
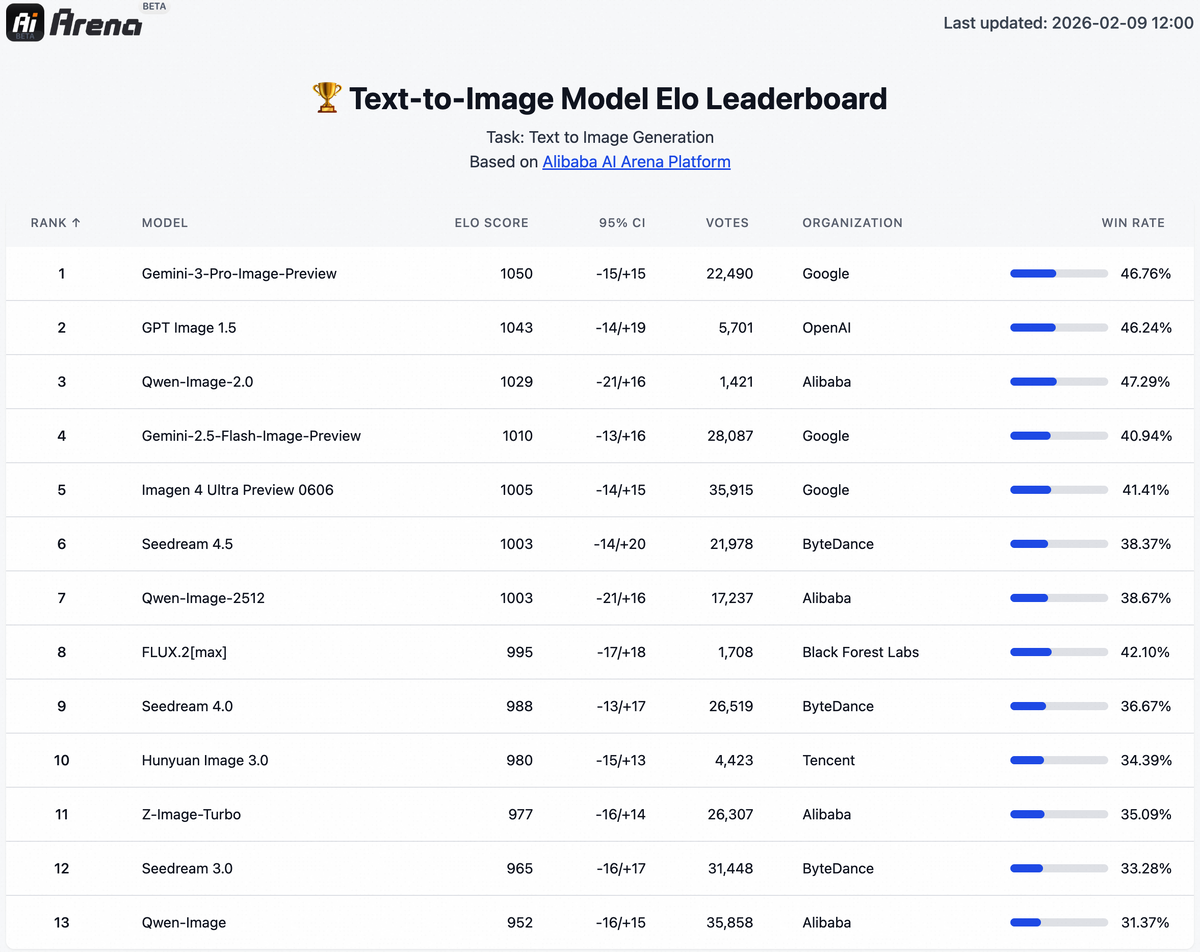
Команда Qwen не перестаёт удивлять — на днях они представили Qwen-Image-2.0, и это действительно интересная новинка. Речь идёт о базовой модели нового поколения, которая объединяет в себе сразу две ключевые функции: генерацию изображений с нуля и их редактирование. Причём всё это работает в рамках единой архитектуры, без необходимости переключаться между разными инструментами. Наконец-то можно не жонглировать десятком сервисов для одной задачи 😅
Новая модель заметно эволюционировала по сравнению с предыдущими версиями. Она стала компактнее, быстрее и при этом научилась понимать более сложные инструкции. Если раньше нейросети часто путались с текстом на изображениях, то Qwen-Image-2.0 справляется с этим на удивление хорошо. А ещё она нативно поддерживает разрешение 2K — это значит, что картинки получаются действительно качественными, без артефактов и размытия.
Что умеет новая модель
Разработчики из Qwen постарались сделать модель максимально универсальной. Qwen-Image-2.0 может работать с текстовыми описаниями длиной до 1000 токенов — это примерно 750-800 слов на русском языке. Звучит впечатляюще, правда? Теперь можно детально описать, что именно вы хотите увидеть на картинке, и модель постарается воплотить все ваши пожелания.
Вот основные возможности новинки:
- Генерация изображений по текстовому описанию с высокой детализацией
- Редактирование уже созданных картинок по новым инструкциям
- Создание визуальных материалов с текстом: постеры, презентации, инфографика
- Нативная поддержка разрешения 2048×2048 пикселей (2K)
- Фотореалистичная передача текстур и деталей
Лично меня больше всего радует, что модель понимает длинные промпты — можно наконец не втискивать всю идею в три предложения 😉
Инфографика и текст на изображениях
Одна из главных фишек Qwen-Image-2.0 — это корректная работа с текстом. Если вы когда-нибудь пытались сгенерировать картинку с надписями через обычные нейросети, то знаете, какая это боль. Буквы перепутаны, слова нечитаемые, шрифты кривые — знакомо?
С новой моделью от Qwen эта проблема наконец решена. Она умеет создавать:
- Презентационные слайды с заголовками и основным текстом
- Рекламные постеры с читаемыми надписями
- Инфографику с графиками, диаграммами и подписями
- Визитки и баннеры с правильным расположением текстовых блоков
Это открывает совершенно новые возможности для дизайнеров, маркетологов и контент-мейкеров. Теперь не нужно сначала генерировать фон, а потом мучительно добавлять текст в Photoshop или Figma. Можно описать желаемый результат — и получить готовый материал.
Качество изображений и разрешение
Qwen-Image-2.0 генерирует картинки в разрешении 2048×2048 пикселей нативно. Что это значит? Модель изначально обучена создавать изображения такого размера, а не растягивает маленькую картинку до больших размеров. Разница огромная — детализация, чёткость текстур и общее качество на порядок выше.
При высоком разрешении особенно заметна проработка мелких деталей. Текстуры тканей, отражения на поверхностях, тени и блики — всё это выглядит фотореалистично. Модель научилась передавать физические свойства материалов: металл действительно кажется холодным и блестящим, дерево — тёплым и фактурным, стекло — прозрачным с правильными преломлениями света.
Правда, для таких картинок понадобится приличное железо, но оно того стоит 😊
Редактирование изображений
Помимо генерации с нуля, Qwen-Image-2.0 умеет редактировать уже существующие изображения. Это отдельная суперсила модели — вы можете взять готовую картинку и попросить нейросеть внести изменения. Например:
- Изменить цвет объекта или фон
- Добавить новые элементы в композицию
- Удалить ненужные детали
- Изменить освещение или время суток
- Добавить или отредактировать текст
Причём всё это делается через текстовые команды, без необходимости разбираться в графических редакторах. Просто описываете, что хотите изменить — и модель применяет правки. Для многих задач это гораздо быстрее традиционного подхода с масками и слоями.
Производительность и оптимизация
Разработчики особо отметили, что новая версия стала легче и быстрее. Qwen-Image-2.0 требует меньше вычислительных ресурсов по сравнению с предшественниками, при этом скорость генерации выросла. Это важное достижение, потому что обычно улучшение качества идёт рука об руку с ростом требований к железу.
Модель оптимизирована так, чтобы работать эффективнее на различном оборудовании. Конечно, для максимального качества и скорости лучше иметь мощную видеокарту, но базовые возможности доступны и на более скромных конфигурациях. Не у всех же дома стоит RTX 5090, верно? 😅
Результаты тестирования
Команда Qwen провела слепые тесты на платформе AI Arena (честно говоря не нашёл там Qwen), где пользователи оценивают качество работы разных моделей, не зная их названий. Qwen-Image-2.0 показала отличные результаты в обеих категориях:
- Генерация изображений по текстовому описанию (text-to-image)
- Редактирование существующих изображений (image-to-image)
Модель обошла основных конкурентов, включая популярные решения от других команд. Особенно высоко пользователи оценили точность следования промпту и качество отображения текста. Это подтверждает, что разработчики действительно решили одну из главных проблем современных генеративных моделей.
Кому будет полезна модель
Qwen-Image-2.0 открывает новые возможности для разных специалистов:
- Дизайнеры и иллюстраторы могут быстро создавать концепты и визуализации идей
- Маркетологи получают инструмент для генерации рекламных материалов с текстом
- Контент-мейкеры могут создавать уникальные обложки, превью и иллюстрации
- Презентаторы смогут быстро собирать визуально привлекательные слайды
- Разработчики могут интегрировать модель в свои продукты через API
Универсальность — это главное преимущество новой модели. Вместо того чтобы использовать одну нейросеть для генерации, другую для редактирования и третью для работы с текстом, теперь всё можно делать в одном месте.
Доступность и использование
Пока что информации о коммерческом запуске немного, но команда Qwen традиционно предоставляет свои модели в открытом доступе. Скорее всего, Qwen-Image-2.0 будет доступна для скачивания и локального использования, а также через облачные сервисы с API.
Для тех, кто работает с нейросетями локально, это отличная новость. Можно будет настроить модель под свои задачи, дообучить на специфических данных или просто использовать без ограничений по количеству запросов.
Перспективы развития
Выход Qwen-Image-2.0 показывает, куда движется индустрия генеративных моделей. Тренд очевиден — унификация и универсальность. Вместо множества узкоспециализированных инструментов мы получаем комплексные решения, которые закрывают сразу несколько задач.
Следующим логичным шагом может стать интеграция с текстовыми моделями Qwen для создания мультимодальных систем. Представьте: вы описываете концепцию презентации, и система автоматически генерирует слайды с текстом и иллюстрациями, подбирая оптимальную композицию и стиль. Технологии для этого уже есть, осталось только объединить их в удобный продукт.
И да, модель уже сейчас способна создавать контент такого качества, что иногда сложно отличить от работы человека — прогресс впечатляет 🙂
Что это значит для индустрии
Появление таких моделей, как Qwen-Image-2.0, серьёзно меняет рынок визуального контента. Задачи, которые раньше требовали часов работы профессионального дизайнера, теперь можно решить за минуты. Это не значит, что дизайнеры станут не нужны — скорее, изменится характер их работы. Вместо рутинных операций они смогут больше времени уделять креативу и стратегическому планированию.
Для бизнеса это возможность значительно снизить затраты на создание визуального контента. Для творческих людей — шанс воплощать идеи без необходимости осваивать сложные графические редакторы. Для индустрии в целом — очередной шаг к демократизации технологий.
Qwen-Image-2.0 — это серьёзный шаг вперёд в развитии генеративных моделей. Унификация возможностей, качественная работа с текстом, высокое разрешение и хорошая производительность делают её привлекательным выбором для самых разных задач. Будет интересно посмотреть, как модель покажет себя в реальных проектах и какие новые возможности откроет для пользователей.
А вы уже пробовали работать с генеративными моделями для создания изображений? Какие задачи решаете с их помощью и какие функции считаете наиболее важными?
Каждый день я публикую свежие материалы, разборы и новости в Telegram. Если не хотите пропускать интересное — подписывайтесь и читайте в удобное время!