За последние два года мы наблюдаем скачок в рассуждениях LLM‑моделей: DeepSeek‑R1, OpenAI o‑серия, QwQ‑32B — все они уверенно обходят обычные инструкционные модели в математике, логике, сложном планировании. На поверхности объяснение казалось простым: длиннее Chain‑of‑Thought → больше вычислений → лучше результат.
Но новое исследование Google, Чикагского университета и ряда институтов предлагает куда более глубокий ответ: сильные reasoning‑модели мыслят не «дольше», а «социальнее».
Внутри них возникают взаимодействующие роли, мини‑агенты, спорящие и договаривающиеся друг с другом — так называемая society of thought («общество мышления»).
Не одна мыслительная цепочка, а целая «команда» точек зрения
Анализируя внутренние треки рассуждений DeepSeek‑R1, QwQ‑32B и базовых моделей, исследователи увидели поразительное:
Во время решения задач модели запускают внутренние диалоги, где разные «персонажи» спорят, задают вопросы, выражают сомнения, предлагают альтернативы и объединяют противоречия.
Это не внешнее вмешательство — это спонтанно возникающая структура, которую отдельные токены и паттерны активаций мозга модели отражают как:
- вопросы → ответы
- смена точки зрения
- конфликт позиций
- примирение и объединение гипотез
- эмоциональные сигналы вроде удивления («Oh!», «Wait…»)
По сути, это внутренний дебат‑клуб, а не линейная логическая лента.
Почему это важно: «внутренняя дискуссия» улучшает точность даже без увеличения вычислений
Ключевой вывод экспериментов:
При одинаковой длине рассуждений, модели с выраженной диалоговой структурой дают значительно более точные ответы.
Это означает: прирост reasoning‑способностей не сводится к «больше шагов → лучше результат».
Google утверждает:
повышение разнообразия перспектив + внутренняя структура спора = эффективный поиск решения.
Это очень похоже на коллективный интеллект людей:
группы специалистов outperform одного суперэксперта, если внутри группы есть разнообразие ролей и механизмы конфликта/согласования.
DeepSeek‑R1 vs DeepSeek‑V3: почему R1 умнее
Исследование показывает разрыв даже между двумя моделями DeepSeek:
DeepSeek‑R1:
- больше переключает точки зрения
- больше создаёт внутренние конфликты
- чаще задаёт вопросы
- активнее объединяет альтернативы
- использует позитивные и негативные социальные роли
Это напоминает обсуждение между экспертами.
DeepSeek‑V3:
- ровный, однотонный, «монотонный» стиль
- нет смены позиции
- нет самокритики
- нет конфликта
- чистая линейная цепочка рассуждений
Это похоже на устное изложение, а не поиск.
«Эмоциональные роли» тоже помогают решать задачи
Используя классическую психологическую модель Bales IPA, исследователи нашли в reasoning‑следах DeepSeek‑R1 следующие социальные роли:
- запрашивание информации
- выдача рекомендации
- несогласие
- напоминание
- поддержка
- напряжение
- снятие напряжения
И что ещё удивительнее:
эти роли возникают в сбалансированных парах.
Это значит, что модель не просто выражает конфликт, а сама же его и сглаживает.
Эксперимент: усиливаем один «социальный признак» → точность удваивается
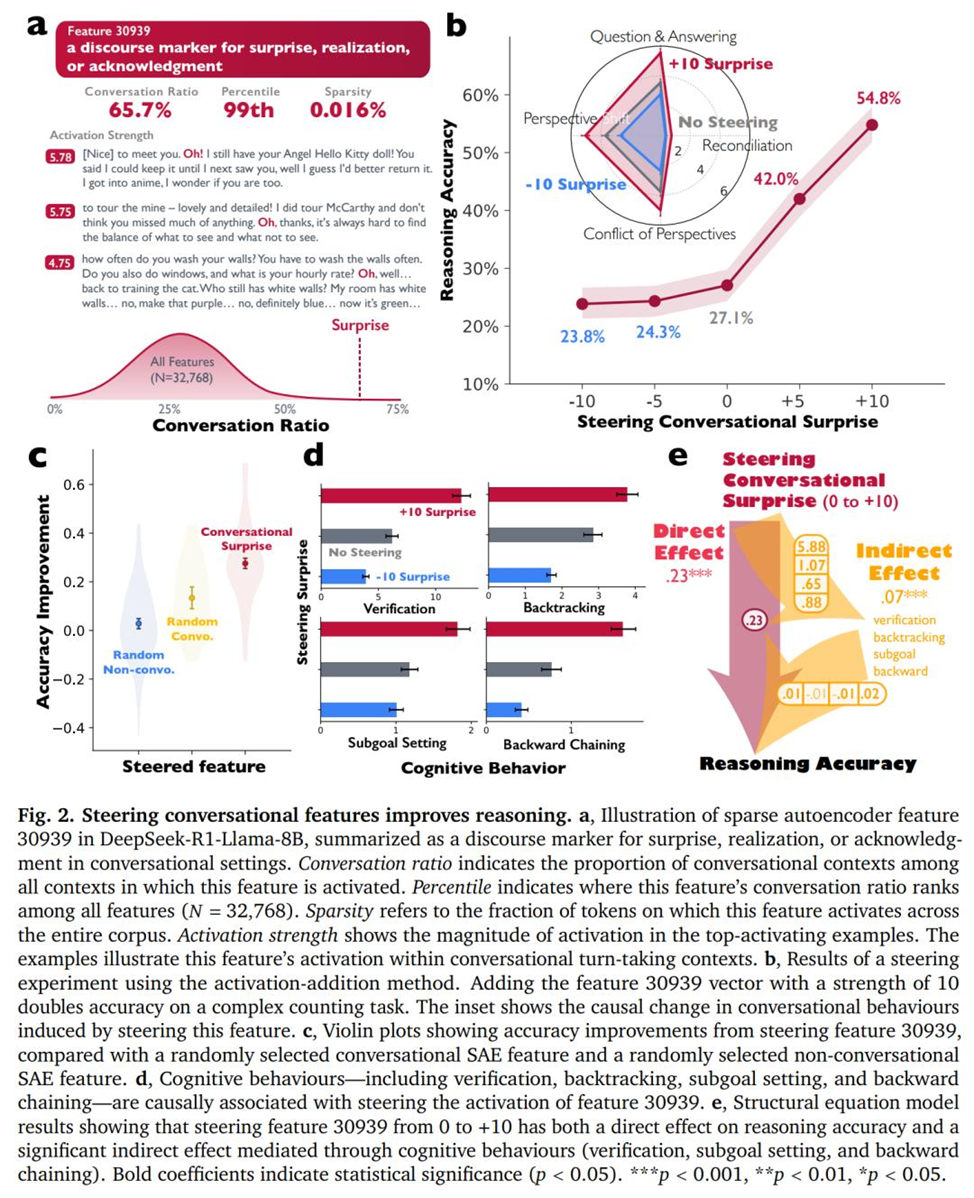
Учёные нашли конкретный интерпретируемый внутренний признак модели — Feature 30939, который отвечает за эмоции удивления/инсайта («Oh!», «Wait…»).
Когда они усилили его (+10):
- точность решения задач типа Countdown выросла с 27.1% → 54.8%
(рост в 2 раза!)
Когда приглушили (–10):
- точность упала до 23.8%
То есть сам факт появления удивления, сомнений, смены направления — улучшает поиск решения.
Модели обучаются «дебатировать» даже если им платят только за правильные ответы
Ещё один эксперимент: reinforcement learning, где единственная награда — правильный ответ.
Что происходит?
- модель сама начинает генерировать внутренние вопросы,
- сама начинает создавать альтернативные гипотезы,
- сама усиливает конфликт и последующее согласование.
То есть диалоговая структура возникает как оптимальная стратегия решения задач.
Ей не нужно объяснять, как размышлять — она сама до этого доходит.
Главный вывод Google: будущее AI — это «организация разума», а не просто масштаб
Исследователи предлагают новое направление:
Совместное моделирование множества внутренних агентов как систематический способ усиления reasoning‑способностей.
То есть:
- масштаб → даёт знания
- вычисления → дают возможность думать дольше
- структура внутреннего общения → даёт способность думать лучше
Это открывает путь к моделям, которые:
- имеют множество ролей (скептик, оптимист, математик, критик)
- ведут внутренние дебаты
- собирают коллективное решение
- становятся более надёжными в сложных задачах
Мы движемся к архитектуре, напоминающей не одиночный мозг, а команду специалистов внутри одной нейросети.
Итог: DeepSeek‑R1 умен не потому, что думает «дольше», а потому что думает «коллективно»
Новое исследование Google переворачивает наше понимание reasoning‑моделей:
- интеллект — это не длина CoT
- не количество токенов
- и даже не глубина слоёв
Интеллект — это структурированное разнообразие мышления.
DeepSeek‑R1 делает внутри себя то, что делает сильная исследовательская команда:
спрашивает, спорит, сомневается, меняет точку зрения, объединяет решения.
И, возможно, именно так мы впервые увидели рождение новой когнитивной формы —
искусственной коллективной интуиции.
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru
Сайт https://www.smssystems.ru/razrabotka-ai/