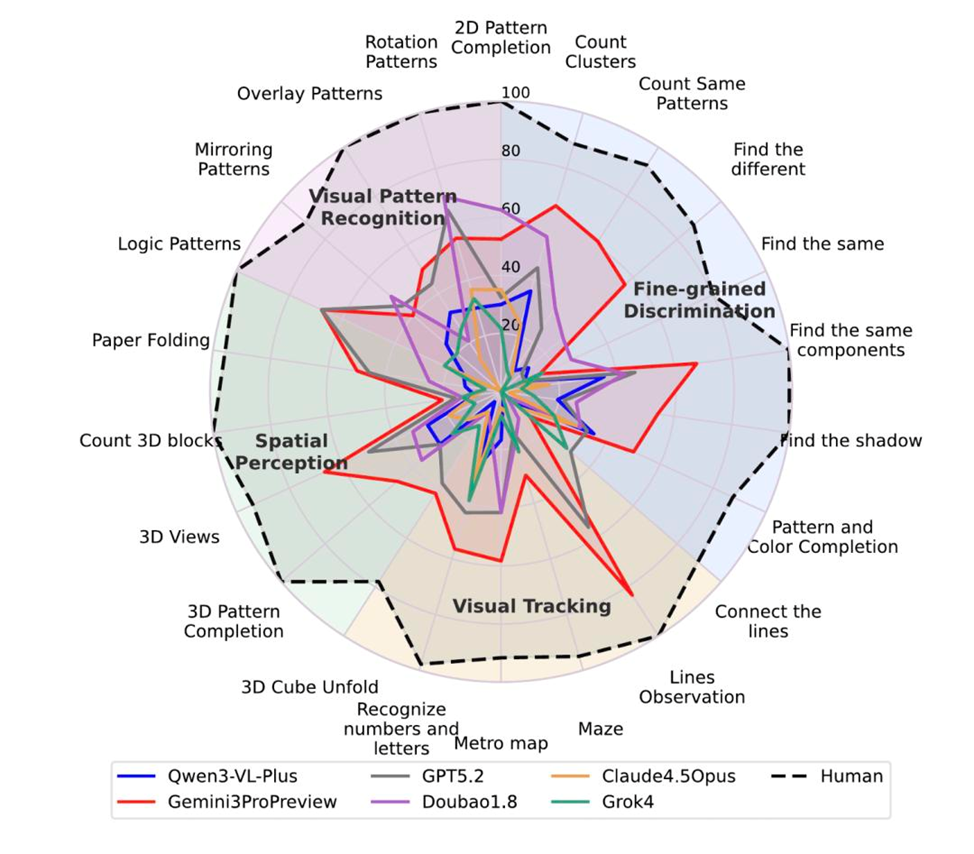
Ещё недавно казалось, что мультимодальные большие модели вот‑вот сравняются с человеком: они решают сложные тесты, пишут код и рассуждают «как аспирант». Но свежие результаты по визуальному рассуждению от ряда организаций (UniPat AI, xbench, Alibaba, Moonshot AI/«月之暗面», StepFun/«阶跃星辰» и др.) охлаждают ожидания: на бенчмарке BabyVision даже лучшая на сегодня модель Gemini 3 Pro Preview лишь немного превосходит трёхлетних детей и всё ещё отстаёт от шестилетних примерно на 20%. До уровня взрослого человека (94,1) — пропасть.
Причём Gemini 3 Pro Preview выступает «потолком» среди сравниваемых систем. Другие фронтир‑модели, включая GPT‑5.2, Claude 4.5 Opus и Grok‑4, в среднем показывают результаты, сопоставимые с трёхлетними — а иногда и хуже.
Для направлений вроде VLA(M) и «воплощённого» ИИ это неприятный сигнал: если система не дотягивает даже до базового детского уровня зрительного анализа, трудно ожидать от неё устойчивой и безопасной работы в физическом мире.
В чём корень проблемы: «перевод зрения в язык» и потери информации
Ключевой вывод исследования звучит жёстко: полагаться на визуальное рассуждение через язык — тупиковая стратегия. Большинство мультимодальных LLM сегодня устроены так, что перед рассуждением они преобразуют изображение в текстовые представления (описания, токены‑сводки), а затем запускают привычную языковую логику. Это даёт бонус за счёт мощи LLM‑мышления, но вводит фундаментальное ограничение: всё, что плохо «упаковывается» в слова, теряется.
Фразу «красная машина» описать легко. А вот тонкие геометрические признаки — точная кривизна границы, микросмещения, положение пересечений, нюансы относительных расстояний — крайне сложно выразить языком без искажений. Именно такие «слабо описуемые» детали и составляют ядро задач BabyVision, поэтому даже сильнейшие модели массово ошибаются там, где человеку достаточно одного взгляда.
Что именно проверяет BabyVision
Бенчмарк раскладывает визуальное рассуждение на четыре базовые способности:
- Тонкое различение (Fine‑grained Discrimination) — замечать минимальные отличия.
- Визуальное отслеживание (Visual Tracking) — вести взглядом линии, маршруты и траектории.
- Пространственное восприятие (Spatial Perception) — понимать 3D‑структуру и отношения в пространстве.
- Распознавание визуальных паттернов (Visual Pattern Recognition) — видеть закономерности, логику и геометрию в изображениях.
На их основе авторы выделяют типичные «провалы» современных MLLM.
Четыре классические ловушки для мультимодальных моделей
1) Потеря неязыковых тонких деталей.
В задачах «найди совпадающую деталь» модель нередко выбирает почти правильный вариант, потому что после вербализации сводит форму к грубым признакам (количество элементов, общая топология). Человек же делает прямое геометрическое сопоставление: мысленно поворачивает/сдвигает фигуру и проверяет совпадение границ — без текстового посредника. Проблема здесь не в «логике», а в отсутствии высокоточного восприятия.
2) Потеря «целостности» при длинных трассировках (manifold identity).
В заданиях с линиями и пересечениями модель может «соскочить» на другую линию, потому что отслеживает путь как последовательность словесных шагов («влево‑вверх‑вправо…»). На перекрёстках такое разложение становится двусмысленным. Ребёнок и взрослый обычно просто «держат» одну линию взглядом до конца — и почти не ошибаются.
3) Слабая пространственная фантазия.
Когда нужно по двумерному виду представить трёхмерный объект и выбрать корректный «вид сбоку» или учесть скрытые части, текстовая сводка сцены оказывается слишком грубой. Модель может недосчитать блоки, «потерять» закрытые элементы или применить неверное правило проекции. Человек, напротив, выполняет мысленное вращение объекта и сравнение формы напрямую.
4) Плохая индукция визуальных правил.
В задачах «найди закономерность» модели часто не понимают преобразование, а «считают свойства»: сколько цветов, сколько фигур, похожи ли элементы. Это приводит к ошибкам, когда важно уловить роли и отношения (что является рамкой, что содержимым; кто «внутри» кого; как перераспределяются элементы). Человек строит простую причинную схему изменений и переносит её на новый пример.
Есть ли путь вперёд: RLVR и «генеративное» визуальное рассуждение
Исследование предлагает два направления, которые частично обходят языковый потолок.
RLVR (обучение с подкреплением по проверяемой награде).
На базе Qwen3‑VL‑8B‑Thinking авторы применили RLVR‑дообучение и получили рост общей точности примерно на 4,8 п.п. Наблюдение согласуется с практикой: явные промежуточные шаги рассуждения помогают компенсировать визуальную неопределённость — но не отменяют проблему потерь на входе.
Генеративное визуальное рассуждение (думать в пикселях).
Если язык искажает сигнал, можно ли рассуждать через визуальную реконструкцию — рисовать траектории, дорисовывать паттерны, «проигрывать» шаги прямо в изображении? Для этого предложен набор BabyVision‑Gen (280 задач), где модель должна выдавать изображение/видеопоток как форму решения.
Проверили три генеративные системы: NanoBanana‑Pro (18,3%), GPT‑Image‑1.5 (9,8%), Qwen‑Image‑Edit (4,8%). Абсолютные значения пока невысоки, но появилось важное свидетельство: некоторые модели демонстрируют зачатки «явного визуального мышления» — например, умеют строить физически осмысленные траектории.
В то же время авторы подчёркивают: генерация ≠ строгая логика. Чтобы «рисование решения» стало надёжным, его должна направлять крепкая визуальная семантика (понимание того, что именно изображено и какие отношения важны).
Главный вывод
BabyVision фактически разворачивает дискуссию о будущем мультимодальности: прогресс потребует не косметических улучшений «картинка → текст → рассуждение», а перестройки зрительной способности на базовом уровне и сохранения высокоточной визуальной репрезентации в процессе мысли. Тренд намечается: превращать генеративные модели в «нативных» мультимодальных рассуждателей, которые могут явно думать в визуальном пространстве — выделять области, чертить промежуточные шаги, вести траектории — вместо того чтобы каждый раз переводить зрение в слова и терять существенные детали.
Если захотите, могу сделать более «журнальный» вариант (с меньшим количеством терминов) или, наоборот, более технический пересказ с акцентом на цифры и выводы для embodied‑AI.
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru
Сайт https://www.smssystems.ru/razrabotka-ai/