
AI инфраструктуры — это связка железа, облаков и оркестрации, которая даёт бизнесу предсказуемую цену за каждый запрос к моделям. В 2025–2026 году свой кластер окупается только при стабильной высокой загрузке и готовности решать вопросы электрики и охлаждения.
Типичный звонок: «У нас счёт за GPT и клауды раздулся, давайте купим пару H100 и выкатим свой кластер». На другом конце провода тишина, когда слышат цифры по цене железа и энергопотреблению.
Дальше начинается реальный расчёт: сколько стоит войти в игру с собственным AI-кластером, когда выгодно оставаться в облаках, и можно ли прожить вообще без своих GPU, упершись в Make.com, RAG и дешевый инференс. Эти три развилки и разберём по шагам.
6 шагов к вменяемой AI‑инфраструктуре
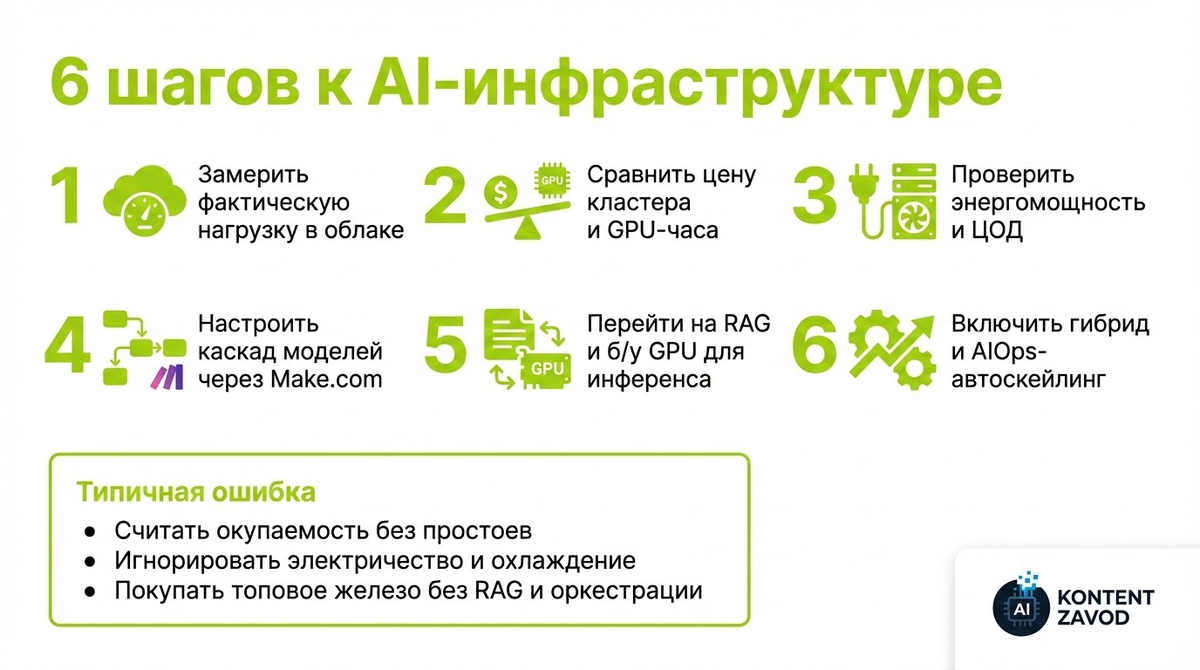
Шаг 1. Честно посчитать нагрузку и цену облака
Соберите статистику: сколько часов в месяц реально жгут GPU под ваши задачи, какие модели и где крутятся.
Зачем: понять, попадаете ли вы в зону, где свой кластер окупится за 9–14 месяцев при круглосуточной загрузке.
Типичная ошибка: считать «на глаз» и не учитывать простои, когда GPU висят без задач.
Пример РФ: продуктовая команда в Москве выгрузила логи с AWS и увидела, что их GPU заняты стабильно, но только 50–60% времени, из-за чего покупка железа сейчас им не даёт нужного ROI.
Шаг 2. Сравнить свой кластер и облако в цифрах
Берём минимальный жизнеспособный кластер под LLM 70B+: 8 GPU в одном HGX‑узле с NVLink.
Зачем: понять, вытянете ли старт от 250,000 до 350,000 долларов за сервер под ключ против аренды по 2.50–4.00 доллара за GPU‑час в облаке.
Типичная ошибка: забывать, что к цене сервера добавятся электричество и охлаждение, которые за год подорожали на 20–30%.
Пример РФ: крупный интегратор считал покупку узла, сравнил с сметой по аренде мощностей в зарубежном облаке и понял, что выйдет в плюс только при почти непрерывной загрузке 24/7.
Шаг 3. Учесть энергопотребление и ЦОД, а не только железо
Проверяем, где физически будет жить кластер и есть ли доступная мощность под стойки.
Зачем: стойка с Blackwell уже потребляет до 100–120 кВт против привычных 10–15 кВт, без жидкостного охлаждения это просто не взлетит.
Типичная ошибка: пытаться впихнуть серьёзный AI‑кластер в офисный серверный шкаф с обычным кондиционером.
Пример РФ: региональный банк считал запуск стойки в своём офисе, в итоге ушёл в colocation с готовой инфраструктурой и жидкостным охлаждением, а свои комнаты оставил под менее прожорливые сервера.
Шаг 4. Выжать максимум из Make.com, RAG и каскада моделей
Строим каскад: дешёвая и быстрая модель отвечает на входящий запрос, а автоматизация через Make.com или n8n пересылает сложные кейсы на дорогую модель или в облачный API.
Зачем: снизить нагрузку на дорогие ресурсы до 70% и оттянуть момент, когда нужен свой кластер.
Типичная ошибка: сразу вбухиваться в одну огромную модель «на все случаи», без маршрутизации и оркестрации.
Пример РФ: маркетплейс настраивает в Make.com связку быстрых моделей для типовых ответов и RAG по своей базе карточек, а сложные обращения клиентов гонит в мощный облачный LLM по API.
Шаг 5. Переключиться с дообучения на RAG и б/у GPU
Смотрим, действительно ли нужен дорогой fine-tuning, или можно обойтись Retrieval-Augmented Generation и векторными базами.
Зачем: RAG резко снижает требования к железу, а для инференса можно взять восстановленные A100 или A6000 и собрать сервер за 15–20 тысяч долларов.
Типичная ошибка: покупать железо уровня H100 только ради инференса, когда можно решить задачу более простым стеком.
Пример РФ: SaaS‑сервис для юристов поднял векторную базу решений судов и запустил свои модели на б/у GPU в арендованном стойкопозиции, отказавшись от идеи собственного монструозного кластера.
Шаг 6. Настроить гибрид и AIOps, а не жить в крайностях
Строим модель «ядро + облако»: базовая нагрузка идёт на свой компактный кластер или bare metal, пики выливаются в публичное облако.
Зачем: использовать AIOps и агентов, которые предсказывают пики, заранее включают и выключают узлы кластера и экономят до 40% бюджета на электричестве и простоях.
Типичная ошибка: выбирать или только облако, или только on‑prem, без гибридного сценария и автоскейлинга.
Пример РФ: онлайн‑школа в пиковый сезон экзаменов прогревает доп‑мощности в облаке, в остальное время работает на небольшом своём кластере и bare metal‑аренде в российском ЦОД.
Сравнение подходов к AI‑инфраструктуре
Когда эмоции по поводу чеков из облака улеглись, полезно спокойно сравнить три варианта: остаться в публичном облаке, взять bare metal или строить свой кластер с нуля.
Вердикт: зрелым командам с прогнозируемой круглосуточной нагрузкой выгоднее свой кластер или bare metal, всем остальным — жить в облаке и выжимать максимум из оркестрации.
Кому это реально сэкономит время и деньги
История с AI‑инфраструктурой перестала быть игрушкой для гиков: от правильного выбора схемы зависит, будете ли вы расти или тушить пожары с счетами и авариями.
- Продуктовые команды и маркетплейсы, которые уже платят за API крупным моделям на уровне десятков тысяч долларов в месяц и хотят понять, где точка безубыточности.
- Банки, финтех и госструктуры, которым важна репатриация данных и контроль над тем, где живут модели и векторные базы.
- AI‑стартапы и студии, у которых сейчас «рваная» нагрузка и которым выгоднее комбинировать Make.com, RAG и дешёвый инференс вместо покупки кластеров.
- Интеграторы и подрядчики по автоматизации, которым нужно объяснять заказчикам разницу между облаком, bare metal и своим железом без маркетингового тумана.
Частые вопросы
Когда свой AI‑кластер точно выгоднее облака?
Когда у вас стабильная загрузка GPU близко к 24/7, понятный план задач на 1–2 года и хватает бюджета выдержать 9–14 месяцев до фактической окупаемости железа.
А если нагрузка «рваная» и задачи по проектам?
Тогда проще и дешевле жить в облаке или на bare metal, а экономить за счет каскада моделей, RAG и оркестрации через Make.com, n8n и похожие инструменты.
Можно ли собрать кластер дома или в обычном офисе?
Для топовых чипов уровня Blackwell это уже почти нереально: стойка до 100–120 кВт требует жидкостного охлаждения и инфраструктуры ЦОД, а не бытовых кондиционеров.
Есть ли смысл в б/у GPU для инференса?
Да, восстановленные A100 и A6000 после волны стартапов 2023–2024 годов позволяют собрать сервер для инференса за 15–20 тысяч долларов вместо покупки самого свежего поколения.
Зачем вообще переходить на RAG, если есть fine-tuning?
Потому что расширенный RAG даёт нужную точность на ваших данных без покупки тяжёлого кластера под обучение и заметно снижает требования к железу.
Как использовать AI для управления самим кластером?
Через AIOps: агенты и сервисы, которые следят за очередями задач, предсказывают пики, крутят Kubernetes autoscaling и отключают лишние узлы, экономя до 40% бюджета.
Что выбрать маленькой команде в РФ в 2025–2026?
Комбинацию Make.com или n8n, облачных API моделей, RAG по своим данным и при необходимости аренду bare metal, пока счета за API не станут сопоставимы с владением своим кластером.
Как вы сейчас строите свои AI инфраструктуры — облако, bare metal или уже свой кластер в ЦОД? Напишите в комментариях свою схему и подпишитесь, чтобы не пропустить разборы реальных конфигураций и автоматизации на Make.com.
#ai, #инфраструктура, #облако
AI kontent Zavod:
Связаться с Андреем
Email
Заказать Нейро-Завод
Нейросмех YouTube
Нейроновости ТГ
Нейрозвук ТГ
Нейрохолст ТГ