
AI-документооборот — это связка IDP, векторного поиска и больших языковых моделей, которая берет на себя рутину по поиску, резюме и маршрутизации документов. В итоге команда тратит меньше часов на разбор файлов и почти не возвращается к ручному вводу.
В типичном российском отделе продаж каждый день прилетает пачка договоров, счетов и приложений. Менеджеры скачивают файлы, открывают тяжёлые PDF, ищут глазами сроки и суммы, пересылают юристам и бухгалтерам, а через пару часов уже сложно понять, где чей документ.
Сегодня связка IDP + LLM + Make.com позволяет разбирать такие потоки почти полностью автоматически. Разберем, как настроить умный поиск, резюме и маршрутизацию документов так, чтобы сократить время обработки на десятки процентов, не ломая текущие процессы и не заваливая IT.
6 шагов к AI-документообороту на практике
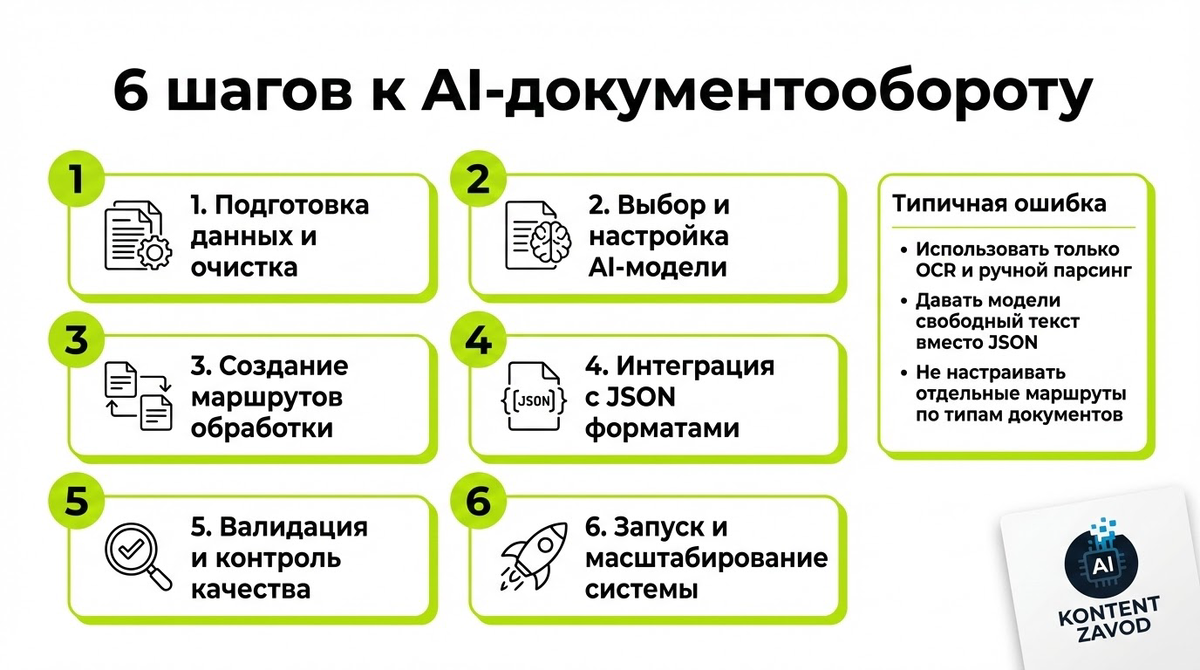
Шаг 1. Переходим от OCR к IDP для входящего потока
Что делаем: выбираем IDP-сервис или стек, который умеет не только распознавать текст, но и извлекать сущности — имена, даты, суммы, реквизиты — из сканов, фото и PDF.
Зачем: классический OCR дает просто текстовую кашу, а IDP сразу превращает документ в структурированные данные, с которыми можно работать в Make.com и CRM.
Типичная ошибка: пытаться натягивать простой OCR на сложные договоры и счета, а потом вручную парсить текст в Excel.
Мини-пример РФ: строительная компания получает акты и счета по WhatsApp и почте, прогоняет их через IDP, а на выходе сразу получает JSON с суммой, контрагентом и датой.
Шаг 2. Учим AI сортировать и переименовывать файлы
Что делаем: в Make.com настраиваем сценарий, который следит за папкой в Google Drive или Dropbox и при появлении нового файла отправляет его в модуль OpenAI или Anthropic.
Зачем: модель определяет тип документа, дату и контрагента и возвращает имя файла в формате «ГГГГ-ММ-ДД_Тип_Контрагент.pdf», а также JSON с полями.
Типичная ошибка: позволять модели отвечать свободным текстом, без схемы. Это ломает следующие модули.
Мини-пример РФ: небольшое агентство по недвижимости скидывает все сканы договоров аренды в одну папку, а Make.com автоматически сортирует и переименовывает файлы по контрагенту и дате.
Шаг 3. Добавляем умную маршрутизацию через Router
Что делаем: после анализа документа LLM отправляем результат в модуль Router в Make.com и строим ветки логики под разные типы документов.
Зачем: счет уходит в учетную систему и к бухгалтеру, договор — в папку Legal и на проверку юристу, претензия — в поддержку или юридический отдел.
Типичная ошибка: делать один общий сценарий «на все случаи», а не разводить маршруты, из-за чего сотрудники получают лишние уведомления.
Мини-пример РФ: торговая компания автоматически отправляет счета в бухгалтерию (уведомление в Slack), а договоры по крупным клиентам сразу превращает в задачи в Битрикс24 для юриста.
Шаг 4. Настраиваем саммари для CRM и почты
Что делаем: подключаем Make.com к почтовому ящику или CRM. При новом письме с вложением AI читает документ и формирует краткое резюме в три пункта: суть, сроки, сумма.
Зачем: менеджер видит содержание документа прямо в карточке сделки и в комментариях к письму, не открывая тяжелые PDF.
Типичная ошибка: делать слишком длинные саммари, которые никто не дочитывает, или не ограничивать формат и стиль ответа.
Мини-пример РФ: интегратор софта получает от клиентов ТЗ в виде многостраничных документов, а саммари автоматически подтягивается в Pipedrive или Битрикс24, помогая быстро оценить масштаб запроса.
Шаг 5. Включаем умный поиск по документам через векторную базу
Что делаем: загружаем договоры, регламенты и инструкции во векторное хранилище вроде Pinecone или Weaviate и подключаем его к LLM через Make.com или Assistant API.
Зачем: сотрудники ищут не по ключевым словам, а по смыслу. Запрос «договоры с высокими рисками» находит документы с крупными штрафами, даже без слова «риск».
Типичная ошибка: рассчитывать только на классический поиск по тексту и путаться в формулировках запросов.
Мини-пример РФ: HR-отдел крупной компании подключает регламенты к векторной базе, и бот в Telegram отвечает на вопросы «как оформить отпуск» или «как компенсируется командировка» с точными цитатами из PDF.
Шаг 6. Закладываем проверку и безопасность
Что делаем: добавляем этап AI-верификации — модель проверяет документы на возможные мошеннические признаки, несоответствия реквизитов и подозрительные изменения.
Зачем: это снижает риск фрода и ошибок, особенно в юридических и финансовых документах. При повышенных требованиях к конфиденциальности можно использовать локальные LLM, развернутые в периметре компании.
Типичная ошибка: доверять AI без финальной валидации человеком и не разделять потоки по уровню риска.
Мини-пример РФ: финансовый отдел холдинга прогоняет счета через AI-проверку на поддельные печати и расхождения сумм, а чувствительные договоры анализирует локальная модель на собственных серверах.
Сравнение подходов к работе с документами
Кому AI-документооборот даст максимум выгоды
AI-документооборот особенно полезен там, где много повторяющихся документов и длинных согласований.
- Юридические отделы и аутсорс-юристы, которые тонут в договорах, допсоглашениях и претензиях.
- Бухгалтерия и финансы, где каждый день проходят счета, акты и закрывающие документы.
- Отделы продаж и аккаунтинг, работающие с тендерами и крупными клиентами с пачкой PDF на каждую сделку.
- HR и административные службы с регламентами, приказами и заявлениями сотрудников.
- IT и цифровые команды, которым нужно быстро собрать RAG-бота по внутренней базе знаний без написания кода.
Частые вопросы
Это подходит только крупным компаниям?
Нет. No-code платформа вроде Make.com позволяет запускать сценарии даже небольшому бизнесу. По данным по рынку, проекты такого уровня обычно окупаются за 3-6 месяцев за счет сокращения ручного труда.
Насколько сильно AI снижает ошибки в документах?
При ручном вводе люди ошибаются примерно в 1-3% случаев. Настроенные AI-системы с этапом валидации снижают ошибку до менее 0.1%, особенно когда IDP и LLM работают в паре.
Куда девать наши текущие PDF и сканы?
Их можно прогнать через IDP, извлечь структуру и сохранить как структурированные записи. Для поиска стоит загрузить документы во векторную базу и подключить к ней LLM через RAG-сценарий.
Как решить вопрос конфиденциальности договоров?
Для юридических и финансовых документов можно использовать private/local LLM вроде Llama 3 или Mistral, развернутых на своих серверах. Так данные не покидают периметр, а AI все равно помогает с разбором.
Можно ли сделать чат-бота по внутренним регламентам без кода?
Да. Связка Make.com + векторная база (Pinecone или аналог) + OpenAI Assistant API позволяет собрать бота в Telegram или Slack, который ищет ответы именно в ваших PDF и выдает ссылки на исходные документы.
Что если AI неправильно определит тип документа?
Решается валидацией и логикой. В Make.com можно настроить проверочные ветки, логирование спорных случаев и ручное подтверждение для новых шаблонов документов, пока модель не обучится на вашей выборке.
Где изучить такие сценарии и примеры интеграций?
Хорошая отправная точка — Make.com Academy и Community, блоги OpenAI и Anthropic с примерами structured outputs, а также LangChain Blog и материалы DeepLearning.AI по RAG и системам работы с документами.
Какой документ у вас чаще всего вызывает хаос — счета, договоры или регламенты? Напишите, что хотите автоматизировать первым, и подпишитесь, чтобы не пропустить разбор готовых сценариев на Make.com.
#ai, #документооборот, #makecom
AI kontent Zavod:
Связаться с Андреем
Email
Заказать Нейро-Завод
Нейросмех YouTube
Нейроновости ТГ
Нейрозвук ТГ
Нейрохолст ТГ