Обновление re-bench: новые модели и свежие результаты
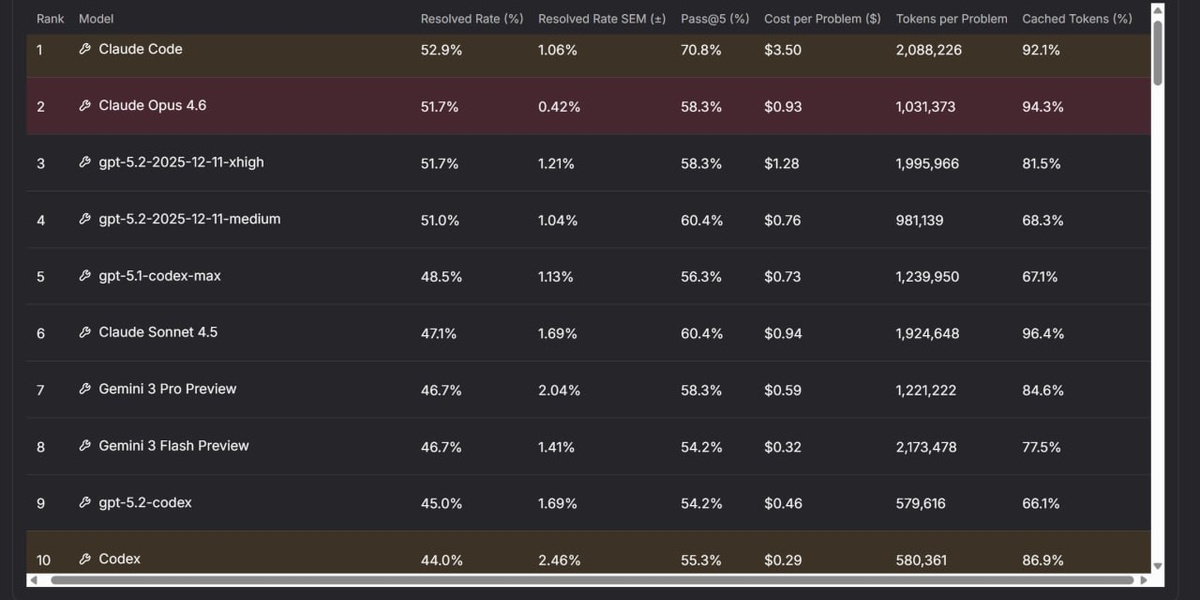
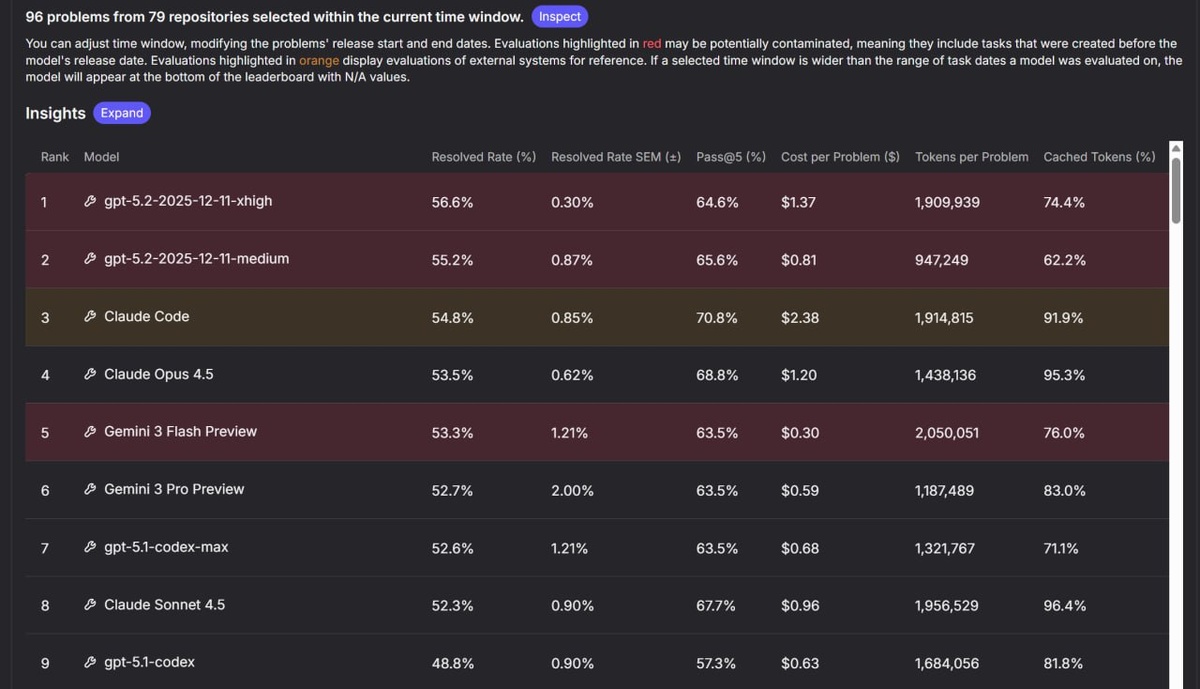
Команда nebius обновила re-bench, добавив новые модели и задачи за январь. В лидерах — Claude Opus 4.6, Claude Code (на той же архитектуре) и GPT-5.2. Для GPT-5.2 тестировали две настройки длины рассуждений, результаты совпали, но при средней длине расход токенов снижается вдвое.
Все четыре лидера показывают схожие результаты при первой попытке решения задачи. При пяти попытках и зачёте лучшего результата Claude Code выходит вперёд — 70,8% против ~60% у остальных.
Результаты GPT-5.2-Codex как отдельной модели и Codex как обёртки оказались низкими. Причины пока неясны.
• Весь опенсорс значительно уступает лидерам.
• Kimi K2.5 показал худшие результаты, чем Kimi K2 Thinking.
• Qwen3-Coder-Next (3 млрд параметров, Alibaba) опередил DeepSeek v3.2 и занял место между Minimax 2.5 и GLM-5.