
Личные границы в эпоху AI — это контроль над тем, какие данные вы отдаете алгоритмам и что они могут о вас предсказать. Это не про паранойю, а про то, чтобы вы решали, где вы человек, а где просто набор личных данных.
Ты листаешь ленту, шутишь в чате, загружаешь новое селфи. Кажется, что это просто вечный поток мелочей, а не личные данные, за которые кто-то будет бороться.
На самом деле где-то рядом уже живет твой цифровой двойник. Он знает, когда ты сорвешь дедлайн, сколько раз в год меняешь работу и с кем расстанешься следующим. В тексте ниже разберем, как работает эта кухня, как использовать AI и Make.com в свою пользу и как превратиться из сырья для моделей в оператора своих данных.
6 шагов, чтобы не превратиться в набор данных
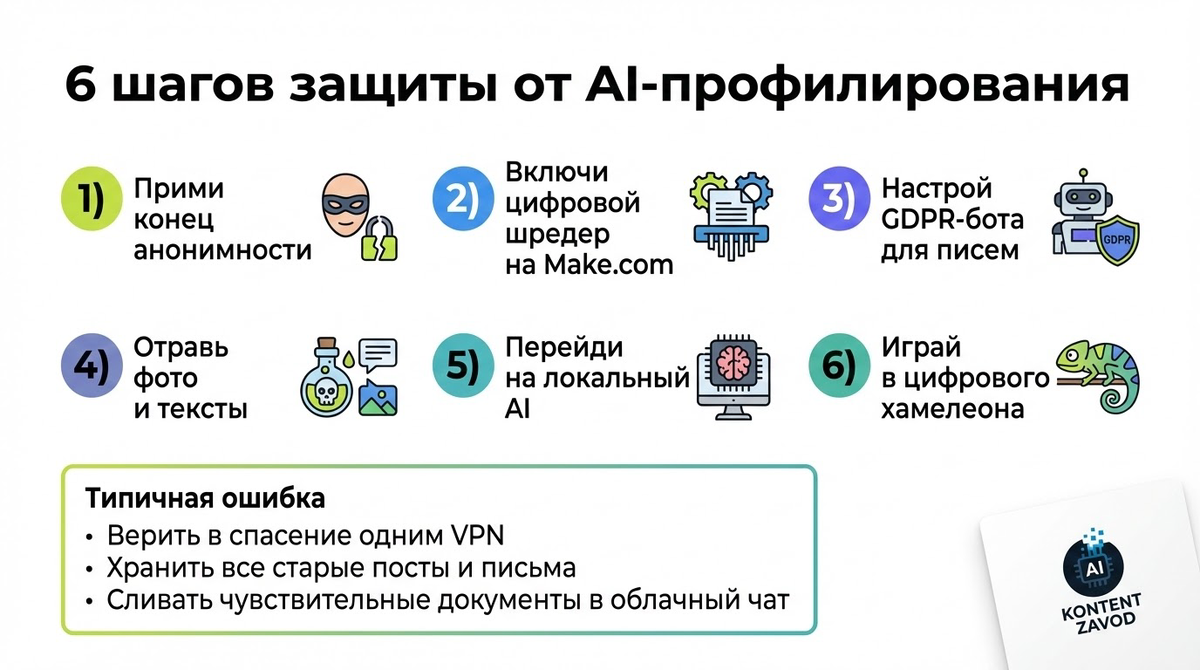
Шаг 1. Прими, что анонимности почти нет
Что делаем: перестаем считать, что ник, VPN и новый Telegram-аккаунт спасают от слежки. Понимаем, что AI собирает мозаику из стиля текста, времени активности и геолокаций.
Зачем: когда ты понимаешь, как тебя deanonymize через эффекты мозаики, проще осознанно решать, какие личные данные вообще не должны попадать наружу.
Типичная ошибка: писать одно и то же лицо и те же шутки в рабочем чате, на анонимном форуме и в комментариях под видео, а потом удивляться совпадениям.
Пример РФ: ты ругаешь начальство в «анонимном» телеграм-чате, но пишешь такими же оборотами, как в корпоративной переписке в почте на российском домене. Алгоритм легко находит совпадения по паттернам текста.
Шаг 2. Настрой «цифровой шредер» на Make.com
Что делаем: собираем сценарий, который раз в неделю проходит по твоим аккаунтам и убирает старый цифровой мусор — посты, твиты, письма без пометки «Важное».
Зачем: чем меньше старых следов в публичном доступе, тем меньше материала у моделей для обучения и точного профилирования.
Типичная ошибка: вспоминать про чистку только когда возникает скандал или утечка, и пытаться снести все руками за один вечер.
Пример РФ: на Make.com ставишь триггер по таймеру, модуль для Gmail и Telegram-бота, фильтр по письмам и сообщениям старше года без тега «Важное», и завершающий шаг — Delete Message через API.
Шаг 3. Подними GDPR-бота против спама сервисов
Что делаем: учим сценарий на Make.com с AI-модулем разбирать входящую почту «Добро пожаловать» и «Обновление политики конфиденциальности» и автоматически отправлять письма с запросом на удаление данных.
Зачем: многие сервисы в ЕС и рядом формально обязаны выполнить запрос на стирание, но почти никто не пишет им вручную. Автоматизация превращает твою пассивность в системную защиту.
Типичная ошибка: регистрироваться ради одной услуги, оставлять личный данный и годами терпеть рассылки, хотя оттуда можно было давно вычиститься.
Пример РФ: ты подписался на зарубежный сервис аналитики, который шлет письма по GDPR. Триггер в Make.com ловит такое письмо, AI-модуль достает адрес DPO, дальше модуль отправки почты шлет шаблон «прошу удалить мои личные данные».
Шаг 4. Отравь данные для чужих моделей
Что делаем: пропускаем свои фото через Nightshade, Glaze или Fawkes, а публичные тексты — через локальный AI-рерайтер, который меняет стиль, но сохраняет смысл.
Зачем: чтобы системы распознавания лиц и генеративные модели не могли нормально учиться на тебе и строить точный визуальный или стилистический профиль.
Типичная ошибка: выкладывать одно и то же селфи на все площадки, без обработки, с открытым лицом и фоном, который легко узнается.
Пример РФ: фотограф, который ведет портфолио в VK и на зарубежном фотостоке, прогоняет портреты через Fawkes перед загрузкой, чтобы его лицо не легло в базу распознавания.
Шаг 5. Перенеси личный мозг в локальный AI
Что делаем: все, что касается финансов, дневников, семейных документов и здоровья, открываем только в локальных моделях через LM Studio, Ollama или PrivateGPT.
Зачем: чтобы твой самый чувствительный дан личный не отправлялся на сервера корпораций и не использовался в очередной модели предиктивного профилирования.
Типичная ошибка: сливать в облачный чат историю болезней, договоры, переписку с юристами и ждать, что это навсегда останется тайной.
Пример РФ: предприниматель из Москвы качает Llama 3 в LM Studio и прогоняет через нее договор аренды и финансовый план, не поднимая ни один байт в облако.
Шаг 6. Включи режим цифрового хамелеона
Что делаем: осознанно ломаем рекламный профиль — периодически ищем странные товары, подписываемся на несвязанные группы, ставим расширения типа AdNauseam.
Зачем: предиктивное профилирование опирается на чистые паттерны. Чем больше шумовых действий, тем сложнее делать точные выводы о тебе.
Типичная ошибка: писать «я не хочу рекламу», но вести себя в онлайне как идеальная обучающая выборка для маркетолога.
Пример РФ: ты ставишь AdNauseam в браузер, он кликает рекламу на фоне, а ты пару раз в неделю грубишь алгоритмам — ищешь садовую технику, детские коляски и автозапчасти, хотя реально тебе нужен только новый микрофон.
Локальный AI против облачного: что безопаснее для личных данных
Кому эта стратегия реально сэкономит нервы и деньги
Подход с цифровым шредером, зашумлением и локальным AI особенно полезен тем, у кого личный данный напрямую конвертируется в деньги или репутацию.
- Фрилансеры и эксперты, которые ведут личные блоги, продают консультации и не хотят, чтобы их стиль и кейсы бесконтрольно утекали в обучающие датасеты.
- Основатели и топы небольших компаний в РФ, которые обсуждают финансы и стратегию в почте и мессенджерах и не могут позволить себе утечку этих переписок.
- Креаторы контента: фотографы, иллюстраторы, копирайтеры, чьи работы легко превратить в датасет без вопроса и оплаты.
- Специалисты по безопасности и юристы, которые хранят у себя чужой личный данный и хотят, чтобы за каждую утечку не расплачивались своей карьерой.
- Любой человек, у которого за спиной есть хотя бы один неприятный скандал, связанный с прошлой перепиской, старым постом или фотографией.
Частые вопросы
Если я все сотру, AI про меня забудет?
Нет, уже обученные модели ты не очистишь, но можешь резко сократить объем новых данных, которые попадут в следующие версии и в системы предиктивного профилирования.
Обработка фото через Fawkes и Glaze не испортит кадр?
Эти инструменты вносят изменения так, чтобы человек разницы почти не видел, а вот модель распознавания лиц или генеративный AI начинали «спотыкаться».
Make.com безопасен для обработки личных данных?
Make.com — инструмент автоматизации, а не хранилище тайн. В сценариях, куда ты подключаешь почту и мессенджеры, лучше не тянуть лишний личный данный и четко ограничивать доступ по API.
Локальные модели слабее облачных, есть смысл мучиться?
Для обработки документов, поиска по файлам и базового рерайта локальных моделей уже достаточно. Главное, что твои личные данные никуда не улетают.
Цифровой шум и хаотичный серфинг не забанят меня?
Если не устраивать деструктивных атак, а просто расширять профиль странными интересами и использовать AdNauseam, ты остаешься в серой зоне, а не в зоне нарушений.
Есть ли смысл бороться, если анонимности нет?
Смысл есть: ты не спрячешься полностью, но можешь управлять глубиной профиля, снижать точность предсказаний и решать, какие личные данные вообще не покидут твои устройства.
Можно ли доверять GDPR-запросам через бота?
Бот всего лишь автоматизирует письмо. Работает равносильно тому, как если бы ты сам написал запрос на удаление данных, просто делает это вовремя и без человеческой лени.
Какой шаг для защиты личных данных ты внедришь первым — шредер, локальный AI или цифрового хамелеона? Напиши в комментариях и подпишись, если хочешь больше разборов по Make.com и AI без пляски вокруг хайпа.
#личныеданные, #AI, #автоматизация
AI kontent Zavod:
Связаться с Андреем
Email
Заказать Нейро-Завод
Нейросмех YouTube
Нейроновости ТГ
Нейрозвук ТГ
Нейрохолст ТГ