Материал переведён с английского языка. Оригинал статьи по ссылке.
Революция в использовании искусственного интеллекта в проектировании уже стала реальностью — во многом благодаря доступным большим языковым моделям (Large Language Models, LLMs), таким как ChatGPT. По мере роста популярности этих моделей специалисты из самых разных отраслей ищут способы их практического применения. Для инженеров-конструкторов ключевая цель — интеграция ИИ в повседневные рабочие процессы. Расчёт строительных конструкций, учитывая колоссальные затраты времени, которые мы на него тратим, подходит лучше всего
В этом контексте важную роль играет способность ChatGPT обрабатывать и генерировать программный код. Это открывает возможность применения этой модели совместно с расчётными программами, которые предоставляют API для автоматизации части их функционала. Уникальность SOFiSTiK, однако, заключается в том, что построение расчётной модели в нём на 100% основано на коде с использованием собственного языка CADiNP. Более того, в отличие от других языков, применяемых в AEC-отрасли (например, IFC), CADiNP предоставляет такие инструменты, как группы, циклы и автоматическая генерация конечно-элементной сетки, что позволяет создавать эффективный код без повторений. Такой подход идеально соответствует способу генерации кода ChatGPT и открывает весьма перспективные возможности для автоматизации расчётов в SOFiSTiK.
Что получается на практике?
Задача оказывается далеко не такой простой, как может показаться на первый взгляд. Если напрямую попросить GPT-5 (наиболее продвинутую на данный момент публично доступную модель ChatGPT) сгенерировать простой файл Teddy для модели SOFiSTiK, модель действительно создаёт фрагмент кода, внешне напоминающий CADiNP (см. рисунок 1). Но при более внимательном анализе становится очевидно наличие множества ошибок: модуль AQUA закрыт некорректно, определения расчётных случаев (load cases) размещены не в том модуле, используются ключевые слова, которые вообще не существуют, и т. д.
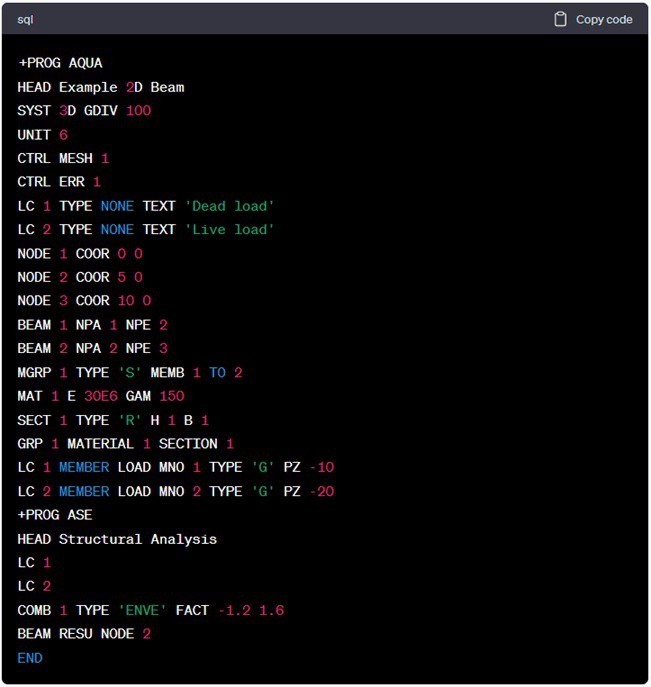
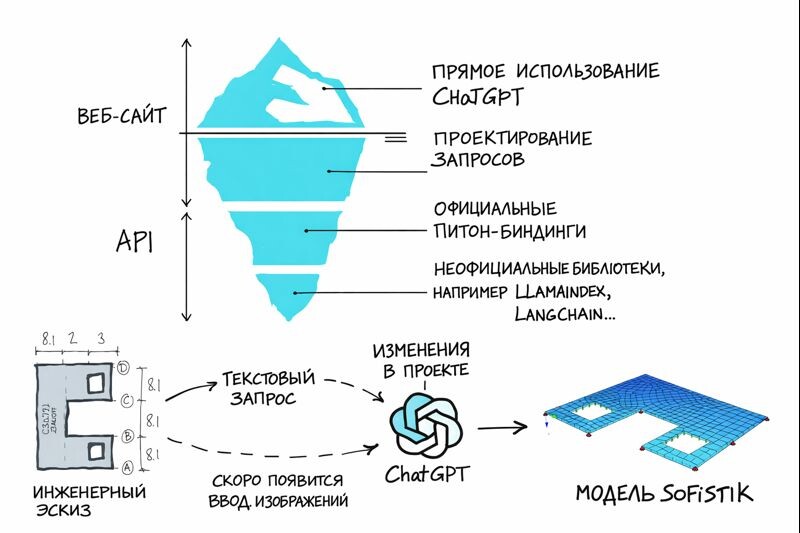
Несмотря на эту первую неудачную попытку связать ChatGPT и SOFiSTiK, необходимо подчеркнуть, что существуют и другие стратегии, позволяющие извлечь из ChatGPT значительно больше пользы. На рисунке 2 показаны различные «слои айсберга», отражающие потенциал ИИ. Чем глубже слой, тем мощнее подход, однако одновременно возрастает и его сложность.
Прямое использование ChatGPT:
Пользовательские сообщения или запросы (prompts), отправляемые в ChatGPT, представляют собой лишь вопросы без дополнительного контекста или пояснений. Большинство пользователей ограничиваются только поверхностным использованием потенциала модели.
Проектирование запросов:
Набор техник, направленных на оптимизацию формулировки запросов, чтобы ответы модели в большей степени соответствовали намерениям пользователя.
Официальные Python-биндинги:
Официальный Python-модуль позволяет взаимодействовать с ChatGPT не через публичный веб-интерфейс, а через API, который предоставляет больше возможностей и ресурсов.
Неофициальные библиотеки, такие как LlamaIndex и LangChain:
Существует всё больше сторонних библиотек, построенных поверх официальных биндингов ChatGPT. Две из наиболее популярных — LlamaIndex и LangChain. LlamaIndex позволяет связывать ChatGPT с пользовательскими документами, чтобы задавать вопросы по собственным данным. LangChain — это фреймворк для разработки ИИ-агентов на основе LLM, которые могут выполнять различные задачи по запросу пользователя: навигацию по веб-страницам, взаимодействие с другими API, работу с пользовательскими данными и т.д.
Следовательно, следующим логичным шагом для автоматизации расчётов конструкций с помощью ChatGPT и SOFiSTiK является prompt engineering. Этот подход может быть весьма успешным, что наглядно демонстрируется в YouTube-уроке SOFiSTiK and GPT-4 Tutorial: How to talk to your structural model. (Актуально для пятой и более новых моделей)
Ниже приведены рекомендации по получению эффективного и максимально безошибочного CADiNP-кода от ChatGPT:
- Каждая сессия общения с ChatGPT должна быть посвящена одной конкретной теме. Не следует в одном чате смешивать, например, рекомендации по ресторанам и запросы по SOFiSTiK. При каждом новом сообщении ChatGPT получает весь предыдущий диалог, поэтому смешение тем может его дезориентировать.
- Каждую сессию следует начинать с общей инструкции, в которой объясняется цель пользователя, структура последующих сообщений и роль, которую ChatGPT должен выполнять. В нашем случае ИИ должен выступать в роли ассистента, преобразующего запросы пользователя в CADiNP-код. Также рекомендуется просить ChatGPT отвечать кратко и сжато.
- Ключевая техника prompt engineering — предоставление ChatGPT достаточного количества примеров и документации по синтаксису SOFiSTiK, чтобы модель «поняла», как работает язык CADiNP. Каждый запрос, касающийся нового модуля или новой записи (record), с которой ChatGPT ещё не сталкивался, должен содержать соответствующую справочную информацию.
- Сложные инструкции целесообразно разбивать на несколько более простых запросов.
- По мере роста размера файла SOFiSTiK рекомендуется в новых сообщениях просить ChatGPT выводить неизменяемые части кода в виде общих комментариев. В противном случае ChatGPT может достичь лимита по количеству символов в ответе, и сгенерированный код окажется неполным.
- Если ChatGPT испытывает сложности с переводом сложной инструкции в CADiNP-код, возможным решением является просьба пояснить ход рассуждений в виде комментария рядом с каждой записью или строкой. Поскольку LLM обучены генерировать логически связанный текст, такой подход повышает вероятность получения корректного результата.
- Не следует ожидать от ChatGPT 100 % безошибочных ответов. Цель — эффективность, а не идеальная точность. Допустимо вручную исправлять мелкие ошибки или неточности, так как проверка результатов ChatGPT всё равно обязательна. При этом важно сообщать ChatGPT о внесённых вручную изменениях, чтобы он учитывал их в последующих ответах.
На рисунке 3 показан успешный ответ ChatGPT на запрос пользователя:
«Мы хотим снова обновить модель. Удалить колонны в узлах A1 и A2 и добавить стену, представленную линейной опорой, соединяющей эти узлы.»
Разумеется, этому диалогу предшествовало несколько сообщений, в которых ChatGPT была предоставлена обширная информация о синтаксисе CADiNP. В данном ответе можно выделить два существенных достижения.
- Во-первых, ChatGPT способен генерировать достаточно сложный CADiNP-код на основе простых текстовых инструкций.
- Во-вторых — и это, возможно, более важно — ChatGPT умеет переводить обычный разговорный язык в код SOFiSTiK.
Пользователь оперирует понятиями «конструктивные элементы» (колонны) и «узлы сетки A1 и A2», не ссылаясь на конкретные строки кода или ключевые слова. Таким образом, пользователь может буквально «разговаривать» с моделью SOFiSTiK на естественном языке.
Для достижения такого взаимодействия пользователь должен сначала объяснить ChatGPT взаимосвязь между реальными элементами здания и кодом SOFiSTiK, а также попросить записывать эту информацию в виде комментариев рядом с соответствующими записями (что также видно на рисунке 3).
Пример такого запроса:
«Запиши оси узла в комментарии рядом с определением узла. Координата X соответствует осям сетки A, B, C, D, а координата Y — осям сетки 1 и 2.»
Данный рабочий процесс обобщён на рисунке 4. Он начинается с инженерного эскиза, поскольку именно так инженеры обычно формулируют и проверяют свои идеи перед созданием расчётной модели. Далее эскиз или идея переводятся в текстовые запросы, понятные ChatGPT, с использованием описанных выше техник prompt engineering. В перспективе станет возможным передавать эскизы напрямую в ChatGPT, однако на данный момент OpenAI ещё не открыл эту возможность для внешних пользователей. После того как ChatGPT получает достаточную информацию о здании или модели, он может сгенерировать Teddy-файл SOFiSTiK и легко модифицировать его при изменениях проекта, описанных обычным текстом.
В рамках данного подхода мы используем искусственную нейронную сеть (Artificial Neural Network, ANN) ChatGPT для обобщения документации и примеров SOFiSTiK применительно к нашим конкретным задачам моделирования. Способность ANN обобщать новые данные на основе ограниченного обучающего набора напрямую связана с количеством параметров сети. Для примера: нейронная сеть, способная распознавать рукописные цифры, содержит около 55 000 параметров; сеть, играющая в игру Snake на сверхчеловеческом уровне, — около 30 000 параметров. В данной статье мы имеем дело с GPT-3.5, содержащей 175 миллиардов параметров, и с более продвинутой GPT-4, точное число параметров которой не раскрывается. Речь идёт о моделях, которые примерно на семь порядков величины превосходят пользовательские ANN. Обучение таких сетей требует чрезвычайно дорогого аппаратного обеспечения, и сам факт публичной доступности этих мощных LLM приводит к смене парадигмы во многих отраслях.
Основным недостатком данного подхода является необходимость для пользователей самостоятельно создавать примеры или шаблоны, на которых ChatGPT может обучаться для генерации безошибочного CADiNP-кода. Тем не менее этот процесс можно частично автоматизировать с использованием OpenAI API. В YouTube-уроке Introduction to the OpenAI API – Programming a Chatbot to generate SOFiSTiK models показан пример программирования ИИ-бота на Python. Результатом является диалоговый интерфейс, в котором пользователь указывает ключевое слово для загрузки соответствующего шаблона SOFiSTiK, который передаётся ChatGPT в фоновом режиме. Такой диалог показан на рисунке 5.
Следует отметить, что API предоставляет больше возможностей, чем официальный веб-сайт ChatGPT. Подобные ИИ-боты могут быть интегрированы в пользовательские веб-интерфейсы, что делает их доступными для удалённых пользователей. Дополнительным важным преимуществом API является конфиденциальная обработка сообщений, которые удаляются через 30 дней
В заключение можно сказать, что на стыке ChatGPT и SOFiSTiK всё ещё существует огромный, практически неизведанный потенциал. Рассмотренные стратегии лишь слегка приоткрывают возможности, которые появляются при совместном использовании этих мощных инструментов. Prompt engineering, работа через API и интеграция с неофициальными библиотеками уже демонстрируют впечатляющие результаты, однако стремительное развитие больших языковых моделей означает, что впереди нас ждёт ещё множество открытий.
Рисунок 6: Модель SOFiSTiK, на 100% сгенерированная на основе ответов ChatGPT.
Переходите на сайт SOFiSTiK и узнавайте больше!
Также можете посетить чат сообщества SOFiSTiK в Телеграме.