснить принцип работы сложного узла - Для дизайнеров и архитекторов: Отправьте эскиз или план помещения:
- Предложения по вариантам расстановки мебели с учетом размеров
- Расчет площадей для материалов
- Рекомендации по цветовым решениям или стилю - Для исследователей и аналитиков: Загрузите график, диаграмму или инфографику:
- ИИ извлечет данные и проанализирует тренды
- Сделает краткое резюме по ключевым показателям
- Предложит гипотезы на основе визуальной информации - Для повседневной жизни: Сфотографируйте инструкцию, рецепт или этикетку продукта:
- Маня распознает текст, переведет его или объяснит сложные термины.
- Поможет разобраться в схеме сборки мебели
Использование чат-бота на базе Gemini для работы с изображениями дает вам ряд неоспоримых преимуществ:
- Скорость и эффективность: Мгновенный анализ и расчеты, которые заняли бы часы ручной работы
- Точность: ИИ минимизирует человеческий фактор ошибок при распознавании и расчетах
- Доступность: Мощные аналитические инструменты доступны прямо в вашем телефоне через мессенджер, без необходимости специализированного ПО
- Новые возможности: Решайте задачи, которые раньше казались невозможными или требовали узкоспециализированных знаний
- Экономия ресурсов: Сокращение времени и трудозатрат на рутинные операции
Заключение: Будущее, которое уже здесь – в вашем мессенджере! 🔮
Эпоха, когда ИИ был лишь "умным текстовым редактором", ушла в прошлое. Мультимодальные возможности Gemini, реализованные в чат-боте Маня, открывают дверь в мир, где ИИ способен не только понимать язык, но и "видеть", "анализировать" и "рассуждать" о визуальной информации. Это делает Маню незаменимым помощником для широкого круга задач, от Готовы увидеть, как Маня "видит" мир и поможет вам в работе?
____________
❓ В чем вам помогают ИИ-модели по типу Gemini и GPT-4? Делитесь своими идеями в комментариях! 👇
#ИИ, #ИскусственныйИнтеллект, #Нейросети, #Технологии, #ТехнологииБудущего, #ЧатБот, #Gemini, #Маня, #МультимодальныйИИ, #ГенеративныйИИ, #ГенеративныеМодели, #КомпьютерноеЗрение, #АнализИзображений, #МатематическиеРасчетыИИ, #ОбработкаИзображений, #ИИдляИнженеров, #ИИдляДизайнеров, #ИИдляСтудентов, #manyachat, #ВизуальныйИИ, #РаспознаваниеИзображений, #AI, #AIvision, #AIпомощник, #НовыеВозможностиИИ, #НовыеВозможностиИИ #ВизуальныйИИ #manyachat.ru