Вот почему я не люблю Codex линейку от GPT
🤖 Смотрим на примере свежеиспеченной GPT 5.2 Codex Medium.
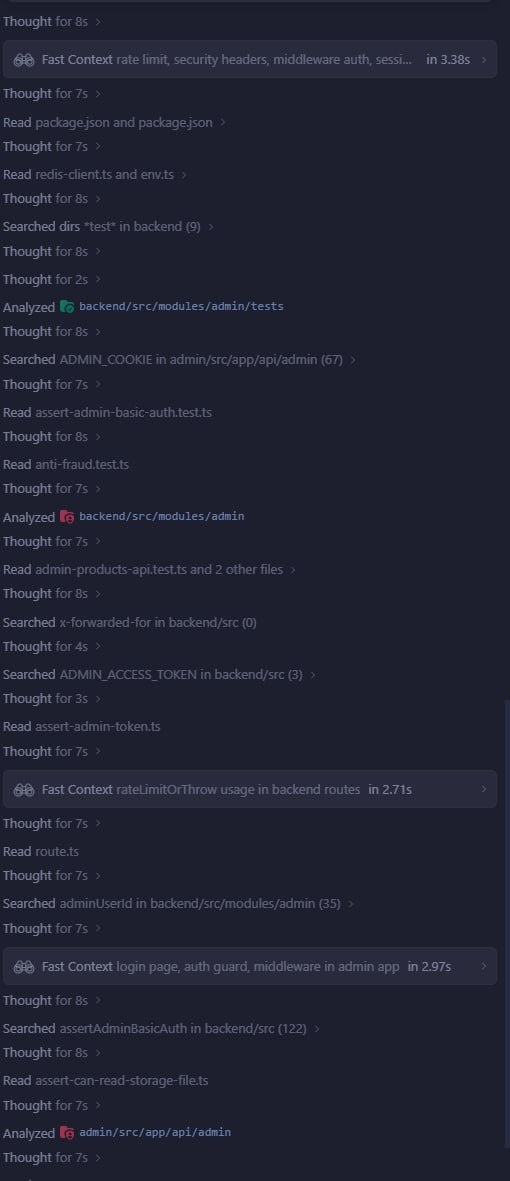
Даже на medium режиме моделька может задуматься на огромное количество времени, так ничего и не начав делать. При этом, если раскрыть суть ее рассуждений, все эти запуски будут просто гоняться по кругу, пока модель не сожжет весь бюджет токенов, выделенных на рассуждения, хотя, в большинстве случаев, ей бы хватило 1-2 раза это сделать.
И дело не в Windsurf, в оригинальном Codex Cli было то же самое.
💡 Поэтому Codex версии либо используем в LOW конфигурации и не даем больше 1 задачи в запросе, либо переходим на версии без "codex" отметки и просто в один запрос закидываем что угодно и будем уверены, что все будет выполнено в кратчайшие сроки. Модель общего назначения проявляет себя эффективнее. Проверено неоднократно, по возможности всегда об этом напоминаю.
Главное, не пугайтесь слова "Low". Модель не тупая в этом режиме, это просто градации количества токенов, которые будут выданы модельке для размышлений. По логике всё просто: больше рассуждений, больше шанс что все детали будут учтены, модель сама поймает себя на ложном ходе рассуждений и поправится, если что-то пойдет не так. Но на деле, размусоливание простой задачи может сместить фокус модели с реально важных задач и деталей. Потеряете и время, и токены. Запуск codex medium/high оправдан только для редких сложных бекендовых задач, где нужно учесть много сценариев и связей в коде.