GLM-5: Open-source ответ Claude Opus 4.5 🤖
Z.ai вчера выкатили GLM-5 — флагманскую опенсорсную махину на 744 млрд параметров, заточенную под Agentic Engineering.
Что под капотом:
1. Архитектура MoE: Из 744B параметров активны только 40B. Это позволяет модели быть умнее, без долгого инференса.
2. DeepSeek Sparse Attention (DSA): Впервые интегрировали эту фичу для снижения стоимости при сохранении контекста в 200K токенов.
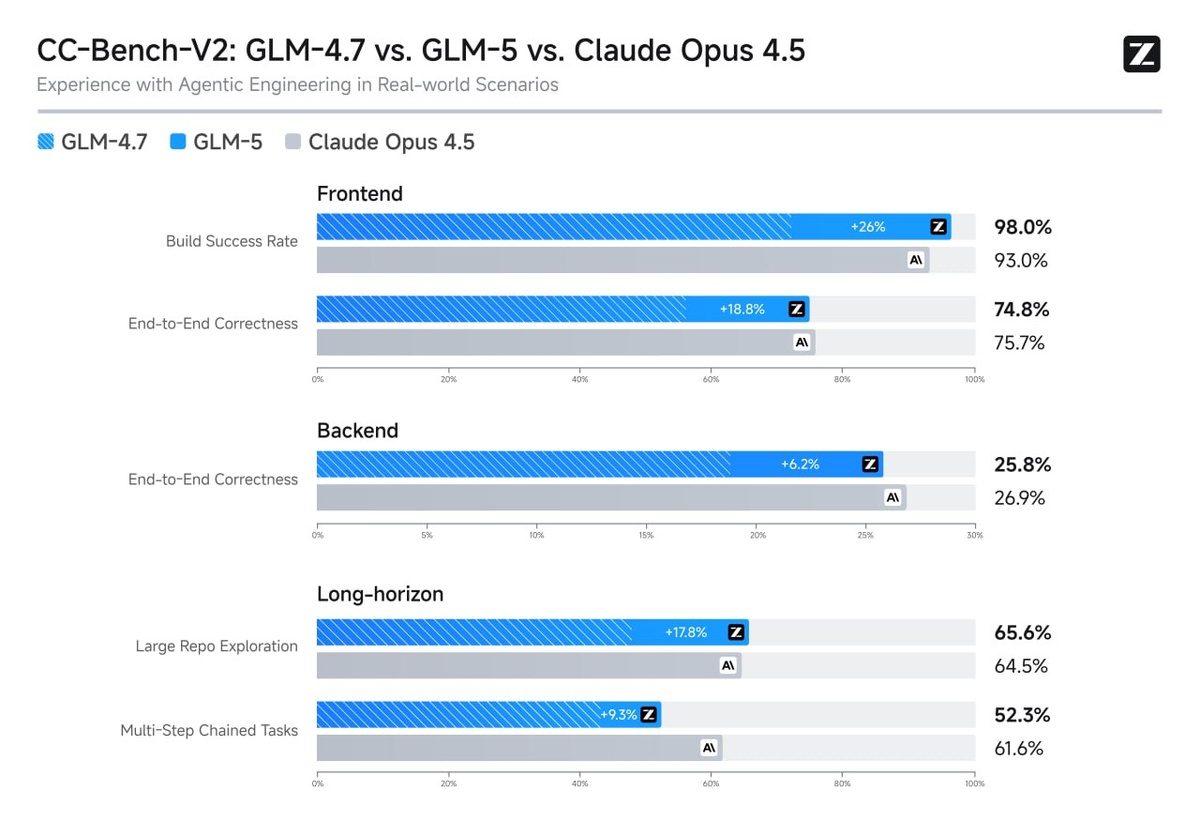
3. RL-фреймворк «Slime»: Разработали свою асинхронную инфраструктуру для Reinforcement Learning. Результат — модель лучше понимает долгосрочные цели.
4. Data Scale: Обучена на 28.5T токенов. Для сравнения, это на порядки больше, чем то, на чем тренировали большинство моделей прошлого года.
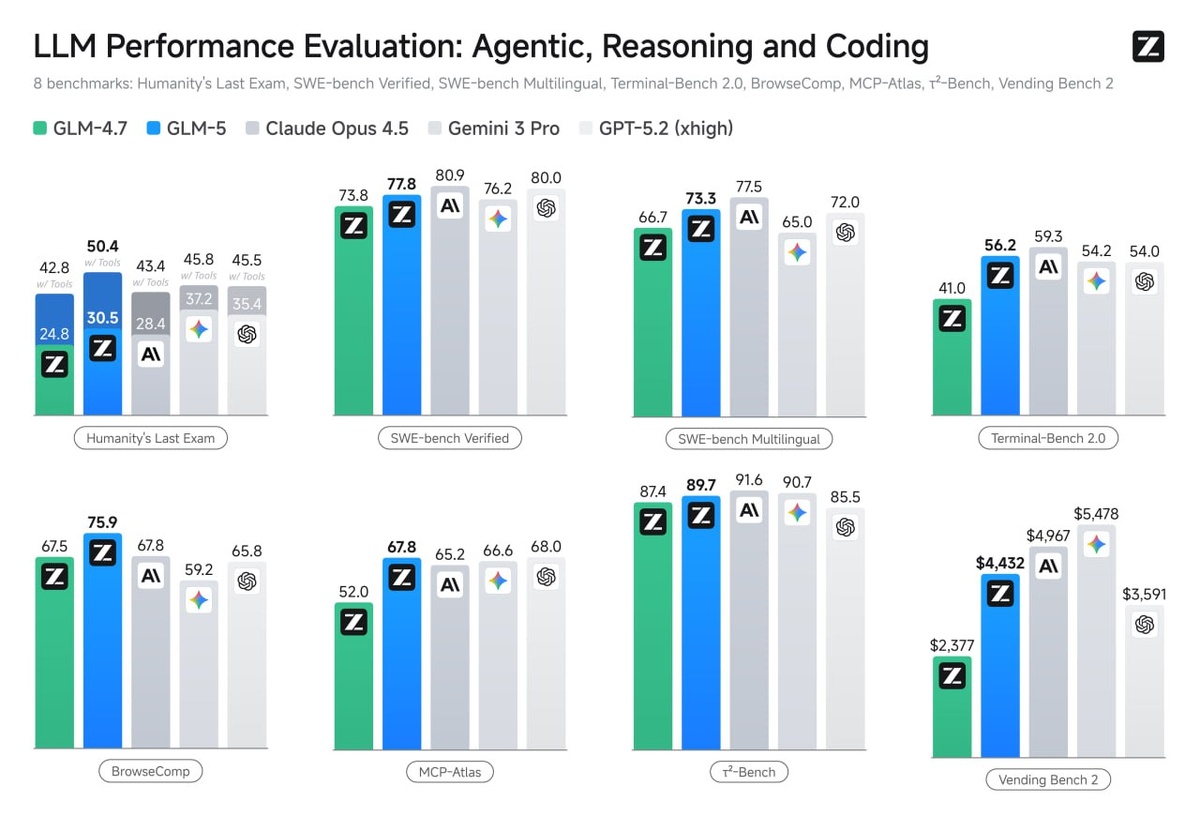
Бенчмарки:
🟣SWE-bench Verified: 77.8. Это очень серьезный результат, почти уровень Claude Opus 4.5.
🟣Terminal-Bench 2.0: 56.2. В задачах системного администрирования и работы через терминал обходит Gemini 3.0 Pro.
🟣Vending Bench 2: Первое место среди OS-моделей. Этот бенчмарк симулирует управление бизнесом в течение года — проверка на долгосрочное планирование и отсутствие «галлюцинаций» в логике.
Веса доступны на Hugging Face 👈🏻
Я сам периодически использую их Coding Plan, который мы обсуждали в Точке Сборки. Но пока новая модель доступна только по Max-подписке, скоро обещают добавить в Pro.