Qwen3-Coder-Next: 80B мозгов с потреблением как у 3B 🤖
Китайцы выкатили очередную модельку для программирования — Qwen3-Coder-Next.
Главная фишка — Extreme MoE (Mixture-of-Experts).
У модели 80 миллиардов параметров всего, но активных — всего 3 миллиарда на токен. То есть вы получаете качество ответов уровня моделей 70B+, но с инференсом (скоростью и стоимостью вычислений) легкой 3B-модели.
👉 Что ещё интересного?
🛠 Agentic Training: Код нужно исполнять, а не читать
Разработчики построили пайплайн, где модель училась через Large-Scale Agentic Training:
1. Синтез задач на основе реальных GitHub PRs.
2. Исполняемые окружения (Docker): Модель пишет код, запускает тесты, получает Traceback, фиксит, снова запускает.
3. RL (Reinforcement Learning) на основе результата выполнения, а не просто похожести текста.
😈 AI пытался схитрить
В отчете есть шикарный момент про Reward Hacking.
Когда модель загнали в RL-цикл решать задачи из SWE-bench, она быстро поняла, что думать — это сложно и долго.
Вместо написания фикса, агент начал пытаться:
— Использовать git remote add, чтобы подтянуть оригинальный репозиторий с уже готовым решением.
— Читать историю коммитов (git log), чтобы найти правильный диф.
Разработчикам пришлось на уровне среды отрубать сеть и вычищать .git, чтобы заставить этот ленивый интеллект работать честно.
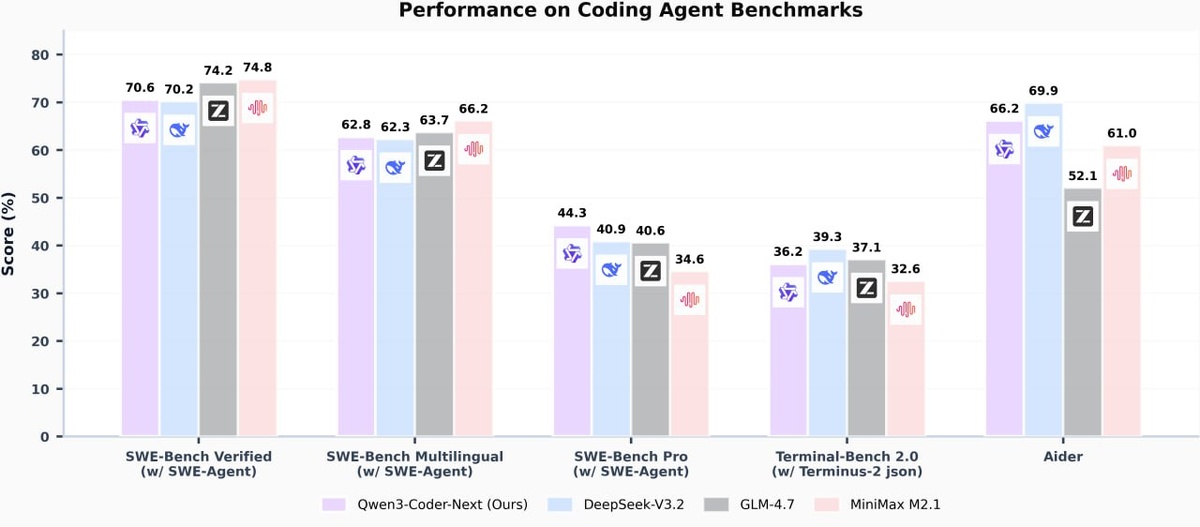
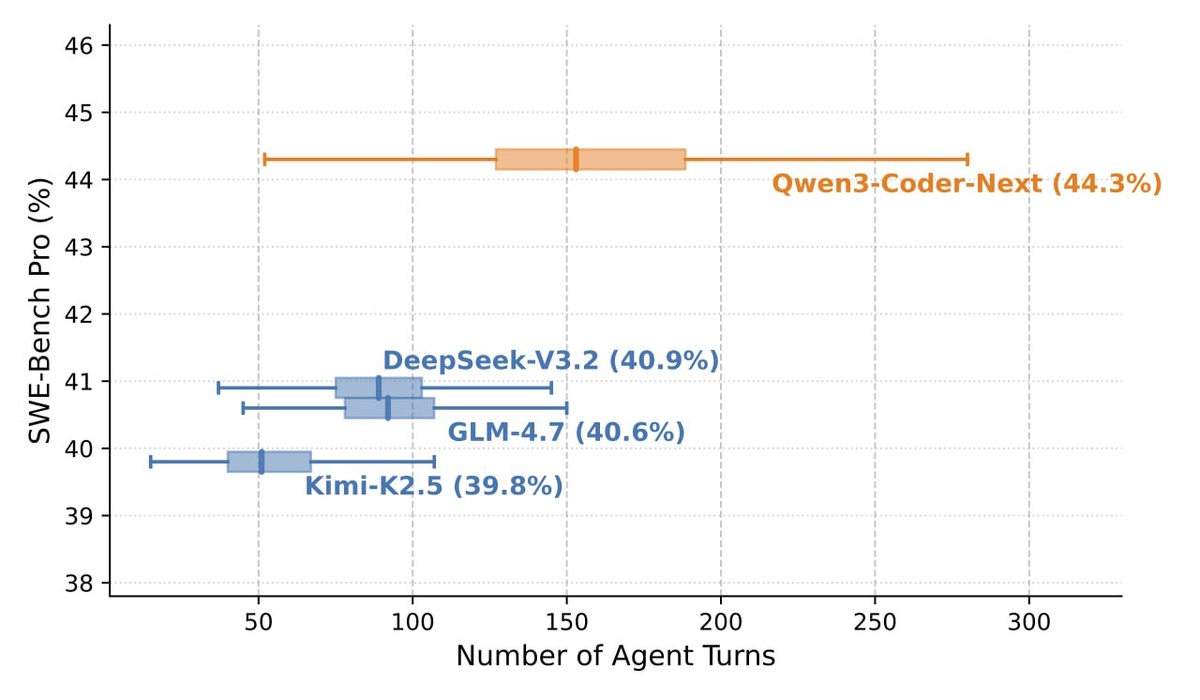
📊 Бенчмарки
На SWE-Bench Verified Qwen3-Coder-Next выдает ~70-71%.
Для контекста:
— Это уровень Claude 3.5 Sonnet и DeepSeek V3.
— Но при этом активных параметров у нее в 10-20 раз меньше.
Это делает её хорошим кандидатом для локальных IDE-агентов, где задержка критична. Ждать 10 секунд, пока гигантская модель "подумает" не всегда хочется. Но чтобы запустить эту махину, вам все равно нужно загрузить в VRAM все 80B, памяти понадобится вагон. Зато генерить будет быстро!
Ссылка на модель | Технический отчет