Если главный админ пропадает, компания теряет не человека, а доступ к знаниям и управлению инфраструктурой: пароли, схемы, точки отказа, порядок действий при инцидентах и связи с подрядчиками. Это и есть «эффект автобуса» (bus factor): риск того, что проект или система остановятся, если недоступны один или несколько носителей критичных знаний.

Что такое bus factor и почему он про деньги, а не про HR
Bus factor называют числом людей, потеря которых делает работу команды или продукта невозможной из-за концентрации знаний у нескольких специалистов. В определении часто используют метафору «если человека сбил автобус», но в реальности причины банальнее: отпуск, болезнь, увольнение, недоступность в мессенджерах.
В эксплуатации и DevOps bus factor часто проявляется во время инцидента: алерты есть, но только один человек знает, какой сервис перезапустить, где лежит runbook, и какие доступы нужны.
Чем bus factor отличается от «ключевого сотрудника»
Классический «ключевой сотрудник» иногда понимают как незаменимого эксперта, но bus factor фокусируется на том, что знания не разделены и не зафиксированы. Если знания записаны в документации и доступны команде, уход конкретного человека перестает быть аварией для бизнеса.
Практичный вывод простой: цель не «заменить админа», а отчуждать знания в систему и поддерживать их актуальными.
Что ломается в первые 24 часа без главного админа
Первый день без основного администратора редко выглядит как «все упало». Чаще начинается с мелких блокировок, которые цепочкой превращаются в простой и риск ИБ.
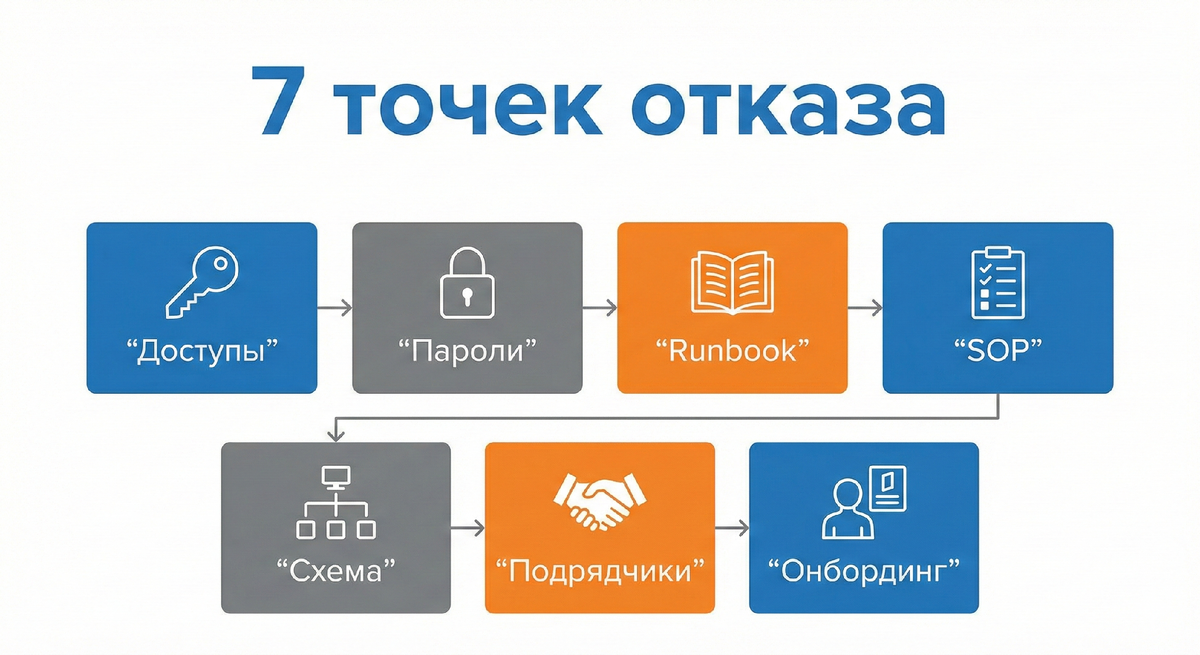
7 типовых точек отказа
- Доступы и пароли. Пароли, ключи, токены, VPN, доступ к гипервизору или облаку могут быть известны одному человеку.
- Порядок действий при инциденте. Инцидент есть, но нет runbook: что проверять, кого подключать, какие команды безопасны.
- Нестандартные решения. Самописные скрипты, «костыли», ручные процедуры без SOP (standard operating procedure, стандартная операционная процедура) тормозят восстановление.
- Схема инфраструктуры. Нет карты: где что стоит, какие зависимости у сервисов, какие порты и ACL критичны.
- Права доступа. Люди не могут зайти туда, где лежит документация, или наоборот, доступы слишком широкие и это риск ИБ.
- Контакты подрядчиков. Договоры, контакты и регламент эскалации хранятся в личной почте.
- Онбординг новых инженеров. Новичок не понимает, где искать правду, и начинает спрашивать старших, поднимая нагрузку на команду.
Как измерить «фактор автобуса» в IT за 60 минут
Цель экспресс-оценки не в том, чтобы получить идеальную цифру, а чтобы увидеть критические «узкие горлышки» и начать с них. В МТС Web Services описывают практику оценки Bus Factor через зоны риска и сценарии инцидентов, где отсутствие плана действий становится уязвимостью.
Карта зависимостей: системы, доступы, процедуры
За 60 минут можно собрать таблицу, которая покажет реальную картину.
Заполняется быстро: по 5-7 критичным системам и 2-3 процедурам на систему. Затем выбираются 3 приоритета: где нет документации, нет дублера, и доступы не контролируются.
План снижения bus factor за 14 дней
Низкий bus factor решается не героизмом, а дисциплиной: документация как deliverable, контроль версий, права доступа, тренировки «админ недоступен». Такой подход описывают и практики эксплуатации, и статьи про риск смены системного администратора.
День 1-3: быстрый сбор критичных знаний
- Составить список критичных систем и сервисов: прод, сеть, VPN, почта, бэкапы, домен, телефония.
- Зафиксировать «как есть»: схема, точки входа, где лежат конфиги, кто владельцы.
- Собрать «пакет доступа»: где хранятся пароли, кто имеет право выдавать доступ, как проходит отзыв доступов.
Результат 3 дня: команда знает, где искать информацию, а не ищет человека.
День 4-7: runbook, SOP и контроль версий
Runbook это инструкция для конкретного инцидента или процедуры в эксплуатации: что делать пошагово, какие проверки выполнять, куда смотреть логи. SOP это стандартная процедура, чтобы операции выполнялись одинаково, независимо от того, кто дежурит.
- Завести шаблон runbook: симптомы, проверка, действия, откат, контакты, критерии «починили».
- Включить версионирование: каждая правка фиксируется, есть история и возможность отката.
- Добавить audit log: видно, кто и когда изменил критичную инструкцию.
Для устойчивости важно, чтобы документация была не «где-то», а находилась за 10 секунд. DORA 2024 отмечает ценность систем, которые повышают независимость разработчиков, включая документацию и self-serve подход.
День 8-14: дублеры, тренировки, обновление базы знаний
- Назначить дублеров по критичным зонам: сеть, бэкапы, доступы, прод.
- Провести тренировку: «владелец недоступен 24 часа», команда решает 2-3 типовых инцидента по runbook.
- После тренировки обновить статьи: убрать пробелы, добавить скриншоты, уточнить команды, описать ограничения.
Результат 14 дней: снижение зависимости от одного человека, ускорение реакции на инциденты и спокойный онбординг новичка.
Почему база знаний лучше папки в облаке
Папка с файлами помогает хранить документы, но не решает главную проблему: найти нужное, понять что актуально, ограничить доступ и зафиксировать изменения. Для IT команды это критично, потому что доступы и регламенты относятся к безопасности.
Требования к базе знаний для IT: поиск, права, версии, аудит
У базы знаний для IT есть минимальный набор требований:
- Полнотекстовый поиск по статьям и файлам, чтобы находить конфиг, IP или скрипт по одному запросу.
- Права доступа и интеграция с корпоративной учеткой (LDAP/AD/SSO), чтобы секреты не уходили в общий доступ.
- Версионирование и audit log, чтобы критичные инструкции не менялись «тихо».
- Workflow публикации: черновик, проверка, публикация, чтобы документация не превращалась в мусор.
Как KBPublisher помогает убрать «эффект автобуса»
KBPublisher позиционируется как база знаний для IT команд с полнотекстовым поиском, версионированием, audit log и интеграцией с LDAP/AD, что закрывает ключевые требования к управлению знаниями в IT.
Практичный сценарий выглядит так:
- Создаются разделы «Инфраструктура», «Доступы», «Инциденты», «Регламенты», «Онбординг». Это превращает знания в навигацию, а не в архив.
- Для критичных процессов добавляются шаблоны статей: runbook для P1, SOP для бэкапа, чеклист ревокации доступов. Шаблоны ускоряют создание документации и выравнивают качество.
- Настраиваются права и роли: кто читает, кто редактирует, кто утверждает. Это снижает риск утечки и повышает доверие к базе.
С точки зрения бизнеса эффект измеряется простыми метриками: время поиска, время реакции на инцидент, срок онбординга, доля повторяющихся вопросов.
Мини-чеклист: что сделать уже сегодня
- Собрать список критичных систем и владельцев.
- Проверить, где лежат пароли и кто контролирует доступ.
- Создать один шаблон runbook и один шаблон SOP.
- Сложить это в единую базу знаний с правами, версиями и поиском.
Эффект автобуса в IT почти всегда возникает из-за отсутствия единого источника правды: документации, runbook, SOP и прозрачных доступов. Если знания фиксируются, версионируются и доступны команде, отсутствие главного администратора перестает быть остановкой бизнеса.
Чтобы быстро снизить bus factor, начните с базы знаний KBPublisher и перенесите в нее критичные инструкции, доступы и регламенты.