Alibaba открыла исходники Qwen3-ASR — передовых мультимодальных моделей распознавания речи с поддержкой 52 языков, высокой точностью и эффективностью. Решения подходят для исследований и промышленного внедрения в сфере искусственного интеллекта.
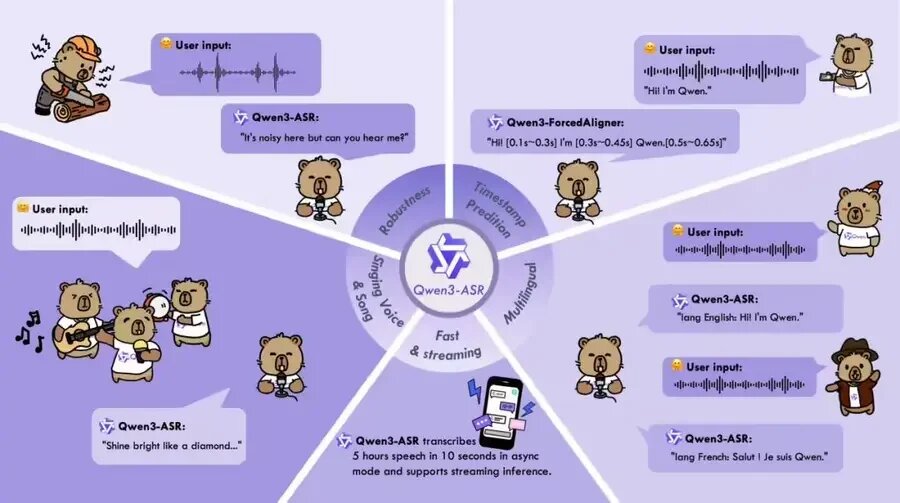
29 января команда Alibaba Qwen официально открыла исходные коды серии моделей Qwen3-ASR — мощного набора решений для распознавания речи в рамках экосистемы Qwen. В релиз вошли две полнофункциональные модели ASR — Qwen3-ASR-1.7B и Qwen3-ASR-0.6B, а также инновационная модель принудительного выравнивания речи Qwen3-ForcedAligner-0.6B. Вместе они обеспечивают распознавание речи и идентификацию языка более чем в 52 языках и диалектах.
По данным Alibaba, Qwen3-ASR использует новый предобученный аудиоэнкодер AuT в сочетании с мультимодальным фундаментом Qwen3-Omni, что обеспечивает высокую точность и стабильность распознавания. Модель на 1,7 млрд параметров демонстрирует передовые результаты (SOTA) в различных сценариях — от китайского и английского языков до речи с китайским акцентом и распознавания песен, сохраняя устойчивость в условиях шумной среды и сложных текстов.
Модель на 0,6 млрд параметров сочетает высокую производительность и эффективность: при высокой точности распознавания она поддерживает асинхронный вывод на 128 потоков с пропускной способностью до 2000×, обрабатывая более пяти часов аудио всего за 10 секунд.
Qwen3-ForcedAligner-0.6B — это модель предсказания временных меток на основе некаузального (NAR) вывода большой языковой модели, поддерживающая гибкое и точное принудительное выравнивание в 11 языках на произвольных позициях. Её точность по временным меткам превосходит традиционные решения вроде WhisperX и Nemo-Forced-Aligner, достигая эффективного фактора реального времени (RTF) 0,0089 при однопоточном выводе.
Команда Qwen заявила, что открытый релиз серии Qwen3-ASR призван ускорить исследования и инновации в области распознавания и понимания речи. Архитектуры моделей, веса и полноценная, удобная для пользователей инфраструктура вывода будут доступны в рамках открытого пакета.
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Pandaily