ИИ в бизнесе сегодня есть почти у всех. Но большинство ИИ-проектов так и не доходит до промышленного использования и не дает измеримого эффекта. Разбираемся, что такое ИИ в бизнесе – технология, которую сложно и долго внедрять, или классический технологический пузырь.

Сергей Путятинский, вице-президент БКС по операционной деятельности и ИТ
Какие есть риски для корпораций
Масштабные корпоративные решения на базе больших языковых моделей (LLM, Large Language Model) находятся скорее в стадии ожиданий, чем в стадии зрелого внедрения. Несмотря на активные инвестиции и громкие заявления, в большинстве компаний ИИ используется фрагментарно, в виде частных, несистемных решений, не встроенных в ключевые бизнес-процессы.
Формально бизнес может отчитаться о «применении ИИ», но чаще всего на практике речь идет об ad hoc-использовании без интеграции в бизнес-процессы компании: сотрудники самостоятельно используют ChatGPT и другие сервисы, не имея корпоративных регламентов, без интеграции и контроля со стороны ИТ и информационной безопасности. Эффект от такого внедрения пока ограничен и выражается в том, что сотрудникам стало комфортнее работать, быстрее искать информацию и ее структурировать. Однако заметного роста эффективности на уровне компании в целом нет. Это хорошо иллюстрирует ситуация в разработке: ожидалось, что ИИ даст до 40% прироста эффективности среди программистов, но в действительности генеративные модели пока слабо применимы к доработке сложных корпоративных систем. Значительную часть сгенерированного кода в любом случае нужно адаптировать и переписывать, поэтому разработчики тратят все еще много времени.
Также персонал сокращают пока минимально. ИИ высвобождает часть рабочего времени, которое удаленные сотрудники используют для подработки или личных задач. С точки зрения бизнеса это означает рост индивидуального комфорта, но не операционной эффективности.
Отдельный риск связан с тем, что большая часть сотрудников от ИТ-специалистов до юристов использует внешние решения и платформы. При этом у компаний нет полноценного контроля за потенциальными утечками информации.
На фоне этого разрыва между ожиданиями и реальностью все чаще звучит тезис об ИИ-пузыре. Его ключевой признак – несоответствие между объемом инвестиций и фактической бизнес-отдачей.
Это видно и на уровне рынка. Совокупная выручка крупнейших разработчиков ИИ-решений растет взрывными темпами, но концентрируется она в ограниченном числе компаний и продуктов, в то время как массовые корпоративные внедрения все еще не дают сопоставимого экономического эффекта.
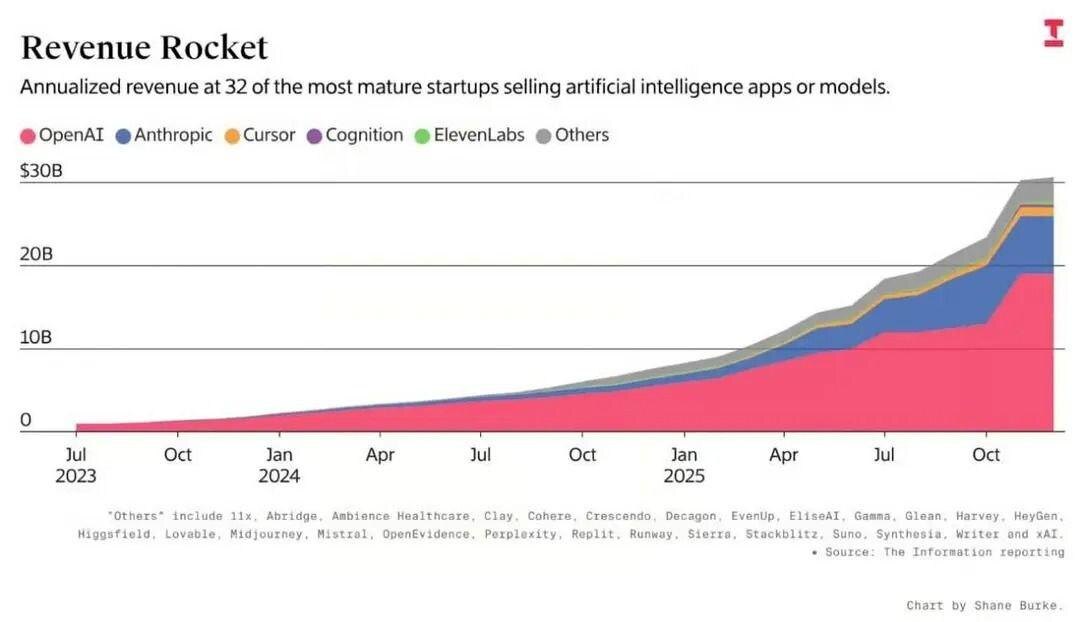
Рост годовой выручки крупнейших ИИ-стартапов (OpenAI, Anthropic и др.) на фоне продолжающихся трудностей с масштабным корпоративным внедрением ИИ.
ML формально есть почти везде, но реально не работает
Если судить по публичным заявлениям, машинное обучение в финансовом секторе используется многими. Банки и финансовые компании говорят, что применяют ML в разных процессах:
- маркетинг и привлечение клиента;
- персональные предложения (Upsale и Next Best Offer);
- антифрод и выявление подозрительных операций;
- автоматическая обработка клиентских и внутренних обращений;
- риск-менеджмент, кредитный анализ и принятие инвестиционных решений.
Но все-таки в большинстве ключевых онлайн-процессов по-прежнему работают традиционные модели: логистическая регрессия и деревья решений. Современные нейросети и продвинутые ML-модели либо используются только для проверки гипотез в офлайне, либо внедряются в некритичные процессы, не влияющие напрямую на бизнес-результат. Например, чтобы автоматически отсмотреть резюме соискателей.
Такой подход создает иллюзию зрелости, но не дает получить максимальную выгоду от современных ML-инструментов – в реальном времени, на больших потоках данных, с принятием решений с прямым финансовым эффектом.
Причина здесь не в отсутствии технологий. Инструменты машинного обучения доступны, вычислительные мощности есть, экспертиза на рынке сформирована. Проблема в том, что большинство организаций не готово к промышленной эксплуатации ML.
Причина 1. Нет инфраструктуры для безопасной и управляемой работы с LLM
Даже там, где компании готовы экспериментировать с большими языковыми моделями, они быстро упираются в инфраструктурные ограничения. Для использования LLM в корпоративной среде нужны понятные правила безопасности, контроля и ответственности – и именно этого чаще всего не хватает.
А именно:
- Нет DLP-контроля. Сотрудники используют внешние модели для анализа документов, подготовки текстов или поиска информации, но при этом непонятно, какие данные передаются вовне и где они в итоге оказываются.
- Не выбрана инфраструктура. Нужно решить: либо создавать дорогую собственную, либо пользоваться технологиями провайдера.
- Нет роли, отвечающей за ИИ на уровне всей организации (CAIO, Chief AI Officer). Чаще всего ИИ-проекты распределяются между ИТ, безопасностью, бизнес-подразделениями и аналитиками без общего видения и приоритетов.
- Нет ИИ-шлюза – слоя, который управляет доступом к языковым моделям, маршрутизирует запросы, логирует действия пользователей и интегрируется с внутренними системами.
Сейчас ИИ используется точечно и неформально, но не может быть переведен в промышленную эксплуатацию. Пока у компании нет базовой инфраструктуры для безопасной и управляемой работы с LLM, любые разговоры о масштабировании остаются теоретическими.
Причина 2. Нет корпоративной базы знаний
Даже при наличии инфраструктуры и доступа к современным языковым моделям компании часто сталкиваются с тем, что у ИИ не получается формулировать ответы на уровне, который нужен именно финансовой организации. Проблема в том, что модель не знает корпоративной специфики.
Большие языковые модели обучены на открытых данных и общем контексте. Они хорошо пишут тексты, обобщают информацию и отвечают на типовые вопросы, но не знают внутренних регламентов, бизнес-логики, продуктовых нюансов и нюансов, которые есть в работе банка или финансовой компании.
Во многих организациях базы знаний и документы хранятся в разных системах, переписки в почте и мессенджерах, регламенты не обновляются, а данные из CRM и других систем не связаны между собой. В такой среде ИИ не на что опираться: он либо отвечает слишком обобщенно, либо пытается догадаться, что недопустимо для регулируемой отрасли.
Для создания единой корпоративной базы знаний нужна инвентаризация источников информации, определение «золотых» данных, ответственных владельцев и правил обновления.
Причина 3. Нет MLOps и управления качеством моделей
Даже там, где машинное обучение используется, у компаний часто нет понимания, как именно работают модели и какой результат они дают. Причина в отсутствии MLOps и процессов управления качеством аналитических моделей.
Это значит, что в организации нет единой системы, которая позволяла бы:
- отслеживать, какие модели используются в бизнес-процессах;
- понимать, на каких данных они обучены;
- контролировать качество и стабильность их работы со временем;
- управлять изменениями и обновлениями моделей.
Отдельная сложность – компаниям нужно научиться управлять данными: проводить их инвентаризацию, определить домены данных и их владельцев, контролировать качество.
Также сами модели непрозрачны. Бизнес часто не понимает, используется ли в процессе простая логистическая регрессия или сложная нейросеть. В условиях финансового сектора это незнание критично, потому что формально модель может работать, но масштабировать или использовать в онлайн-режиме ее уже не получится.
В итоге ML-проекты буксуют не из-за отсутствия алгоритмов или вычислительных мощностей. Мы видим, что технологии давно доступны. Проблема в том, что без MLOps и управления качеством моделей машинное обучение невозможно эксплуатировать как промышленный инструмент – только как эксперимент или разрозненный набор пилотов.
Где ИИ реально работает
Несмотря на некий скепсис, периодически ИИ дает понятный и устойчивый результат. Как правило, он хорошо справляется там, где есть четкие правила, понятные данные и ограниченная зона ответственности.
Один из примеров – обработка обращений клиентов. ИИ берет на себя рутинную работу: классифицирует сообщения, выделяет ключевую информацию, запрашивает дополнительные данные у внутренних подразделений. В таких задачах до 90% первичной обработки может выполняться автоматически. Финальные решения при этом все равно принимают сотрудники.
Второе направление – интеллектуальный поиск и генерация контента. ИИ помогает находить документы, быстро разбираться в массиве информации, готовить черновики. Здесь не идет речь о высоком росте производительности, но это экономит время сотрудников и исключает их из рутинной работы.
Общее у этих кейсов одно: ИИ не заменяет сотрудников и не принимает сложных решений сам. Он встраивается в существующую систему и работает с конкретной задачей.
.
👉 Подписывайтесь на канал Finversia на платформах YouTube, Telegram, Rutube и ВКонтакте.