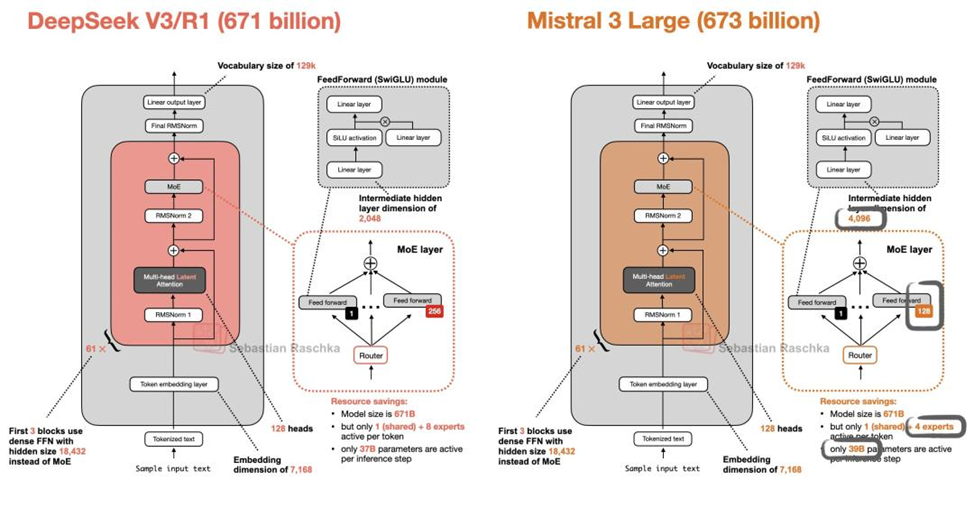
Заявление, сделанное генеральным директором европейского стартапа Mistral Артуром Меншем, стало настоящей бурей в AI‑сообществе. В интервью, отвечая на вопрос о конкуренции с китайскими открытыми моделями, он заявил:
«DeepSeek‑V3 построен на нашей архитектуре. Мы первыми выложили открытую MoE‑модель, и они создали свою версию на базе нашего подхода.»
Интернет взорвался мгновенно: от удивлённых «А?» до прямых обвинений в фантазиях. Для многих это прозвучало как попытка переписать историю задним числом. Ведь оба исследования — Mixtral и DeepSeek‑V3 — вышли с разницей всего в три дня, а архитектуры, если их внимательно сравнить, заметно отличаются. Более того, в конце 2025 года сообщество уже уличило Mistral 3 Large в использовании архитектуры DeepSeek‑V3, а не наоборот.
Что же произошло на самом деле?
MoE: общее направление, разные цели
И Mixtral, и DeepSeek‑V3 — это модели класса Sparse Mixture of Experts (SMoE), использующие выборку экспертов по Top‑K‑маршрутизации, вдохновлённую Google GShard. Обе решают одну задачу: повысить качество и уменьшить вычислительные затраты за счёт разреженной активации параметров.
Но подходы у команд принципиально различаются:
- Mixtral — это инженерный проект. Его цель: показать, что «крупная базовая модель + классический MoE» может превзойти большие плотные модели.
- DeepSeek‑V3 — это архитектурная и математическая инновация. Китайские исследователи попытались решить фундаментальные проблемы MoE:
• «засорение» экспертов общими задачами,
• дублирование знаний между экспертами,
• неэффективное распределение информации.
Формулы в их статьях прямо подтверждают различия: Mixtral реализует стандартные FFN‑эксперты, DeepSeek вводит совершенно иной механизм сегментации и раздельной маршрутизации.
Три ключевых различия DeepSeek‑V3 и Mixtral
- Гранулярность экспертов
- Mixtral использует классические «крупные эксперты» – каждый эксперт это полноценный блок FFN.
- DeepSeek делит экспертов на множество мелких модулей. Это повышает гибкость и разнообразие их комбинаций и улучшает обучение.
- Наличие общих (shared) экспертов
- В Mixtral все эксперты равны и конкурируют в Top‑K.
- В DeepSeek часть экспертов является «общими», активируется всегда и отвечает за базовые знания, а маршрутизируемые эксперты специализируются на узких задачах.
Это создаёт иерархию знаний, разгружая маршрутизатор и избегая смешения универсальной и специализированной информации.
- Маршрутизация и обучение
- Mixtral остаётся в рамках классической схемы GShard.
- DeepSeek радикально меняет механизм: перераспределяет нагрузку, избегает «повторного обучения» и улучшает стабильность MoE на больших масштабах.
Неудивительно, что сообщество отреагировало резко: говорить о том, что DeepSeek «построен на Mixtral», — значит игнорировать явные архитектурные новшества.
Ирония в том, что Mistral сам использовал DeepSeek‑подход
Самый пикантный момент — вскрытие архитектуры Mistral 3 Large в декабре 2025 года. Пользователи заметили, что модель использует структуру экспертов и маршрутизаторов, почти идентичную DeepSeek‑V3. Это уже обсуждалось в технических сообществах — и выглядело как явное заимствование идей китайской команды.
На фоне этого заявления Менша прозвучали особенно самоуверенно. Комментарии пользователей были жёсткими:
- «Началась перепись истории».
- «Это уже не тот Mistral, который мы любили за открытость».
- «Герой open‑source превратился в дракона, с которым сам боролся».
Что стоит за этим конфликтом?
На самом деле, спор — это симптом куда более крупного процесса: гонки за лидерство в открытых и эффективных базовых моделях.
DeepSeek, совершивший прорыв с MLA и ультраэффективными MoE‑архитектурами, стал новым центром притяжения внимания. Его подходы начали применять по всему миру, а само название — «DeepSeek‑style MoE» — уже стало термином.
Mistral, в свою очередь, стремится сохранить статус европейского лидера open‑source и воспринимает стремительный рост китайских моделей как вызов.
Заявление Менша — это часть борьбы за интеллектуальное первенство и право заявлять: «Мы были первыми».
Впереди — новая глава AI‑гонки
Скандалы в AI‑мире возникают не просто так: они сигнализируют о фазовом переходе. Мир переходит от эпохи огромных плотных моделей к эпохе разреженных архитектур, модульных экспертов и адаптивных маршрутизаторов.
А DeepSeek, по слухам, готовит новую модель к выпуску на китайский Новый год — и индустрия уже затаила дыхание.
Как бы ни развивалась полемика в соцсетях, ясно одно:
борьба за архитектуру будущего только начинается.
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru
Сайт https://www.smssystems.ru/razrabotka-ai/