
NVIDIA представила PersonaPlex — открытую голосовую ИИ-модель, которая ломает привычную схему общения с виртуальными ассистентами. Вместо цепочки «распознавание → текст → синтез» система одновременно слушает и говорит, избавляясь от неестественных пауз и задержек. Кроме того, модель позволяет задавать роль и характер персонажа.
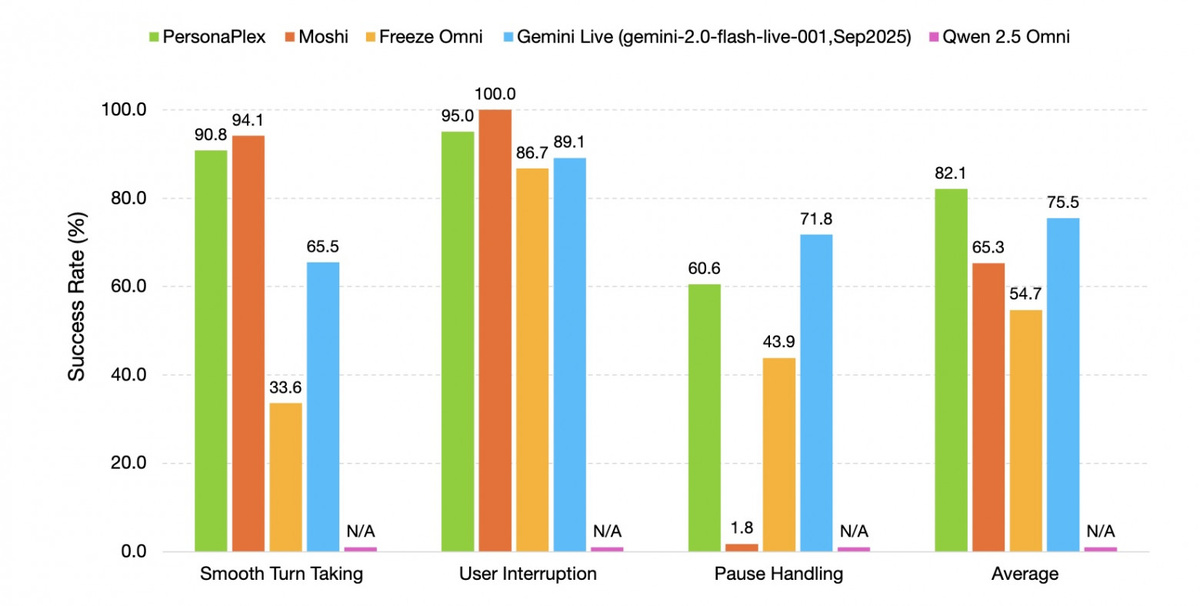
Ключевая особенность PersonaPlex — гибридная система подсказок. Пользователь задаёт короткий голосовой фрагмент, определяющий тембр и манеру речи, и текстовое описание роли: от банковского оператора до вымышленного персонажа. Во время разговора модель учитывает поведение собеседника, умеет вовремя делать паузы, перебивать, реагировать и мгновенно обновлять ответы. В тестах задержка при смене говорящего составила всего 0,07 секунды — против 1,3 секунды у Google Gemini Live.
Технически PersonaPlex основана на модели преобразования текста в речь Moshi и насчитывает 7 млрд параметров, поддерживая аудио на частоте 24 кГц. Для обучения использовались 1217 часов реальных диалогов и более 140 тысяч синтетических разговоров. При использовании восьми GPU A100 весь процесс занял всего 6 часов. Синтетические данные помогли прокачать следование инструкциям, а реальные записи — естественные речевые паттерны. В результате модель показала средний балл естественности диалога 3,90, обойдя Gemini Live, Qwen 2.5 Omni и Moshi.
Отдельно NVIDIA подчёркивает открытость проекта. Код и веса PersonaPlex уже доступны на Hugging Face и GitHub под лицензиями MIT и NVIDIA Open Model License, которые предусматривают коммерческое использование. Однако пока модель говорит только на английском.