PostgreSQL «из коробки» и пределы роста
Один из ключевых выводов этого опыта — PostgreSQL способен эффективно работать в очень крупных масштабах без радикальных изменений архитектуры. Как отмечают в Microsoft, ChatGPT достиг аудитории в 800+ млн пользователей до того, как OpenAI начала переносить новые и легко шардируемые нагрузки в Azure Cosmos DB.
Тем не менее, поддержка одного из крупнейших в мире развёртываний PostgreSQL стала серьёзным испытанием для обеих команд. Инженеры OpenAI оперативно адаптировали свои системы под стремительный рост, а команда Azure PostgreSQL параллельно дорабатывала сам сервис. Важно, что эти улучшения были внедрены на уровне платформы и стали доступны всем клиентам Azure Database для PostgreSQL с высокими нагрузками.
Сетевые проблемы репликации и отказ от CUBIC
Одной из первых серьёзных проблем стала задержка репликации между основным сервером PostgreSQL и геораспределёнными read-репликами.
Изначально Azure Database for PostgreSQL использовал стандартный алгоритм управления перегрузкой TCP — CUBIC. В преддверии одного из крупных запусков OpenAI инженеры заметили, что часть read-реплик периодически начинала сильно отставать от основного сервера. Репликация могла работать стабильно, а затем внезапно «залипать», не восстанавливаясь самостоятельно. В итоге автоматике приходилось перезапускать реплику — после чего цикл повторялся снова.
После длительного анализа выяснилось, что причина кроется в поведении CUBIC при повышенном уровне потерь пакетов. Для межрегионального трафика такие потери ожидаемы, но CUBIC трактует их как признак перегрузки и слишком агрессивно снижает скорость передачи.
Решение включало сразу несколько шагов:
- переход на алгоритм BBR (Bottleneck Bandwidth and RTT), менее чувствительный к потерям пакетов;
- настройку SKU-специфичных TCP window;
- использование дисциплины очередей Fair Queuing, позволяющей управлять pacing’ом пакетов на уровне оборудования.
Важную роль сыграли и рекомендации опытных пользователей PostgreSQL, которые помогли быстрее локализовать первопричину. В результате проблема задержек репликации была устранена.
Масштабирование с помощью реплик на чтение
Основные серверы PostgreSQL при правильной настройке отлично поддерживают большое количество реплик. Как отмечено в блоге OpenAI, один основной сервер смог обеспечивать работу более 50 реплик в нескольких регионах. Однако превышение этого порога увеличивает риск влияния на основной сервер. По этой причине мы добавили поддержку каскадных реплик.
Это повлекло за собой необходимость обработки новых сценариев сбоев. Система должна координировать восстановление отставших промежуточных узлов, безопасно перенаправлять реплики на новые промежуточные узлы и выполнять операции catch-up или rewind в условиях критически важной инфраструктуры.
Кроме того, сценарии аварийного восстановления (DR) требуют быстрого пересоздания реплики. Поскольку перемещение данных между регионами — процесс дорогой и долгий, мы разработали возможность создания гео-реплики из снимка (snapshot) другой реплики в том же регионе. Это позволяет избежать копирования данных, которое может длиться часы или дни, используя данные кластера, уже существующие в данном регионе. Скоро эта функция станет доступна всем клиентам.
Описанные улучшения решили проблемы с задержкой и масштабированием чтения, но не помогли с ростом масштабов записи. В какой-то момент лимиты IOPS одиночного экземпляра Postgres стали недостаточными. В результате OpenAI решила перенести новые шардируемые нагрузки в Azure Cosmos DB (наше рекомендуемое NoSQL-хранилище). Однако некоторые нагрузки шардировать гораздо сложнее.
Многие требования по масштабированию записи были заложены в наше новое предложение Azure HorizonDB, которое вошло в стадию частного превью в ноябре 2025 года.
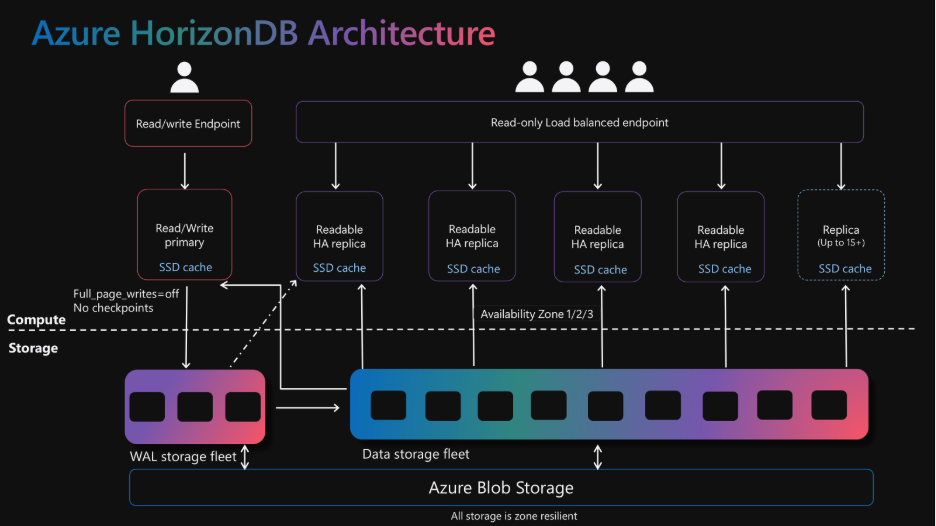
Архитектура масштабирования Azure HorizonDB
Azure HorizonDB вводит новый слой хранения для Postgres:
- Эффективное чтение: Репликам больше не нужно хранить свою копию данных — они читают страницы из единой копии в слое хранения.
- Низкая задержка WAL: Раздельные сервисы для хранения логов (WAL) и страниц данных.
- Stateless Compute: Задачи обеспечения отказоустойчивости перенесены с узла Postgres на слой хранения.
- Быстрый Failover: Переключение на резерв происходит быстрее и надежнее.
HorizonDB использует лог-ориентированную модель: журнал упреждающей записи (WAL) — единственный механизм фиксации изменений. Вычислительные узлы PostgreSQL никогда не пишут страницы данных напрямую. Вместо этого страницы реконструируются и обновляются из записей WAL парком серверов хранения.
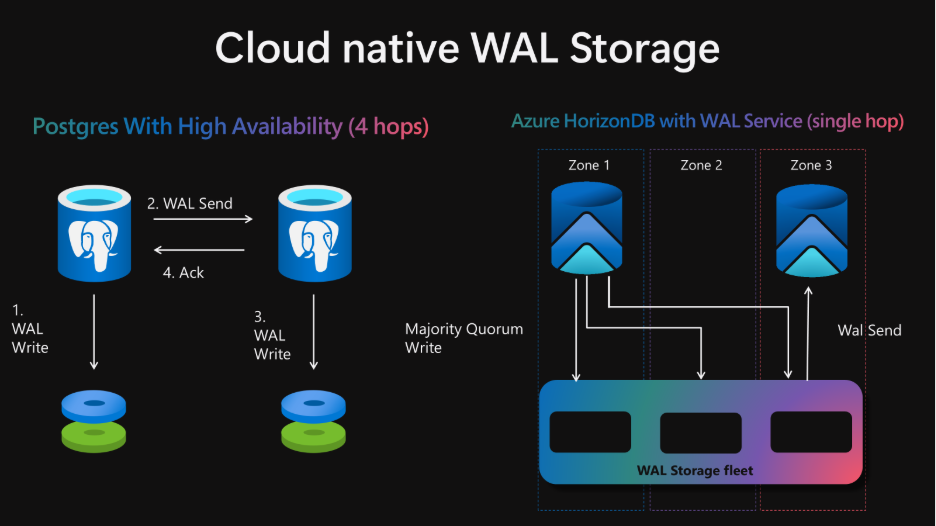
Разделение на WAL-сервер (оптимизирован для последовательной записи с низкой задержкой) и Page-сервер (оптимизирован для случайного чтения терабайт данных) позволяет справляться с интенсивными OLTP-нагрузками. WAL-сервер фиксирует транзакцию в трех зонах доступности за один сетевой «прыжок» (в обычной схеме их 4).
В таблице ниже приведены задачи, которые в стандартном PostgreSQL выполняет основной узел, а в HorizonDB они перенесены на слой хранения:
Задача Экономия ресурсов Перенесенный процесс Отправка WAL репликам Сеть, Диск Walsender Архивация WAL в blob Сеть, Диск Archiver Запись «грязных» страниц Диск Background writer Создание контрольных точек Диск Checkpointer Регенерация страниц (Redo) CPU, Диск Startup recovering Резервное копирование Диск pg_dump / snapshots
Все эти операции берёт на себя HorizonDB Storage, а бэкапы выполняются через снапшоты Azure Storage. Это даёт существенную экономию CPU, диска и сети, а также позволяет масштабировать количество read-реплик без нагрузки на primary.
Общая архитектура хранения (Shared Storage) в Azure HorizonDB является фундаментом для исключительной масштабируемости. Пользователи могут мгновенно запускать реплики на чтение без копирования данных. Слой хранения гарантирует единый «источник истины», предотвращая расхождение данных после сбоя и устраняя необходимость в дорогостоящих операциях вроде pg_rewind.
Azure HorizonDB была спроектирована с нуля на основе опыта работы с крупнейшими клиентами, чтобы соответствовать требованиям самых тяжелых нагрузок в мире.
Итог
Azure HorizonDB — результат практических уроков, полученных при работе с одними из самых нагруженных PostgreSQL-кластеров в мире. Архитектура ориентирована на экстремальные OLTP-нагрузки, высокую эластичность, масштабируемость и отказоустойчивость.
Благодаря общей архитектуре хранения (Shared Storage), новые реплики в HorizonDB создаются мгновенно без копирования данных. Это позволяет динамически масштабировать систему под всплески нагрузки ChatGPT, не влияя на производительность основного сервера.
Источник: techcommunity.microsoft.com
https://la.by/news/kak-chatgpt-masshtabirovalsya-na-postgresql-v-azure-opyt-openai-i-microsoft