
Когда я начал работу над климатической моделью, был готов встретиться с "большими" данными. Но ожидания были далеки от реальности – мне достался набор на 2 терабайта! Я написал простой скрипт на NumPy, запустил его и отправился пить кофе. Вернувшись, увидел: ноутбук завис наглухо. После перезагрузки попробовал обработать кусочек поменьше — всё так же безуспешно. Обычные методы тут не работали. Поэкспериментировав с разными подходами, я наткнулся на библиотеку Zarr — она позволяет хранить массивы частями. Благодаря этому я смог обработать все 2 ТБ прямо на ноутбуке — и больше никаких зависаний! Вот что получилось:
Когда "большие данные" становятся огромной проблемой
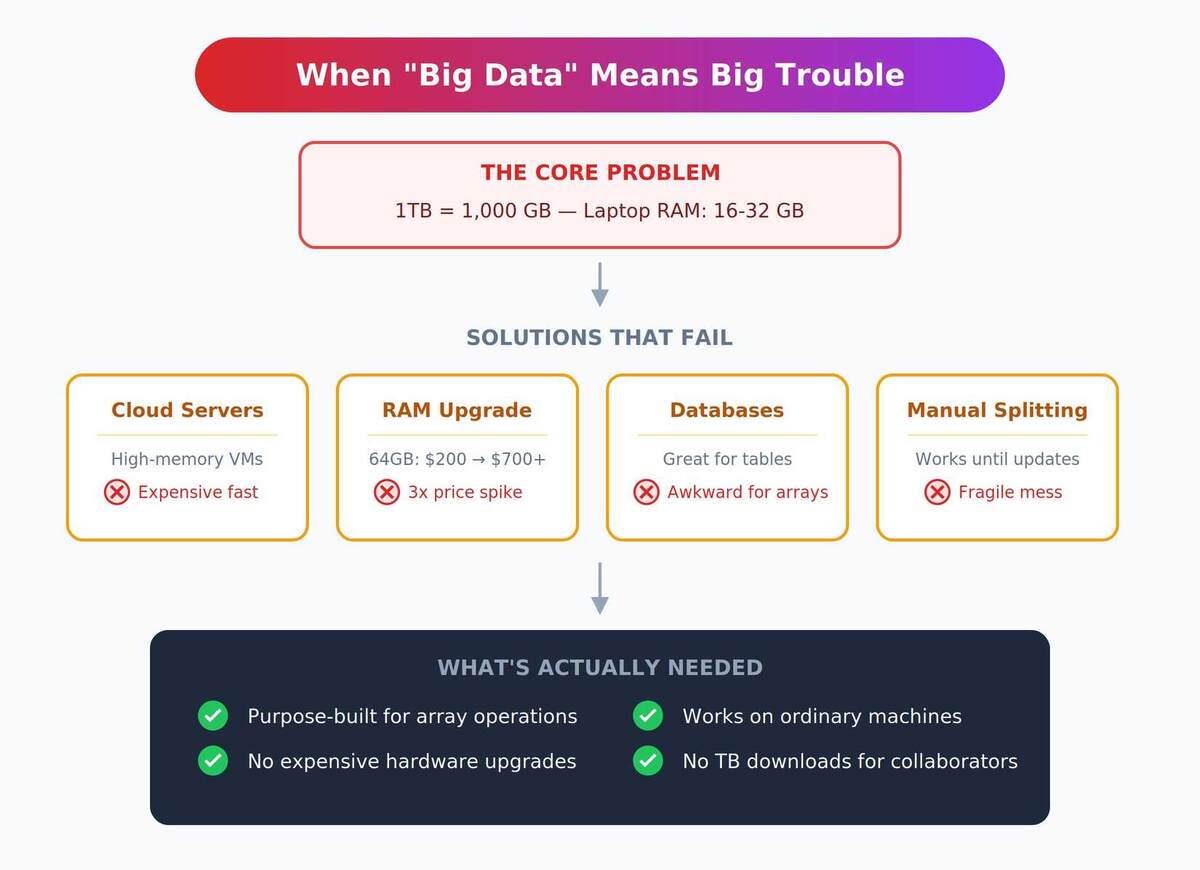
Работа с терабайтами — это совсем не "просто больше данных". Тут правила игры меняются полностью, и привычные трюки перестают действовать.
Почти у всех ноутбуков — 16–32 ГБ "оперативки". А терабайт — это тысяча гигабайт. Засунуть это целиком в память, хоть на Python, хоть на чём угодно, не получится. Даже если бы чудом влезло — обработка идёт вечность.
Есть и стандартные варианты: арендовать сервер с огромной памятью в облаке — но это быстро скажется на бюджете. Прокачать свой ноутбук — тоже не вариант: за последний год планки памяти выросли в цене в три раза из-за спроса от ИИ-ферм.
Плашка на 64 ГБ, которая стоила весной 20 тысяч, теперь стоит более 70. Базы данных классно работают с таблицами, но с многомерными массивами — одно мучение. Делить файлы вручную? Ловушка: одно обновление, и сразу начинается полный хаос.
Мне хотелось решения, заточенного именно под массивы, но без дорогого апгрейда. А ещё — чтобы коллеги могли работать с результатами на своих обычных ноутбуках, не качая огромные архивы себе на диск.
Встречайте Zarr — инструмент, который реально решает задачу "слишком больших данных"
Zarr — это Python-библиотека для хранения массивов частями ("чанками"). Всё предельно просто: ваш большой массив разбивается на блоки, каждый из которых хранится отдельно, сжимается отдельно и читается независимо. Работа с массивом Zarr почти не отличается от NumPy: знакомое индексирование, срезы — только в память попадают именно нужные куски.
Zarr умеет хранить массивы как на локальных дисках, так и в облачных (S3, Google Cloud, Azure). Это даёт возможность работать прямо из облака, не скачивая терабайты себе на компьютер. Для 2 ТБ это буквально спасение.
Библиотека с открытым исходным кодом, поддерживается сообществом SciPy, а интеграция с Python-экосистемой очень естественная. Если вы знакомы с NumPy — освоить Zarr будет просто.
Как Zarr избавил мои Python-скрипты от ошибок из-за нехватки памяти
Скрипты всё время падают при работе с большими данными? Теперь анализировать огромные массивы можно на обычном ноутбуке — и забыть о вылетах из-за памяти.
Zarr в деле: полный тест на реальных 2 ТБ климатических данных
Мой тестовый датасет — примерно 2 терабайта климатических симуляций, тысячи временных срезов. Мне нужно было посчитать средние показатели по регионам за несколько лет. Я настроил массив Zarr и долго экспериментировал с размером чанков: если сделать их слишком маленькими — слишком много файлов, слишком большими — снова не хватает памяти.
В итоге я подобрал размер чанка для моих задач: разделение по времени и географии. Код практически не отличался от NumPy-решения.
Первый полный запуск — и всё прошло как по маслу! Память стабильно держалась на уровне 4 ГБ, объём данных значения не имел: ни одного зависания, всё работало без глюков.
Освойте основы Python: пишем простой трекер расходов
Научитесь контролировать финансы и параллельно разберитесь с Python — проще, чем кажется!
Вот что реально круто в Zarr для работы с огромными массивами
Сжатие данных работает по умолчанию и очень эффективно: Zarr использует Blosc — и мой массив сжался с 2 ТБ до 400 ГБ! В научных задачах такие "превращения" — обычное дело. Частичное чтение данных реально ускоряет работу: легко получить значения за январь или по нужному региону — и не грузить весь массив. Раньше об этом можно было только мечтать.
Облака — тоже мастхэв: я просто перенёс массив на Google Cloud Storage, и коллеги смогли работать с ним напрямую в облаке — без гигабайтных закачек и лишних копий.
Параллельная запись — отдельный плюс: несколько процессов спокойно пишут свои чанки, никто никого не блокирует. То, что раньше выполнялось днями, теперь делается за часы. Я сменил подход: теперь всё, что обработал, сразу сохраняю — не держу в памяти до конца расчёта. Собирать массив по частям в Zarr — так же просто и надёжно, как и читать.
Где Zarr заставляет подумать: нюансы и тонкости работы
Но и без минусов не обошлось. Размер чанка и логику доступа к данным нужно продумывать: неудачный выбор может убить производительность. Если часто прыгаете по массиву хаотично — чтение отдельных частей замедляется. К новому стилю оптимизации придётся привыкнуть.
Подпишитесь на рассылку — получайте лайфхаки по работе с Zarr и массивами
Документация в целом хорошая, но многое раскидано по разным проектам: Zarr, Xarray (для подписей и координат), Dask (для параллельных вычислений). Сразу разобраться, что за что отвечает — непросто. На практике Zarr круто работает с Dask (для распараллеливания процессов) и Xarray (для ориентирования в данных и разбивки по координатам). Новичку такой зоопарк инструментов сначала кажется страшным. В моём случае всё упростил акцент на последовательной обработке и региональной агрегации. Для небольших задач NumPy по-прежнему удобнее.
Почему теперь я всегда выбираю Zarr для работы с большими массивами
Zarr — не единственный способ. HDF5 на рынке уже давно, TileDB решает похожие задачи по-своему, в климатологии популярен NetCDF4. Но именно Zarr меня зацепил: его легко интегрировать в Python-стек — Xarray добавляет "подписи" измерений, Dask даёт быстрый параллелизм. Всё работает вместе — никаких танцев с бубном.
Теперь обработка терабайтов — мой будний день. Если массив хотя бы чуть больше пары гигабайт — сразу использую Zarr: экономия диска и дружба с облаком — уже сильные причины. Современный научный Python-стек легко заменяет многие "большие" платформы. Hadoop, Spark и компания больше не нужны для массивов — даже очень больших.
Zarr реально спас мой проект — и не раз спасал мои нервы. То, что казалось невозможным, теперь просто часть рутины. Если вы работаете с данными побольше и вечной нехваткой памяти, обязательно попробуйте Zarr. Немного освоитесь — и увидите, что потраченные часы окупаются в разы. Особенно учитывая сегодняшние цены на апгрейд памяти.
Начните с официальной документации по Zarr: поэкспериментируйте с чанками на небольшом массиве. По мере роста задачи не придётся переписывать код с нуля — просто увеличивайте масштабы. Освоитесь — и вместе с Xarray + Dask перед вами откроется совершенно новый мир работы с данными.
Если вам понравилась эта статья, подпишитесь, чтобы не пропустить еще много полезных статей!
Премиум подписка - это доступ к эксклюзивным материалам, чтение канала без рекламы, возможность предлагать темы для статей и даже заказывать индивидуальные обзоры/исследования по своим запросам!Подробнее о том, какие преимущества вы получите с премиум подпиской, можно узнать здесь
Также подписывайтесь на нас в:
- Telegram: https://t.me/gergenshin
- Youtube: https://www.youtube.com/@gergenshin
- Яндекс Дзен: https://dzen.ru/gergen
- Официальный сайт: https://www-genshin.ru