
На этой неделе выпуск Opus 4.6 встряхнул турнирные таблицы ИИ-агентов. Новая модель Anthropic показала значительный скачок в решении профессиональных задач. — techcrunch.com
В прошлом месяце я писал о новом бенчмарке Mercor, измеряющем возможности ИИ-агентов в профессиональных задачах, таких как юриспруденция и корпоративный анализ. Тогда результаты были довольно удручающими: каждая крупная лаборатория показала результат ниже 25%, поэтому мы пришли к выводу, что юристы пока могут не опасаться замены искусственным интеллектом.
Однако возможности ИИ могут кардинально измениться за пару недель.
Выпуск Anthropic Opus 4.6 на этой неделе встряхнул турнирные таблицы: новая модель Anthropic показала результат чуть менее 30% в однопроходных тестах и в среднем 45% при нескольких попытках решения задачи. Примечательно, что выпуск включал ряд новых агентных функций, в том числе «роящиеся агенты», которые могли способствовать решению таких многошаговых задач.
В любом случае, этот результат является огромным скачком по сравнению с предыдущим уровнем развития технологий и признаком того, что прогресс в области фундаментальных моделей не замедляется. Генеральный директор Mercor Брендан Фуди, который был особенно впечатлен, сказал: «переход с 18,4% до 29,8% за несколько месяцев — это безумие».
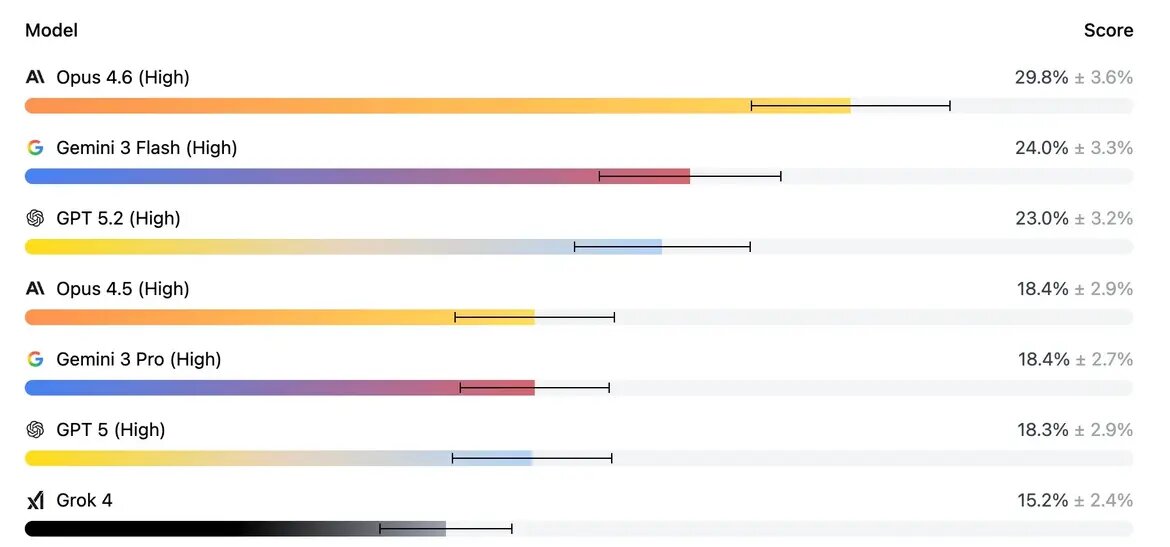
Тридцать процентов — это все еще очень далеко от 100%, так что юристам не стоит беспокоиться о замене машинами на следующей неделе. Но уверенности у них должно быть гораздо меньше, чем в прошлом месяце!
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Russell Brandom