
Новое исследование Mercor с тестом Apex-Agents оценило возможности ведущих моделей ИИ в решении сложных задач из консалтинга, инвестиционного банкинга и юриспруденции. Большинство моделей провалились, показав неспособность к многодоменному рассуждению, что замедляет автоматизацию офисного труда.
Несмотря на огромный прогресс, достигнутый базовыми моделями, изменения в интеллектуальном труде происходят медленно. Модели освоили глубокие исследования и агентное планирование, но по какой-то причине большинство офисной работы практически не изменилось.
Это одна из величайших загадок в сфере ИИ — и благодаря новому исследованию от гиганта в области обучающих данных Mercor, мы наконец-то получаем ответы.
Новое исследование анализирует, как ведущие модели ИИ справляются с реальными задачами офисных работников, заимствованными из консалтинга, инвестиционного банкинга и юриспруденции. Результатом стал новый эталонный тест под названием Apex-Agents — и пока что каждая лаборатория ИИ получает неудовлетворительную оценку. Столкнувшись с запросами от реальных профессионалов, даже лучшие модели смогли правильно ответить лишь на четверть вопросов. В подавляющем большинстве случаев модель возвращала неверный ответ или не давала его вовсе.
По словам исследователя Брендана Фуди, участвовавшего в подготовке статьи, самой большой проблемой для моделей стало отслеживание информации в нескольких доменах — то, что является неотъемлемой частью большей части интеллектуального труда, выполняемого людьми.
«Одно из главных отличий этого бенчмарка в том, что мы построили всю среду по образцу реальных профессиональных услуг», — рассказал Фуди Techcrunch. «То, как мы выполняем свою работу, не предполагает, что один человек предоставляет нам весь контекст в одном месте. В реальной жизни вы работаете через Slack, Google Drive и все эти другие инструменты». Для многих агентных моделей ИИ такое многодоменное рассуждение по-прежнему непредсказуемо.
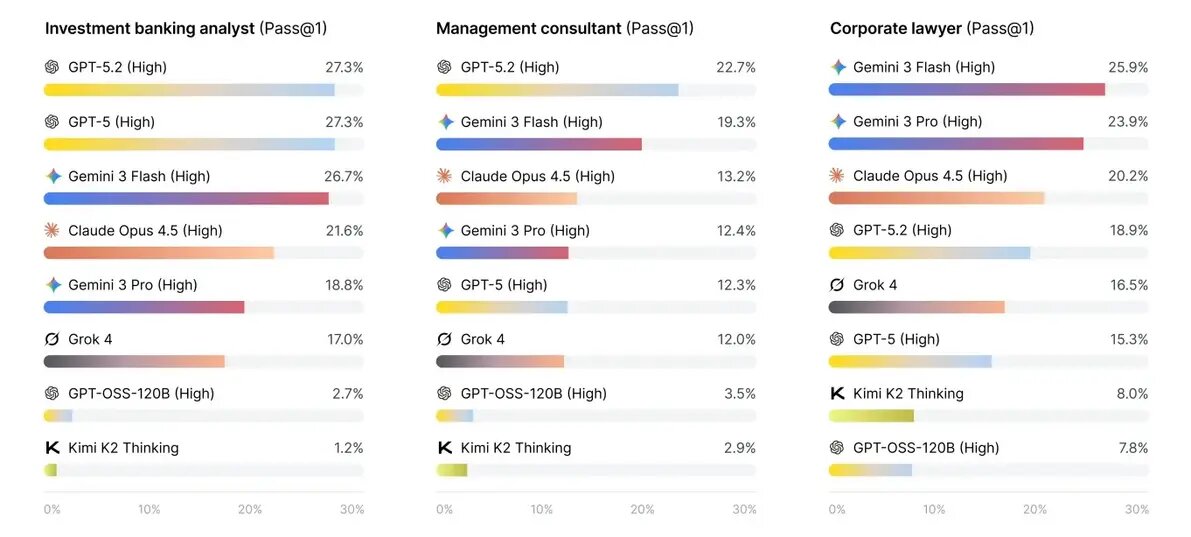
Сценарии были взяты у реальных профессионалов с экспертной площадки Mercor, которые как формулировали запросы, так и устанавливали стандарты успешного ответа. Изучение вопросов, которые опубликованы в открытом доступе на Hugging Face, дает представление о том, насколько сложными могут быть задачи.
Один из вопросов в разделе «Юриспруденция» гласит:
В течение первых 48 минут сбоя в работе европейского производства команда инженеров Northstar экспортировала один или два пакета журналов событий европейского производства, содержащих персональные данные, стороннему аналитическому поставщику в США…. Согласно собственной политике Northstar, она может обоснованно считать этот один или два экспорта журналов соответствующими Статье 49?
Правильный ответ — да, но для его получения требуется глубокая оценка как внутренней политики компании, так и применимых законов ЕС о конфиденциальности.
Это может поставить в тупик даже хорошо осведомленного человека, но исследователи стремились смоделировать работу профессионалов в этой области. Если большая языковая модель (LLM) сможет надежно отвечать на такие вопросы, она сможет фактически заменить многих современных юристов. «Я думаю, это, вероятно, самая важная тема в экономике», — сказал Фуди TechCrunch. «Бенчмарк очень точно отражает реальную работу, которую выполняют эти люди».
OpenAI также пыталась измерить профессиональные навыки с помощью своего бенчмарка GDPVal — но тест Apex Agents отличается в важных аспектах. В то время как GDPVal проверяет общие знания в широком спектре профессий, бенчмарк Apex Agents измеряет способность системы выполнять продолжительные задачи в узком наборе высокоценных профессий. Результат более сложен для моделей, но и теснее связан с тем, могут ли эти рабочие места быть автоматизированы.
Хотя ни одна из моделей не оказалась готова заменить инвестиционных банкиров, некоторые были явно ближе к цели. Gemini 3 Flash показал лучший результат в группе с точностью 24% с первой попытки (one-shot accuracy), за ним следовала GPT-5.2 с 23%. Ниже расположились Opus 4.5, Gemini 3 Pro и GPT-5, набравшие около 18%.
Хотя первоначальные результаты показывают отставание, сфера ИИ имеет историю быстрого преодоления сложных эталонов. Теперь, когда тест Apex стал публичным, это открытый вызов для лабораторий ИИ, которые считают, что могут справиться лучше — чего Фуди вполне ожидает в ближайшие месяцы.
«Она очень быстро совершенствуется», — сказал он TechCrunch. «Прямо сейчас справедливо сказать, что это как стажер, который правильно отвечает в четверти случаев, но в прошлом году это был стажер, который отвечает правильно в пяти или десяти процентах случаев. Такого рода улучшения из года в год могут очень быстро дать результат».
]
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Russell Brandom