Вы вспоминаете, как два человека танцевали на вечеринке, а компьютер по активности вашего мозга генерирует описание: "Two young men speak while a group of women are hugging each other." Звучит как что-то фантастическое? А это уже реальность…
Японский нейроученый Томоясу Хорикава из NTT разработал метод, который превращает мозговую активность в развернутые текстовые описания того, что человек видит или вспоминает. Статья недавно вышла в Science Advances — и это настоящий прорыв в исследованиях коммуникации “мозг—компьютер”!

Как это работает?
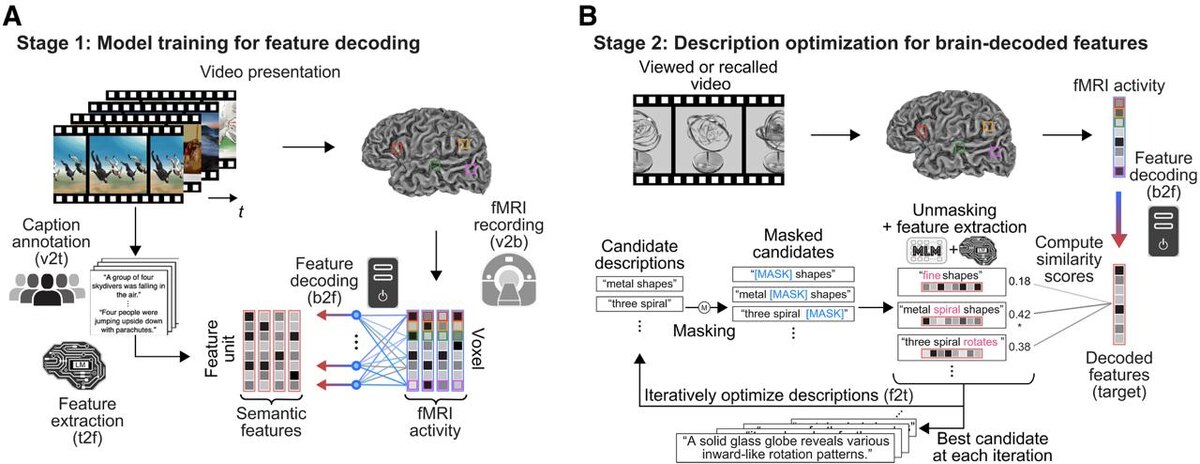
Испытуемые (японцы, для которых английский — не родной) провели в фМРТ-сканере примерно 17 часов: смотрели 2180 коротких видео, затем вспоминали отобранные ролики с закрытыми глазами.
“Считывание мыслей” происходило следующим образом:
- Линейные декодеры "переводили" паттерны активности всего мозга в семантические фичи — числовые представления смысла
- Маскированная языковая модель итеративно строила текст: заменяла слова на <MASK>, предлагала варианты заполнения на основе контекста, выбирала те, что лучше всего соответствуют декодированным из мозга фичам. Процесс повторяется 100 раз — от обрывочных фраз к связному тексту.
Никаких баз данных с готовыми описаниями — только прямое согласование семантических репрезентаций мозга с текстом.
Важность структуры
Ключевая проверка: если мозг кодирует не просто объекты ("птица", "змея"), а их взаимодействия ("птица ест змею" vs. "змея ест птицу"), то перемешивание слов в описаниях должно ухудшить соответствие с активностью мозга.
Эксперимент показал — когда Хорикава перемешивал слова в сгенерированных описаниях, способность моделей различать разные видео значимо упала. Более того, фичи, декодированные из мозга, коррелировали с оригинальным порядком слов сильнее, чем с любым из 1000 перемешанных вариантов. А когда обучили декодеры на изначально перемешанных описаниях — получились бессвязные наборы правильных по смыслу слов без структуры.
Интересное наблюдение
Метод прекрасно работал без классических языковых областей мозга. Когда ученый исключил височные и фронтальные языковые зоны из анализа, точность почти не упала — осталась около 50% из 100 вариантов.
Получается, структурированная визуальная семантика закодирована в областях от передней части затылочной коры (где обрабатывается зрение) через теменную до фронтальной коры — но за пределами классической языковой сети.
Дополнительный анализ показал:
- задние части визуальной коры кодируют отдельные категории объектов ("лицо", "место", "тело")
- передние части — уже контекстуализированные представления с отношениями между элементами. Причем эти передние части находятся близко к языковым зонам, возможно служа мостом между невербальной визуальной информацией и языком.
Выводы
Так и что в итоге, может ли искусственный интеллект “читать мысли”?
В прямом смысле — пока нет. Это скорее интерпретирующий интерфейс: система переводит невербальные ментальные репрезентации в текст, опираясь на паттерны, которым научилась на данных. Но прорыв очевиден: метод работает даже для воспоминаний, и даже когда человек думает на одном языке, а описания генерируются на другом.
Потенциал для клиники огромен — альтернативный канал коммуникации для пациентов с афазией или БАС, где повреждение речевых/моторных зон блокирует обычное общение.
Источник
Tomoyasu Horikawa. Mind captioning: Evolving descriptive text of mental content from human brain activity.Sci. Adv.11,eadw1464(2025).DOI:10.1126/sciadv.adw1464
Если вы хотите больше узнать о нашей психике и работе мозга, вы можете подписаться на мой Бусти и на ТГ-канал "Нейроны и стрелки".