Make сценарии — это последовательность автоматизированных действий, где информация передается между модулями в виде пакетов данных (бандлов). Прогон (execution) обеспечивает перемещение этих данных слева направо, позволяя интегрировать различные сервисы и API без написания программного кода.
Когда я впервые открыла редактор сценариев, это напоминало игру. Соединяешь кружочки, нажимаешь кнопку «Run», и по экрану бегут веселые пузырьки с данными. Кажется, магия. Но эйфория проходит ровно в тот момент, когда на простой пересылке лидов из Тильды в CRM улетает половина месячного лимита операций, а нужные данные теряются где-то посередине пути. Оказывается, за магией стоит сухая математика и жесткая логика. Если вы не понимаете, как именно платформа считает операции и обрабатывает ошибки, ваша автоматизация будет стоить неоправданно дорого.
Разберем анатомию прогона сценария до винтика. Я объясню логику потребления ресурсов и покажу, как настроить систему так, чтобы она работала стабильно, даже когда внешние сервисы падают.
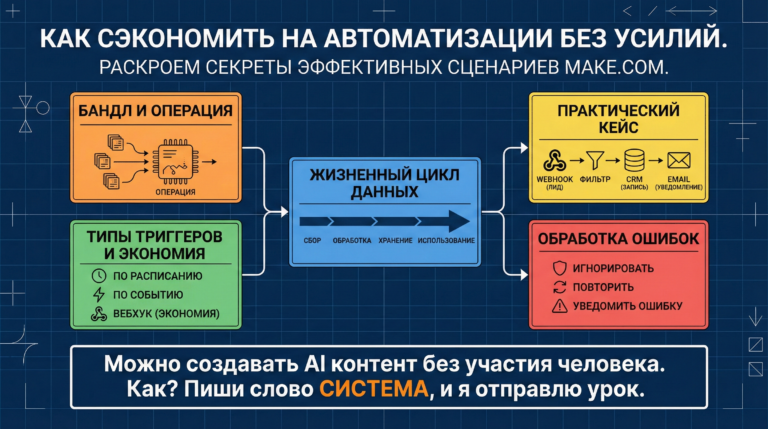
Базовая единица: Бандл и Операция
В основе любого make com сценария лежит понятие «Бандл» (Bundle). Это посылка с данными. Представьте конвейер. Если триггер находит 5 новых писем в почте, он создает не одну большую кучу данных, а 5 отдельных коробок-бандлов. И каждый следующий модуль в цепочке будет запускаться 5 раз — по одному разу для каждой коробки.
Это критически важно для понимания стоимости. Если у вас в цепочке 10 модулей, и пришло 5 писем, вы потратите не 10 операций, а 50 (5 писем × 10 модулей). Часто новички забывают об этом, и их make инструкция превращается в черную дыру для бюджета.
Типы триггеров и экономия
Не все стартовые модули работают одинаково. Выбор правильного типа триггера — первый шаг к оптимизации расходов.
Тип триггера Как работает Расход операций Polling (Опрос) Стучится в сервис по расписанию (раз в 15 минут). Спрашивает: «Есть что новое?» Тратит 1 операцию на проверку, даже если данных нет (пустой прогон). Instant (Webhook) Ждет, пока сервис сам пришлет данные. 0 операций на ожидание. Срабатывает только по факту получения данных.
Если есть возможность, всегда выбирайте Instant триггеры (Webhook). Это база любой грамотной архитектуры.
Жизненный цикл данных: только вперед
Данные в сценарии текут строго слева направо, как река. Если модуль А получил имя клиента, модуль Б (следующий за ним) это имя увидит. Модуль В тоже увидит данные и из А, и из Б.
Но обратного хода нет. Модуль А никогда не узнает, что произошло в модуле В. Если вам нужно вернуть данные «назад», придется использовать хитрости, например, обновление записи в базе данных (Data Store) или циклическую логику, но в стандартном потоке это дорога с односторонним движением.
Здесь важно упомянуть транзакционность. Make поддерживает принципы ACID. По умолчанию сценарий выполняется последовательно. Если на третьем шаге произошла фатальная ошибка, вся цепочка останавливается. Те данные, что успели пройти, считаются обработанными, а остальное зависает.
Хотите научится автоматизировать ведение соцсетей с помощью нейросетей и make.com? Подпишитесь на Telegram-канал, там я показываю «внутреннюю кухню» своих проектов.
Разбор практического кейса: Обработка лида
Давайте посмотрим на типичный сценарий, который часто собирают для малого бизнеса. Задача: получить заявку, записать ее, уведомить команду и отправить в CRM.
Цепочка: Webhook (Tilda/Typeform) -> Google Sheets (Лог) -> Slack (Уведомление) -> HubSpot (CRM).
- Вход (Webhook): Прилетает массив данных: Имя, Email, Телефон. Это наш бандл.
- Логирование (Google Sheets): Make добавляет строку в таблицу. Операция успешна.
- Уведомление (Slack): Менеджер получает сообщение «Новый лид!».
- CRM (HubSpot): И вот тут происходит сбой. Например, клиент указал телефон в неверном формате, и HubSpot вернул ошибку валидации.
Что произойдет без обработки ошибок? Сценарий упадет с ошибкой. В логах Make вы увидите красный кружок. Но самое неприятное — если вы используете итератор или обрабатываете несколько заявок сразу, все последующие заявки в этой очереди могут не обработаться.
Как это лечить (Error Handling)
Чтобы сценарий был надежным, мы должны предвидеть сбои. К модулю HubSpot нужно прикрепить директиву обработки ошибок (правой кнопкой мыши по модулю -> Add error handler).
- Resume (Возобновить): Если телефон кривой, мы можем подставить дефолтное значение (например, 000000) и продолжить сценарий. Запись в CRM создастся, менеджер потом поправит руками.
- Ignore (Игнорировать): Если ошибка не критична (например, дубль лида), мы просто помечаем шаг как выполненный и идем дальше.
- Break (Прервать): Используем для временных проблем (API отвалился). Make сохранит данные в «Incomplete Executions» и попробует повторить прогон позже.
Инструменты профи: DevTool и фильтры
Есть два правила, которые отличают профи от любителя. Первое — использование Make DevTool. Это расширение для браузера, которое позволяет заглянуть «под капот». Вы видите реальные JSON-заголовки, тело запроса и ответа. Без этого отлаживать сложные интеграции с API — это как чинить двигатель с завязанными глазами.
Второе правило — фильтрация перед действием. Представьте, что у вас после триггера стоит тяжелый модуль OpenAI, который анализирует текст письма. Каждый запуск стоит денег (и операций Make, и токенов API). Всегда ставьте фильтр перед вызовом нейросети. Отсекайте спам, автоответы и пустые письма на входе. Фильтр не тратит операции, но спасает ваш бюджет.
Сколько это стоит: коммерческий аспект
Make.com предлагает бесплатный тариф, который включает 1000 операций в месяц. Для тестов и простых задач этого хватит. Но серьезная автоматизация требует тарифа Core (от 9$ за 10 000 операций). Понимая логику прогона, которую мы разобрали выше, вы сможете уложить в эти 10 тысяч гораздо больше полезных действий, чем пользователь, который просто соединяет модули наугад.
Начать работу можно здесь: регистрация в Make.
Системный подход к автоматизации
Построение сценариев — это не просто навык соединения модулей. Это умение мыслить процессами. Когда вы автоматизируете создание контента (текст, картинки, видео), вы освобождаете десятки часов в неделю. Но техническая часть — это лишь половина успеха. Вторая половина — это контентная стратегия и правильные промпты для нейросетей.
В моем закрытом канале я даю уже готовые шаблоны (Blueprints), которые можно импортировать в свой аккаунт Make. Это экономит время на сборку и отладку. Вы получаете работающую систему, а не набор деталей.
Частые вопросы
Почему сценарий отключается сам по себе?
Это происходит, если возникает последовательность ошибок. Make имеет защитный механизм: если сценарий постоянно падает, платформа отключает его, чтобы не тратить ресурсы впустую. Проверьте логи и настройте Error Handler.
Что такое Incomplete Executions?
Это сохраненные данные неудачных прогонов. Если вы включили опцию хранения незавершенных исполнений в настройках сценария, вы сможете зайти в этот раздел, поправить ошибку и «допрогнать» данные вручную, не потеряв лид.
Как объединить ветки после роутера (Router)?
Роутер в Make умеет только разделять потоки, но не сводить их обратно. Лайфхак: создайте отдельный сценарий-вебхук или используйте Data Store для сбора результатов из разных веток, если вам нужна консолидация данных в конце.
Почему данные передаются медленно?
Проверьте размер файлов. Если вы гоняете через сценарий тяжелые бинарные данные (видео, большие архивы), это замедляет работу. Стандартный таймаут HTTP-запроса — около 40–60 секунд.
Вы можете ознакомиться с другими материалами ниже:
Instagram и Facebook принадлежат компании Meta, деятельность которой признана в России экстремистской и запрещена.