Нейросети. Заметки Д.Семеновых о нейросетях.
Нейросеть ChatGPT. Можно пользоваться любой другой нейросетью, которая будет удобна.
Все они устроены по одному и тому же принципу и отличаются только набором функций и продвинутостью модели.
ChatGPT и прочие западные нейросети являются платными и недоступны в России без ВПН.
Альтернатива. Российские нейросети YandexGPT и ГигаЧат бесплатны и доступны для жителей России.
Большая часть рассматриваемых ИИ-сервисов имеют ограниченный бесплатный тариф, с которым
вполне можно работать. В "подсанкционных" регионах для обхода ограничений будет достаточно
качественного VPN или прокси, а также почты, зарегистрированной на иностранном сервисе.
Рекомендуется использовать отдельный браузер, ещё лучше антидетект браузер в связке с
прокси, например:
- Dolphin Anty
- Ads Power
Хотя эти меры часто избыточны, но порой имеют смысл. Российские и китайские нейросети можно использовать вообще без всяких ухищрений. Чтобы оформить платную подписку, дающую дополнительные привилегии достаточно иметь пластиковую карту (или виртуальную). Единственный нюанс - карты РФ и РБ не подходят.
Представьте, что вы случайно наткнулись на сценарий короткометражного фильма, который
описывает сцену между человеком и его ИИ-ассистентом. В сценарии есть то, что человек
спрашивает у ИИ, но ответ ИИ оборван.
Большая языковая модель (LLM) — это сложная математическая функция, предсказывающая
следующее слово для любого фрагмента текста. Однако вместо того, чтобы с уверенностью
предсказывать одно слово, модель назначает вероятности всем возможным следующим словам.
Чтобы создать чат-бота, сначала задаётся текст, описывающий взаимодействие между
пользователем и гипотетическим ИИ-ассистентом. Затем добавляется ввод пользователя как
первая часть диалога, а модель многократно предсказывает следующее слово, которое
мог бы сказать такой ИИ-ассистент в ответ.
Этот текст и отображается пользователю. При таком подходе текст выглядит гораздо
естественнее, если позволить модели иногда случайным образом выбирать менее вероятные
слова
Большие языковые модели называют большими, потому что у них могут быть сотни миллиардов
таких параметров. Человек никогда не задаёт эти параметры вручную. Вместо этого параметры
задаются случайно, из-за чего модель сначала выдаёт бессмыслицу, но затем многократно
корректируются на основе множества примеров текста.
Один обучающий пример может содержать как несколько слов, так и тысячи, но в любом случае
процесс работает так: в модель подаются все слова, кроме последнего, а затем предсказание
модели сравнивается с настоящим последним словом из примера.
Это означает что, хотя сама модель детерминирована, один и тот же запрос обычно приводит к разным ответам при каждом запуске. Модели учатся делать такие предсказания, обрабатывая огромное количество текста, обычно взятого из интернета.
Обычному человеку, чтобы прочитать объём текста, использованный, например, для обучения
GPT-3, потребовалось бы более 2600 лет непрерывного чтения 24/7.
Более поздние, более масштабные модели обучаются на существенно больших объёмах данных.
Обучение можно сравнить с регулировкой множества параметров в сложном механизме.
То, как ведёт себя языковая модель, полностью зависит от множества непрерывных значений,
известных как параметры или веса
Изменение этих параметров изменит вероятности, с которыми модель предсказывает следующее
слово для заданного ввода.
Алгоритм обратного распространения ошибки корректирует параметры так, чтобы модель с
большей вероятностью выбирала правильное последнее слово и с меньшей — все остальные.
Когда этот процесс повторяется на огромном количестве примеров триллионы раз. Модель не
только начинает точнее предсказывать слова в обучающих данных, но и выдавать более
осмысленные предсказания для текстов, которых она раньше не видела
Учитывая огромное количество параметров и колоссальный объём обучающих данных, масштаб
вычислений, необходимых для обучения большой языковой модели, просто поражает.
Для наглядности представьте, что вы можете выполнять миллиард сложений и умножений
каждую секунду.
Как думаете, сколько времени у вас бы ушло на выполнение всех вычислений, необходимых для
обучения самых больших языковых моделей? Думаете, на это уйдет год? Или, может быть, около
10 000 лет?
На самом деле потребуется намного больше! Речь идёт о более чем 100 миллионах лет.
Однако это лишь одна сторона процесса. Весь этот этап называется предобучением модели.
Цель автодополнения случайного фрагмента текста из интернета сильно отличается от цели
создания хорошего ИИ-ассистента (типа ChatGPT, Claude, Gemini и т.д.). Для этого чат-боты
проходят дополнительный, не менее важный, этап обучения, известный как обучение с
подкреплением на основе обратной связи от человека.
Сотрудники помечают бесполезные или проблемные предсказания, а их исправления вносят
изменения в параметры модели, повышая вероятность того, что её ответы будут
предпочтительнее для пользователя.
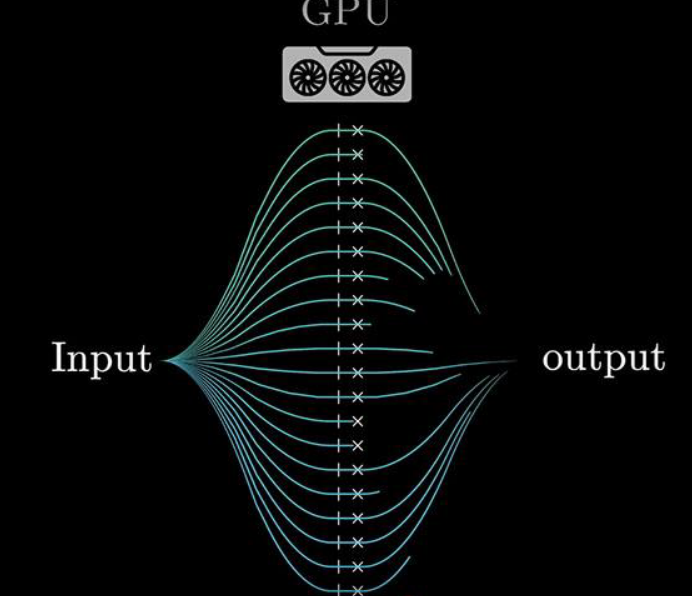
Если вернуться к предобучению, то колоссальный объём вычислений возможен только благодаря
использованию специальных компьютерных чипов, оптимизированных для выполнения
множества операций параллельно, известных как GPU или NPU.
Однако не все языковые модели легко поддаются параллелизации. До 2017 года большинство
языковых моделей обрабатывали текст по одному слову за раз, но затем исследователи из Google
представили новую модель, известную как трансформер.
Трансформеры не читают текст последовательно — они усваивают его весь сразу, параллельно.
Первый этап в работе трансформера, как и большинства языковых моделей, это привязка каждого
слова к длинному списку чисел.
Причина в том, что обучение модели возможно только с использованием непрерывных значений,
поэтому язык нужно представить в числовом формате, и каждый из этих списков чисел может
каким-то образом кодировать смысл соответствующего слова.
Главная особенность трансформеров — это применение специальной операции, известной как
внимание (Attention). Эта операция позволяет всем этим числовым спискам взаимодействовать
друг с другом и уточнять своё значение с учётом контекста, причём всё это происходит
параллельно.
Трансформеры, как правило, включают ещё один тип операции известный как полносвязная
нейросеть, которая позволяет модели запоминать больше языковых закономерностей, усвоенных
во время обучения.
Все эти данные многократно проходят через множество итераций этих двух базовых операций, и
каждая числовая последовательность обогащается, чтобы кодировать всю необходимую
информацию для точного предсказания следующего слова в тексте.
В финале выполняется последняя функция над последним вектором в этой последовательности,
который уже был скорректирован с учётом всего контекста входного текста, а также знаний,
полученных моделью во время обучения, для предсказания следующего слова.
Опять же, предсказание модели представляет собой распределение вероятностей для каждого
возможного следующего слова. Хотя исследователи разрабатывают структуру работы каждого из
этих шагов, важно понимать, что конкретное поведение модели формируется само по себе
в процессе обучения, в зависимости от настройки сотен миллиардов параметров.
Из-за этого крайне сложно точно определить, почему модель даёт именно такие предсказания.
Можно заметить что предсказания большой языковой модели при автодополнении запроса получаются удивительно плавными, захватывающими и даже полезными. Инициалы GPT означают Generative Pretrained Transformer или "Генеративный предобученный трансформер"."Генеративный" означает, что модель генерирует новый текст.
"Предобученный" означает, что модель была обучена на огромном количестве данных, а
приставка намекает на то, что её можно дообучить для конкретных задач с помощью
дополнительного обучения. "Трансформер" - это особый вид нейронной сети, лежащий в основе нынешнего бума в области искусственного интеллекта.
Выводы
Учитывая особенности работы LLM и моделей GPT, можно прийти к следующим выводам
относительно взаимодействия с ними через промптинг:
Не существует единственного «правильного» промпта для решения конкретной задачи — существует множество (десятки, а иногда и сотни) вариантов формулировок, способных привести к сходным результатам.
Из этого следует, что не существует универсальных правил, методов или принципов, которые бы
одинаково эффективно работали для всех типичных задач.
Поэтому единственным рабочим подходом остаётся экспериментальное комбинирование
различных приёмов промптинга — с целью
подобрать наиболее подходящую комбинацию под конкретную задачу.
Пример запроса:
Дай ссылку на исследование, подтверждающее, что [вставить факт из ответа ИИ]
Что проверять:
- Переходите по ссылке.
- Сравните текст с тем, что ИИ утверждал.
Фейк-признак: Неработающая ссылка, несуществующий DOI (уникальный цифровой
идентификатор научной или академической публикации), публикация не о том.
Существуют понятия "принципы и
методы" промптинга. Их используют или комбинируют друг с другом, для
получения нужных нам результатов от ИИ.
Промпт - это инструкция для нейронки. И как любая инструкция она должна быть:
- чёткой
- структурированной
-измеримой
Думайте о промпте как о вопросе, команде или инструкции, которую вы даете очень умному, но
при этом предельно буквально понимающему помощнику.
Если вы попросите его "сделать что-то красивое", он может нарисовать дерево или написать
стихотворение о закате — всё, что угодно, что он считает красивым. Если вы попросите "написать
песню для хорового пения о пользе утренней зарядки для подростков", он поймёт гораздо лучше.
Почему "правильный" промпт так важен.
Потому что он определяет качество вашего взаимодействия с ИИ. Плохой промпт — это прямой
путь к разочарованию. Что вы получите в итоге?
Неточные ответы.
ИИ может не понять вашей истинной цели и предоставить информацию, которая не соответствует
вашему запросу.
"Галлюцинации".
Это когда ИИ придумывает факты или данные, которых не существует, чтобы заполнить пробелы в
своем понимании. Чем расплывчатый промпт, тем больше простора для таких "фантазий".
Потеря времени.
Вам придется снова и снова переформулировать запрос, пытаясь добиться желаемого результата,
что тратит ваше время и ресурсы.
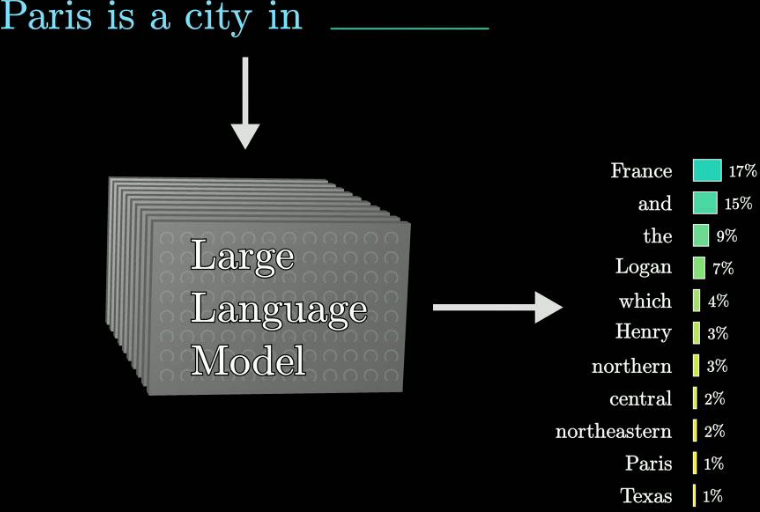
Фиг. 1 Как работает языковая модель
Фиг. 2 Изменения в параметры модели