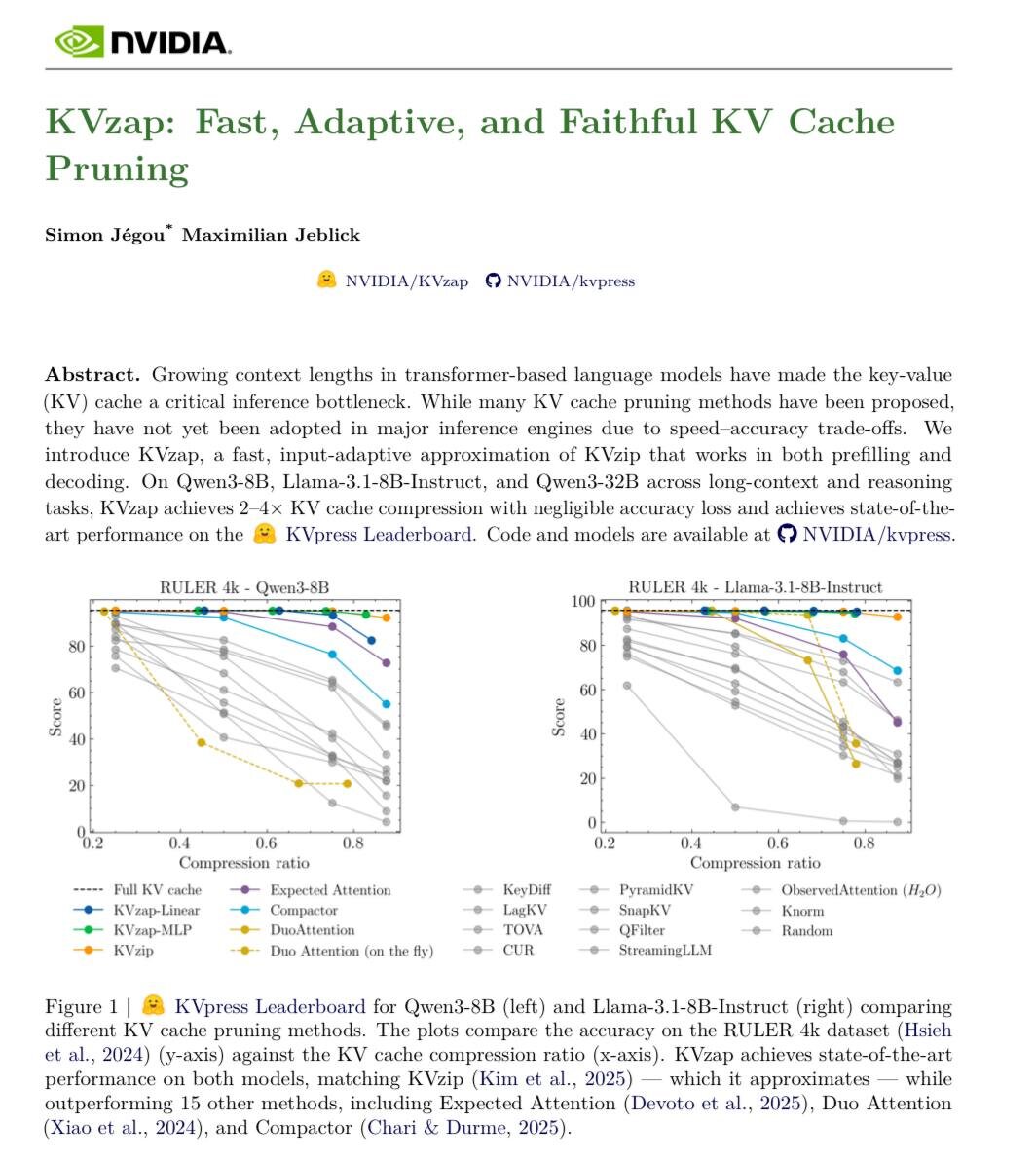
NVIDIA оптимизировала использование памяти для KV-кэша в трансформерах
NVIDIA представила метод, позволяющий в 3–4 раза эффективнее использовать память при инференсе KV-кэша — ключевого узкого места масштабирования трансформеров. Для моделей типа Llama с 65 млрд параметров и контекстом 128k токенов KV-кэш занимает около 335 ГБ памяти.
Новый подход основан на обучении небольшой модели (линейная или двухслойный MLP), которая по hidden state токена определяет важность его KV-пары для каждого слоя. KV-пары с важностью ниже порога удаляются. Вычислительные затраты — около 0,02% FLOPS для линейных моделей.
• Сжатие KV-кэша — 3–4× без потери качества.
• Деградация на бенчмарках — около нуля.
• Решение доступно в опенсорсе.
Исследование: https://arxiv.org/abs/2601.07891
https://dzen.ru/id/5c0e38ff46ef5c00aaa80527