
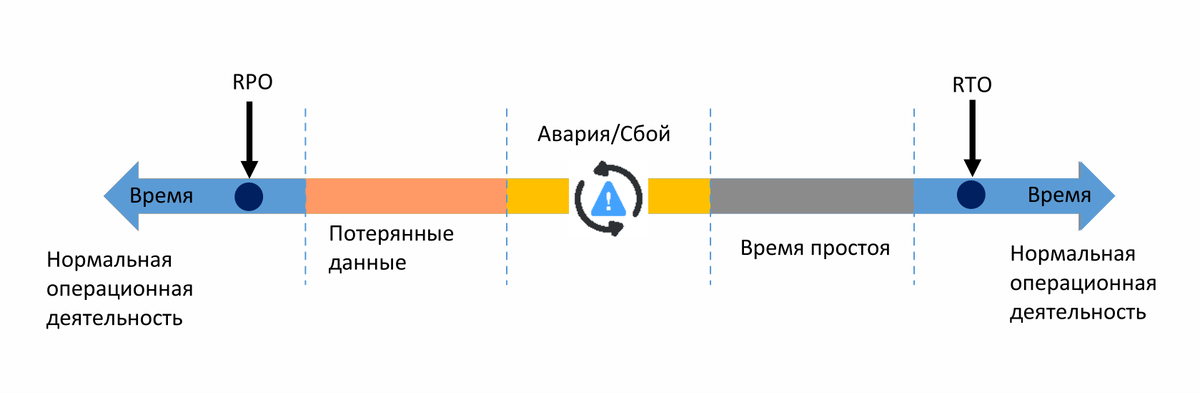
RPO и RTO являются ключевыми параметрами, которые позволяют заранее зафиксировать границы допустимого при любых сбоях: какую потерю данных бизнес ещё считает приемлемой и сколько времени сервисы могут находиться в простое. Именно от этих метрик отталкиваются при построении политики хранения, резервного копирования и аварийного восстановления, а также при оценке устойчивости инфраструктуры и способности компании продолжать работу в случае инцидентов.
Recovery Point Objective (RPO)
RPO — это метрика, которая показывает, какую потерю данных организация готова принять при аварии, выраженную во времени. Если RPO равен 6 часам, это означает, что после сбоя компания должна иметь возможность восстановиться так, чтобы потеря данных не превышала последние шесть часов. Всё, что было записано в систему раньше последней доступной точки восстановления, сохранится. Всё, что появилось после неё, потенциально будет потеряно.
Значения RPO у разных бизнес-систем в рамках одной компании могут очень сильно отличаться, поскольку у всех разная стоимость ошибки. Банки и платёжные системы обычно стремятся к минимальному RPO, так как они работают с деньгами, транзакциями и юридически значимыми данными. В таких системах даже 15 минут потери уже могут превратиться в серьёзную проблему. Но, например, внутренний портал компании по производству средств автоматизации может пережить более высокий RPO, потому что часть данных можно восстановить вручную.
Допустим, у компании с отделом продаж есть CRM, куда менеджеры вносят заявки клиентов, фиксируют звонки, создают сделки и прикрепляют документы. Пусть резервное копирование CRM выполняется каждые 24 часа, например, в 00:00. Каждая успешная копия создаёт точку восстановления, то есть конкретное состояние системы на определённый момент времени. В случае сбоя мы будем откатываться именно к одной из этих точек.
Предположим, сервер с CRM упал в 02:00 ночи. Последняя успешная точка восстановления у нас была в 00:00. Следовательно, потеря данных составит примерно 2 часа. Это будут заявки, звонки и изменения, которые произошли между полуночью и моментом сбоя. Если бы сбой произошёл буквально через пару минут после бэкапа, потерь почти не было бы. Если же сбой произошёл в 05:59, то потеря данных составила бы почти 6 часов. То есть фактическая потеря данных всегда находится где-то между нулём и значением RPO, и максимальная потеря в таком сценарии почти равна интервалу между двумя успешными бэкапами.
Отсюда следует простой вывод: если компания устанавливает RPO, равное 24 часам, то резервное копирование должно выполняться как минимум каждые 24 часа. При этом, чтобы нивелировать риски случайных сбоев заданий, бэкапы обычно делают чаще, чем значение RPO. Например, при целевом RPO 6 часов вполне логично запускать резервное копирование каждые 3 часа или даже каждый час, если инфраструктура позволяет. Это создаёт дополнительный запас прочности и снижает риск того, что в критический момент последняя успешная точка восстановления окажется слишком старой.
Также важно, что RPO обычно не бывает одинаковым для всех систем в рамках одной компании. Разные данные должны стоить разных ресурсов и денег при восстановлении. Если RPO на восстановление для процессинга банка обязано быть минимальным, то в свою очередь восстановление информации о принтере не выставляет высоких требований к СРК.
Recovery Time Objective (RTO)
RTO — это максимальный допустимый период времени, в течение которого ИТ-система, сервис или бизнес могут оставаться недоступными после сбоя или аварии, прежде чем это нанесет неприемлемый ущерб компании. Иными словами, RTO определяет, за какое максимальное время организация должна вернуть систему в рабочее состояние после инцидента. В отличие от RPO, который отвечает за допустимую потерю данных, RTO определяет допустимую длительность недоступности сервиса.
Например, представим, что у ветеринарной клиники по спасению животных RTO в IT-инфраструктуре равен 13 часам. Это означает, что при сбое сервера
с сайтом компании в 22:00 у ИТ-команды есть время максимум до 11:00 следующего дня, чтобы полностью восстановить работоспособность системы. Здесь важно правильно понимать момент начала отсчёта: время восстановления начинает отсчитываться с момента сбоя, а заканчивается не тогда, когда “проблема устранена технически”, а тогда, когда система возвращена бизнесу в рабочем и проверенном состоянии.
Соблюдение RTO неотъемлемо связано с четко описанным и проверенным регламентом резервного копирования, в котором зафиксированы
(и обязательно протестированы!) все необходимые процедуры, ответственные за процессы восстановления системы или инфраструктуры в целом. Плохо документированный процесс восстановления, медленное оповещение или отсутствие доступа к нужным ресурсам могут добавить дополнительные часы
к фактическому времени восстановления.
Наконец, даже если всё прошло успешно, и команда считает, что система восстановлена и работает, необходимо выделить время на проверку и финальную передачу сервиса в эксплуатацию. Восстановление включает не только устранение причины сбоя или поднятие данных из резервной копии, но также тестирование, проверку работоспособности и подтверждение того, что система возвращена бизнесу в корректном состоянии.
Может показаться, что строгое соблюдение оттестированных регламентов необходимо только в случае глобальных сбоев, а для восстановления конкретной системы в этом нет никакого смысла. Опытные администраторы СРК, нажав несколько кнопок в ПО СРК, могут восстановить что угодно. Однако на практике, для больших систем человеческий фактор может иметь критическое влияние на возможность восстановления и соблюдения RTO.
Финализируя приведенные примеры: если для системы установлен RTO в 13 часов, необходимо убедиться, что весь процесс целиком — включая обнаружение сбоя, диагностику, принятие решений, восстановление, тестирование и ввод в эксплуатацию — действительно укладывается в эти 13 часов.
Заключение
RPO и RTO решают разные задачи, хотя на практике всегда идут рядом. RPO относится к данным и отвечает на вопрос, насколько “свежую” информацию мы обязаны сохранить. Это допустимая потеря данных во времени: на какой момент назад мы можем откатиться и сколько изменений между последней точкой восстановления и аварией будет потеряно. RTO относится к сервису и времени простоя и отвечает на вопрос, как быстро система должна вернуться в рабочее состояние после инцидента. Проще говоря, RPO определяет глубину отката, а RTO — длительность недоступности.
Определение целевых RPO и RTO и регулярная проверка их соблюдения позволяют убедиться, что инфраструктура выдержит реальные инциденты. Только когда оба показателя согласованы с реальными возможностями, резервное копирование начинает работать как предсказуемый инструмент восстановления, а не как отчёт с зелёной галочкой.
"ДИАМАНТ" - простые в использовании решения, которые помогают хранить, управлять, защищать, архивировать и анализировать огромные объемы данных организациям любого масштаба: от малого бизнеса до крупных корпораций и государственных учреждений.