🔥 Вчера был жаркий вечер — Anthropic и OpenAI выкатили обновления почти одновременно.
Контекстное окно выросло в 4 раза — теперь миллион токенов. И главное, модель реально находит нужную инфу в этом объёме: 93% точность на 256к и 75% на миллионе. У Sonnet 4.5 было 11% и 19%. Разница космическая.
Что ещё интересного:
⏺️Adaptive thinking — раньше режим размышлений был вкл/выкл, теперь 4 уровня: low, medium, high, max
⏺️Compaction — модель сама сжимает контекст по ходу работы, делает саммари диалога. Можно настроить свои правила: когда запускать, какие данные обязательно сохранять
⏺️Agent Teams в Claude Code — субагенты теперь работают пачками и общаются между собой, а не просто отчитываются главному
⏺️Delegate mode — основной агент только раздаёт задачи, сам код не трогает. Раньше приходилось вручную заставлять его так работать, теперь включается через Shift+Tab при работе в терминале.
〰️
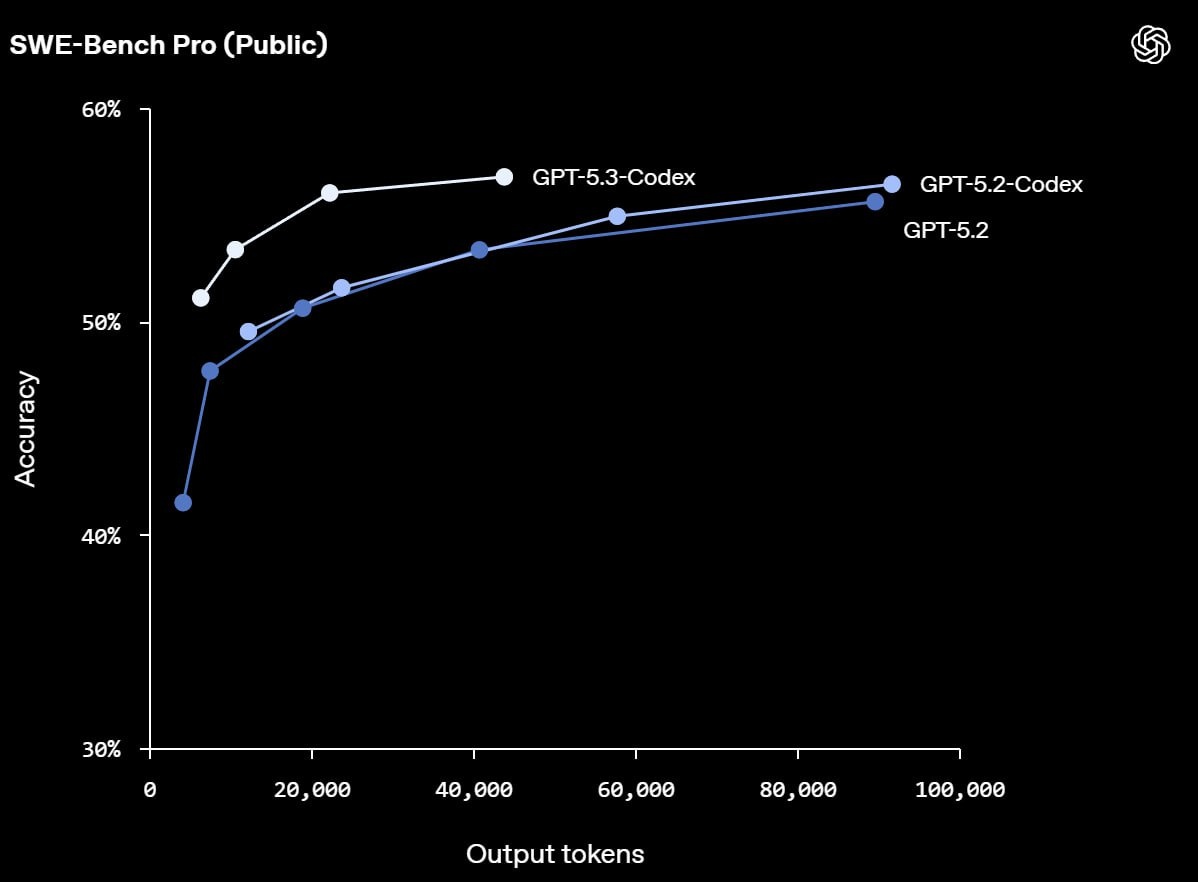
А следом OpenAI выпустили GPT-5.3 Codex
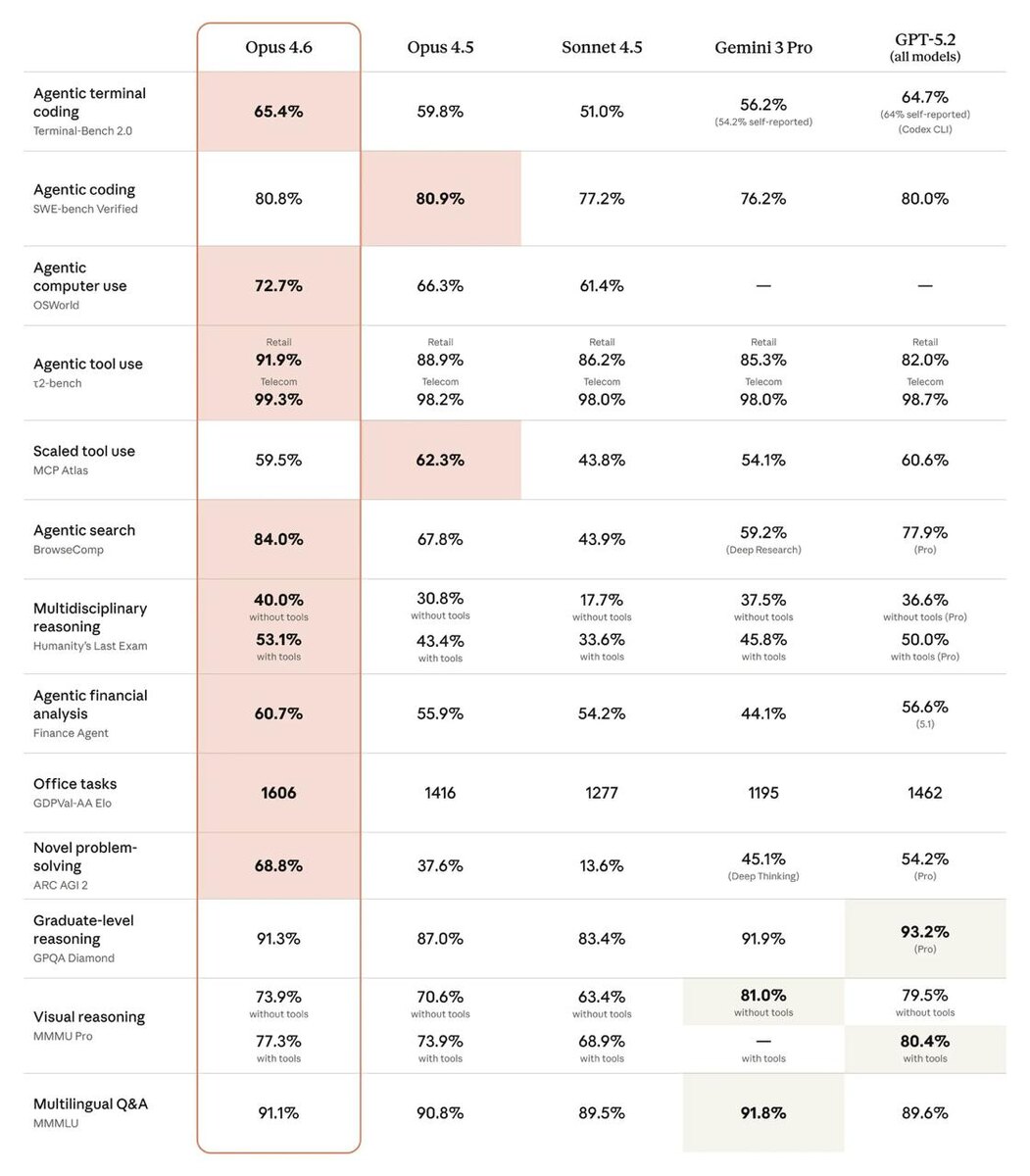
По бенчмаркам SWE-bench он обходит новый Opus: 77.3% против 65.4%. Забавно, что у старого Opus 4.5 этот бенчмарк на долю процента лучше, чем у нового 4.6. Имеет ли это сильное значение, не уверен 🤔
Я уже привык работать в Claude Code он мне почему-то нравится больше, чем GPT. Буду тестировать оба — посмотрим как покажут себя на реальных задачах, а не в тестах.