Anthropic обновили свою флагманскую модель Opus. Если коротко: это не просто «умный чат», а попытка сделать полноценного автономного сотрудника с акцентом на тяжелый кодинг и работу с данными. Opus 4.6 получил контекстное окно в 1 000 000 токенов. Но важнее технические надстройки: Разработчики признали: глубокое рассуждение (Reasoning) — это долго и дорого. Поэтому ввели гибкое управление: В Opus 4.6 основной упор сделан на агентность (способность действовать без пошаговых команд): В тестах на профессиональные знания (финансы, право, аналитика) Opus 4.6 обходит GPT-5.2 на 144 пункта Elo. Больше новостей о нейросетях в телеграмм:
Anthropic обновили свою флагманскую модель Opus. Если коротко: это не просто «умный чат», а попытка сделать полноценного автономного сотрудника с акцентом на тяжелый кодинг и работу с данными.

Контекст в миллион и борьба с «забывчивостью»
Opus 4.6 получил контекстное окно в 1 000 000 токенов. Но важнее технические надстройки:
- Context Compaction: Фича для API. Модель сама сжимает (резюмирует) старый контекст, когда он приближается к лимиту. Это решает проблему «глюков» модели в очень длинных диалогах.
- Поиск информации: В тесте «Иголка в стоге сена» (MRCR v2) на 1 млн токенов Opus 4.6 показывает 76% точности. Для сравнения, у Sonnet 4.5 на этом же объеме было всего 18,5%. Разница в удержании фактов колоссальная.
«Слайдер усилий» и адаптивное мышление
Разработчики признали: глубокое рассуждение (Reasoning) — это долго и дорого. Поэтому ввели гибкое управление:
- Adaptive Thinking: Модель сама решает, нужно ли ей «зависать» над задачей или можно ответить быстро.
- Параметр /effort: Пользователь (или разработчик через API) может сам выставить уровень «тщательности» — Low, Medium, High или Max. Если вам нужно просто поправить опечатку, ставите Low. Если проектируете архитектуру банка — Max.
Автономный кодинг и агентские команды
В Opus 4.6 основной упор сделан на агентность (способность действовать без пошаговых команд):
- Multi-agent teams: В Claude Code теперь можно запускать целые команды агентов, которые работают параллельно. Например, один пишет код, другой делает ревью, третий проверяет безопасность.
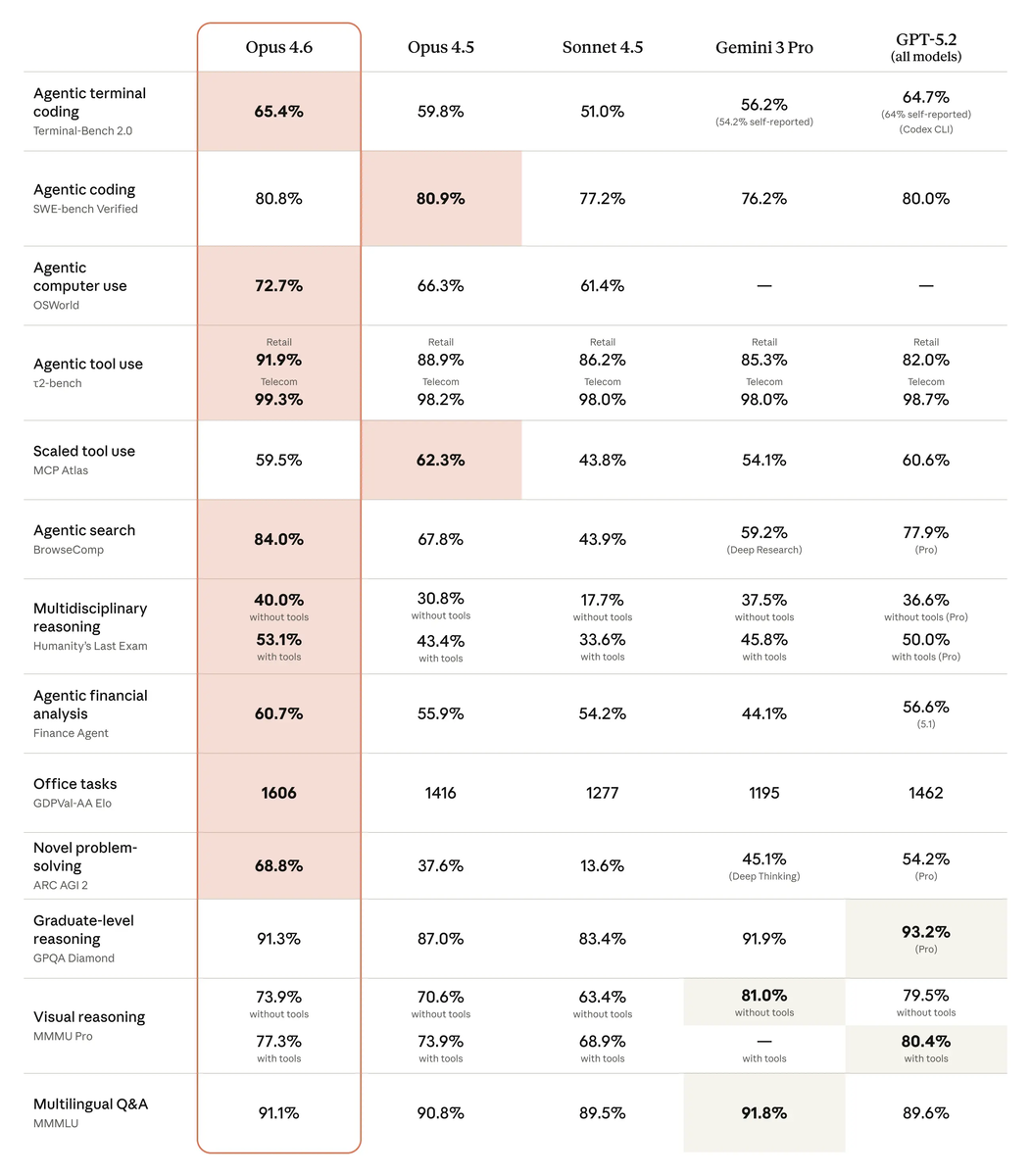
- Планирование: Модель стала лучше делить одну большую задачу на подзадачи. На бенчмарке Terminal-Bench 2.0 (автономный кодинг) модель вышла в лидеры.
Что там по цифрам против GPT-5.2?
В тестах на профессиональные знания (финансы, право, аналитика) Opus 4.6 обходит GPT-5.2 на 144 пункта Elo.
- GDPval-AA: Здесь замеряли эффективность в реальных задачах белых воротничков. Opus 4.6 побеждает в 70% случаев при прямом сравнении с моделью от OpenAI.
- Cybersecurity: В 38 из 40 тестов на киберрасследования модель показала лучший результат среди конкурентов.
Больше новостей о нейросетях в телеграмм: