Строка из одного или более символов называется звеном, если вся она не может быть разбита на две или более одинаковые части. Строка символов, образованная повторением некоторого звена два и более раз, называется цепочкой.
Вводится последовательность символов, являющаяся фрагментом некоторой цепочки и превышающая по длине звено, повторением которого эта цепочка образована.
Требуется вывести на печать это звено.
Решение
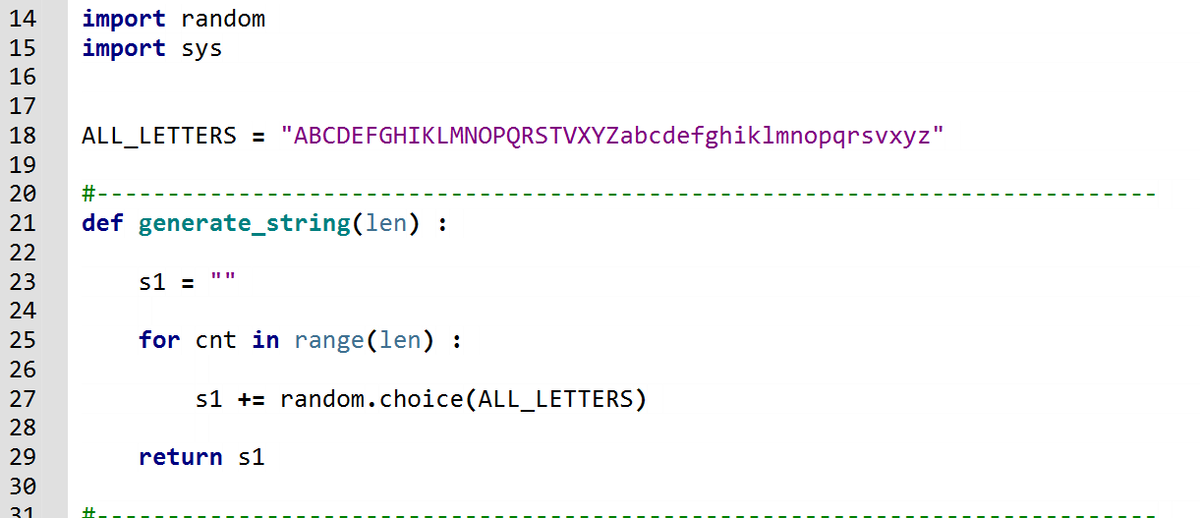
Для начала просто укажем в коде список символов, из которых может быть сформирована проверяемая последовательность, и научимся генерировать такую последовательность случайно (Рис_1)
Предлагается самая "тупая" (прямолинейная) стратегия решения: мы будем просто перебирать все возможности того, что данная последовательность может оказаться цепью из одинаковых символов длиной 2, длиной 3, и так далее символов, до полной длины последовательности.
В качестве кандидата на звено будем брать соответственно подстроку из первых 2-х, 3-х и т.д. символов в строке. На самом деле надо перебирать до L - 1 (L - длина всего фрагмента). Почему?
Нам сказано, что у нас фрагмент вероятной цепи с длиной больше чем одно звено. Значит, может остаться некий "хвост", короче чем одно звено, но такой, что он представляет собой некий начальный кусок этого звена. Значит, максимально возможное звено может иметь длину L - 1 , при этом последний символ всей строки (то бишь последовательности) должен совпадать с первым символом этого звена, то есть - всей строки как таковой.
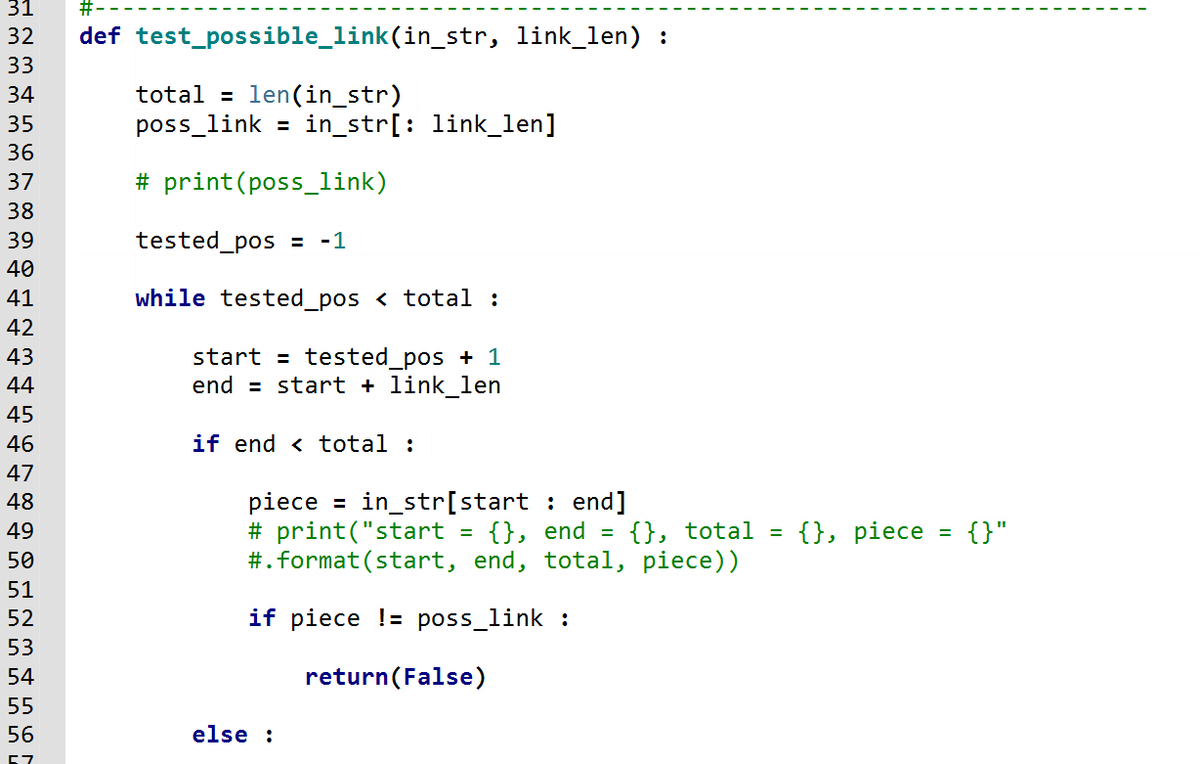
Поэтому, сначала нам понадобится функций, которая проверяет что существует звено длиной link_len. Мы просто берем первые link_len символов строки и пытаемся их прикладывать один за другим вдоль всей строки. Либо где-то не приложится, либо этот отрезок действительно является звеном (Рис_2а, Рис_2b):
Далее, нам понадобится функция, которая перебирает все возможные link_len - назовем это "полной проверкой" (Рис_3):
Наконец, мы либо передаем интересующую нас строку как аргумент командной строки при вызове программы (в Python это массив sys.argv), либо - если пользователь никакой конкретной строки не указал - сами генерим случайную последовательность (Рис_4):
Теперь вызовем нашу программу из командой строки PowerShell операционной системы Windows (Рис_5):
В этот момент меня прошиб холодный пот: постойте, но ведь хвост может присутствовать не в качестве начала звена в конце строки, но и в качестве концовки звена в начале строки!
Ах, ах, а что это значит - что надо добавить проверку задом наперед: от конца последовательности к её началу? Вовсе нет, смотрите (Рис_6):
Оказывается, можно проверять только первым способом (от начала к концу), но при этом получается, что у последовательности есть другое звено?! Да, это правильно - подумайте сами, почему.
Вообще, если мы нашли какое-то одно звено, то законными звеньями так же являются все циклические посимвольные перестановки этого звена, то есть: если есть qura, то звеньями будут uraq, raqu, aqur. Проверьте сами ))
Над чем подумать
Надо подумать над тем, как сделать однопроходный алгоритм. Сейчас в функции full_test() мы нарезаем (пытаемся нарезать, проверяем эту возможность) полную последовательность на звено данной длины для каждой длины отдельно, делаем число проходов ~L.
А надо все это умудриться сделать за один проход ))
Видимо, нам понадобится расширяемый массив (или словарик) звеньев, вовлекаемых в проверку по мере продвижения одного сканирования строки символ за символом.
То есть, за скорость алгоритма по времени придется заплатить бОльшим расходом памяти. Так всегда и бывает, это типичная ситуация.