Sakana AI предложили очередное простое улучшение: вместо того, чтобы делать сложные функции близости для позиционных векторов в трасформерах (как классические Positional Encoding или RoPE) или просто их выучивать, как было, например, в GPT2), они предложили простую идею - давайте предсказывать позицию для каждого токена (первая картинка)
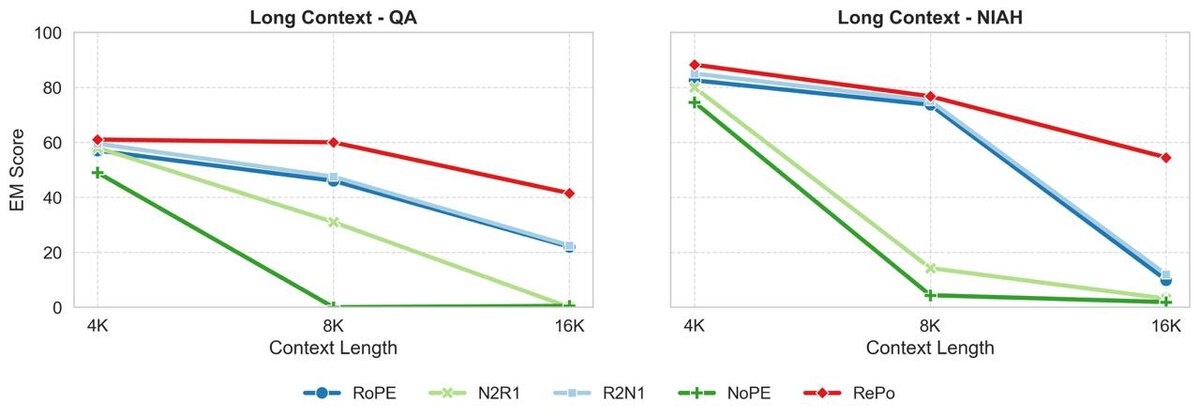
это приводит к тому, что близость токенов определяется их семантической близостью, а из этого уже следует возможность для модели лучше работать с шумным текстом (например, с выходом ASR) или просто с длинным текстом (вторая картинка)
в целом, могу только поаплодировать коллегам, идея что называется витала в воздухе, а они ее ухватили и доказали ее полезность
P.S. напоминаю, что Sakana сейчас делают одни из самых интересных вещей в индустрии, уже не раз обозревал их работы (1, 2, 3)