Google: внутренний диалог повышает точность LLM
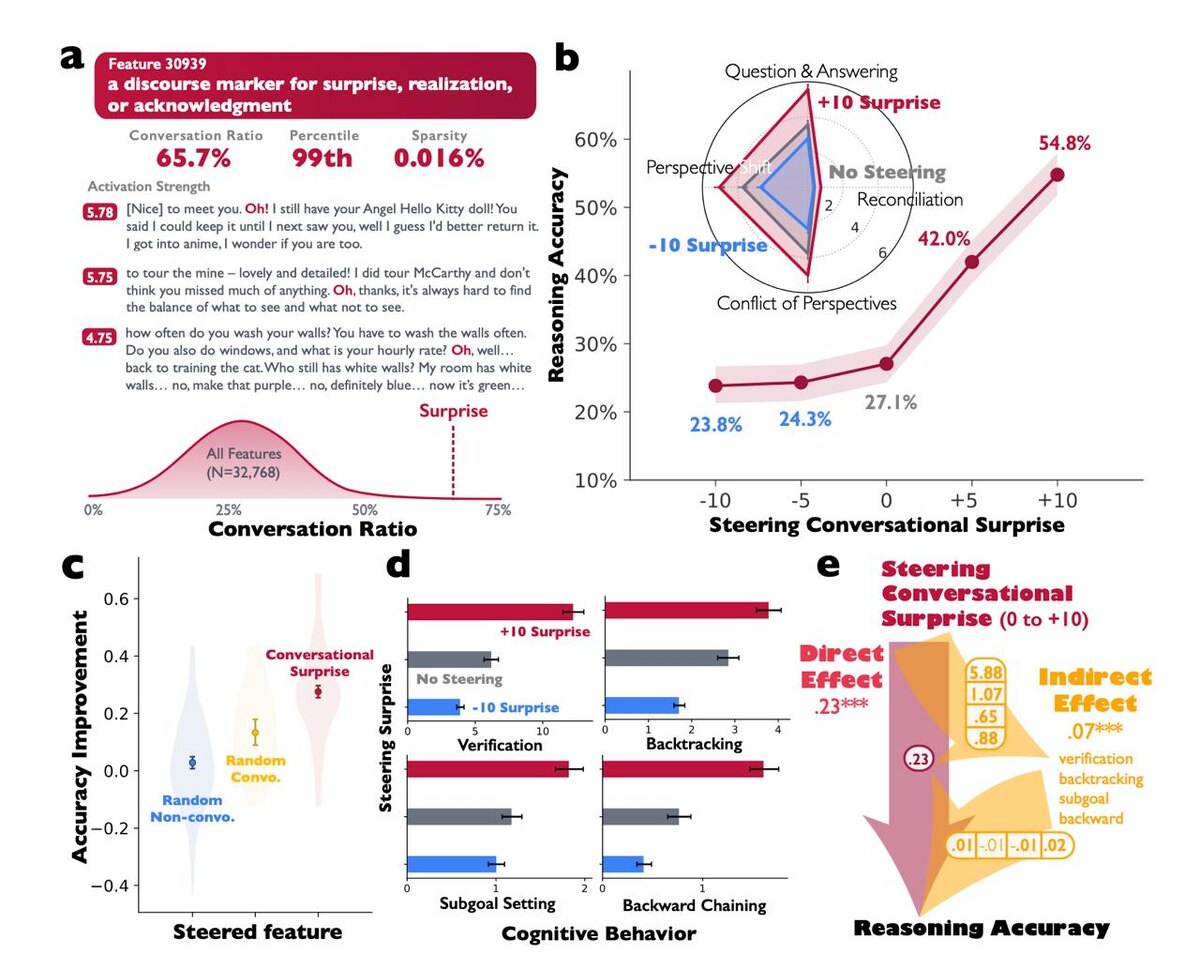
Исследование Google показало, что усиление внутренних диалоговых маркеров в LLM, таких как «о!», «подожди-ка», может увеличить точность ответов на сложных задачах в 2 раза.
Авторы использовали sparse autoencoder для выявления нейронного признака, отвечающего за удивление и смену точки зрения, который активируется в начале предложений в диалоговых контекстах. При усилении этого признака в модели deepseek-r1-llama-8b точность на задачах комбинаторной арифметики выросла с 27,1% до 54,8%. При подавлении признака точность снизилась до 23,8%.
«— Внутренний диалог — ключевой феномен reasoning в LLM», отмечают авторы. Эффект усиления проверен по сравнению с другими признаками и признан статистически значимым. Также отмечен рост способности к стратегическому мышлению.
https://dzen.ru/id/5c0e38ff46ef5c00aaa80527