Статья рассказывает о новом крупном обновлении от Google DeepMind: у Gemini 3 Flash появилась способность Agentic Vision («агентная/интеллектуальная визуальная система»). Суть — модель перестаёт «одним взглядом угадывать, что на картинке», и начинает активно исследовать изображение, выполняя действия и проверяя гипотезы через исполнение кода (Python).
Автор подаёт это как сдвиг парадигмы: от «догадок» к «мини‑расследованию».
Что было раньше и что меняется
По словам продакт‑менеджера DeepMind Рохана Доши, традиционные модели при работе с изображением часто действуют статично: видят картинку один раз, и если деталь мелкая (например, серийный номер на микросхеме или размытый дорожный знак вдали), модель нередко вынуждена угадывать.
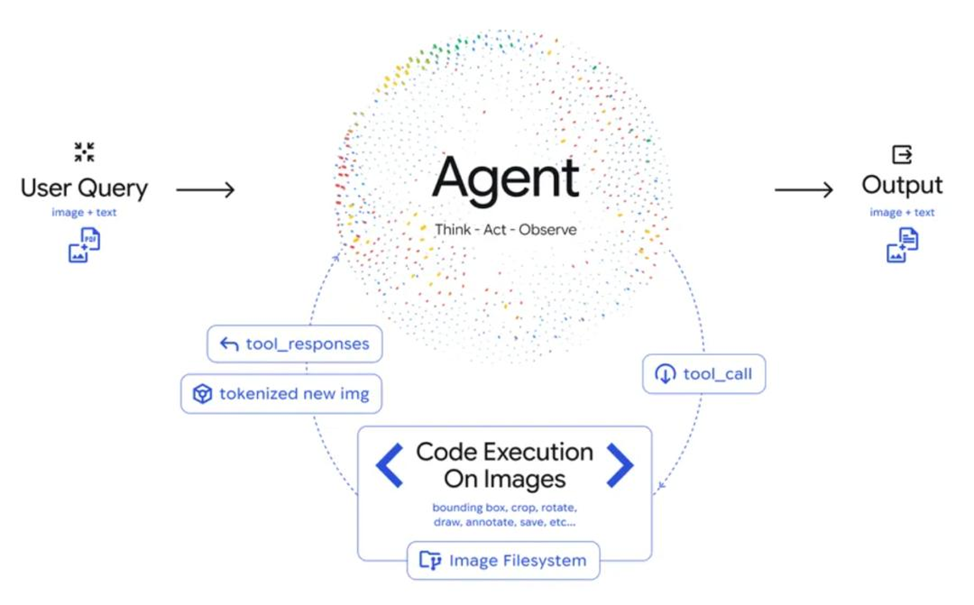
Agentic Vision вводит цикл Think–Act–Observe («подумай — сделай — посмотри результат»):
- Think (думай): модель анализирует запрос пользователя и исходное изображение, строит многошаговый план.
- Act (действуй): модель генерирует и исполняет Python‑код, чтобы манипулировать изображением (кадрировать, масштабировать, поворачивать, размечать) или анализировать его (считать объекты, вычислять, работать с bounding boxes и т. п.).
- Observe (наблюдай): преобразованное изображение добавляется в контекст, и модель продолжает рассуждение уже на «улучшенных данных» перед финальным ответом.
В статье утверждается, что это дало скачок 5–10% на ряде визуальных бенчмарков.
Практические примеры (как это выглядит в работе)
1) Масштабирование и инспекция мелких деталей
В демо говорится, что Gemini 3 Flash обучена «по умолчанию» приближать мелкие детали, когда это нужно.
Пример: сервис PlanCheckSolver.com (проверка строительных планов) включил у Gemini 3 Flash исполнение кода, чтобы модель итеративно «обходила» высокодетальные чертежи. Утверждается, что точность выросла на ~5%: модель пишет Python, вырезает нужные фрагменты (например, кромку крыши), анализирует их и «подкладывает» эти кропы обратно себе в контекст — так рассуждение «привязывается» к пикселям, а не к общим впечатлениям.
2) Аннотация изображений как «визуальная черновая бумага»
Agentic Vision позволяет не только описывать картинку, но и рисовать поверх неё, фиксируя ход рассуждения.
Пример: модель попросили посчитать пальцы/цифры на руке в интерфейсе приложения. Чтобы не ошибиться, она разметила каждый палец рамкой и подписью, тем самым превращая картинку в «визуальный черновик», где итоговый ответ основан на явно отмеченных объектах.
3) Визуальная математика и построение графиков
Обычные LLM часто «галлюцинируют» при многошаговой визуальной арифметике. Здесь логика такая: пусть модель распознаёт данные на картинке, но считает и строит графики в детерминированном Python‑окружении.
В демо: модель извлекает исходные числа, пишет код, нормализует значения относительно базового (SOTA=1.0) и строит столбчатую диаграмму Matplotlib. То есть «верификация выполнением» заменяет вероятностные догадки.
Как попробовать
В статье сказано, что Agentic Vision уже доступна:
- через Google AI Studio и Vertex AI в Gemini API,
- и начинает появляться в приложении Gemini (через выбор режима Thinking в выпадающем списке моделей).
Также приведён пример кода на Python, где включается инструмент code_execution, а затем модель получает изображение по URL и запрос «приблизь часть картинки и посчитай…».
«Пасхалка»: это ответ на DeepSeek‑OCR2?
Автор делает предположение, что релиз мог быть реакцией на недавний выход DeepSeek‑OCR2 (в тексте — «OCR 2.0»), и приводит три аргумента:
- Подозрительное совпадение по времени: DeepSeek публикует OCR2, а Google почти сразу показывает Agentic Vision.
- Разные, но конкурирующие философии:
- DeepSeek‑OCR2 — «внутренняя техника»: улучшить “как видеть” (в статье упоминается DeepEncoder V2, чтение «как человек» и экономия токенов).
- Google Agentic Vision — «внешние инструменты»: не только видеть, но и действовать/проверять через код.
- Борьба за определение “настоящего” computer vision: «лучше воспринимать» vs «уметь интерактивно исследовать и верифицировать».
Итог мысли статьи
Agentic Vision — это шаг к тому, чтобы модели перестали быть «картинко‑описателями» и превратились в инструментальных визуальных агентов, которые:
- сами решают, когда нужно увеличить/вырезать/разметить,
- могут проверять выводы кодом,
- и потому потенциально дают более надёжные ответы там, где раньше было много «угадывания».
Если хочешь, могу сделать ещё более «сжатый конспект на 10 строк» или выделить, какие прикладные сценарии (документы, планы, QA, аналитика) сильнее всего выигрывают от подхода Think‑Act‑Observe.
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru
Сайт https://www.smssystems.ru/razrabotka-ai/