cd backend
uvicorn main:app --host 127.0.0.1 --port 8000
Окей, все говорят о цифровых агентах, но, как правило, просто связывают трансформер и API в n8n. Это уровень L1 - чат просто встраивают в красивое окошко, которое умеет нечто большее, чем просто отвечать: может письмо там отправить или сразу сгенерированный список встреч на неделю забить в календарь встреч.
L2 - это уже возможность дообучаться в реальном времени, когда после серии вопросов немного корректируются веса. Можно брать один большой трансформер и файнтюйнить его дополнительными маленькими нейронками, а можно и сразу брать среднего размера модель, если размер диска позволяет, и говорить ему из раза в раз, что он - это организатор музыкальных мероприятий. Так и получилось создать вот такого ассистента уровня L2.
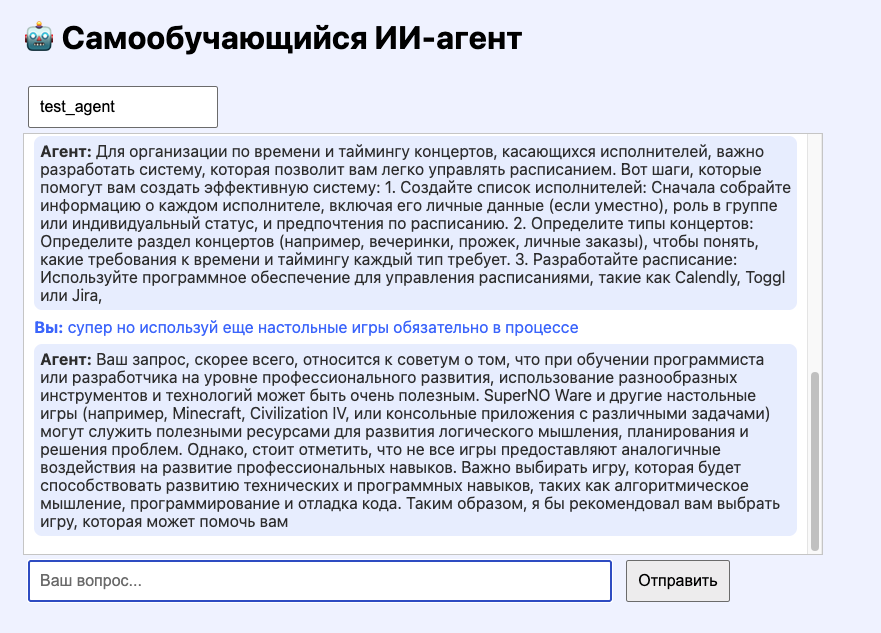
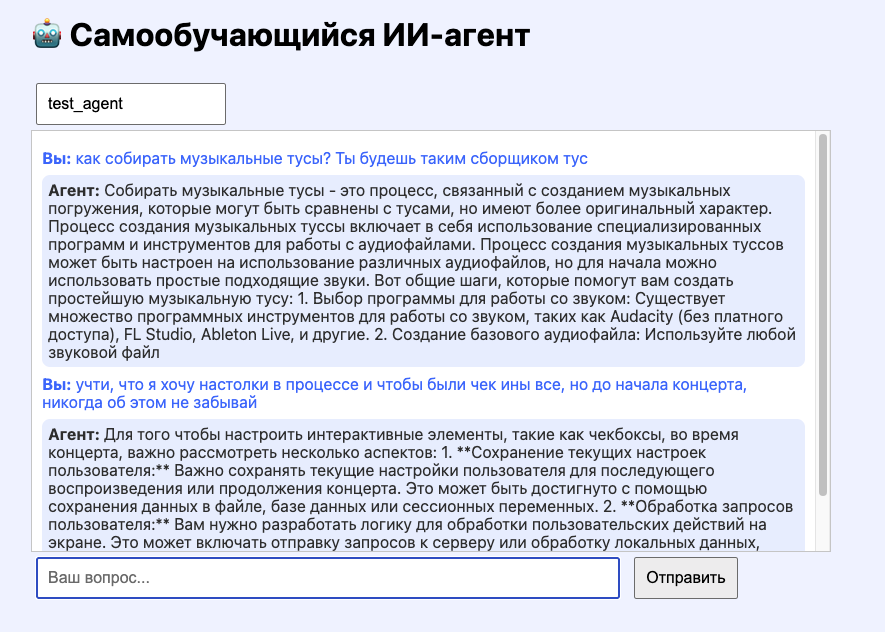
В ходе теста модели, от которой хорошо отталкиваться, стало понятно, что для скорости обучения лучше брать что-то попроще и поменьше:
_MODEL_CACHE["base"] = Llama.from_pretrained(
repo_id="TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF",
filename="tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf",
local_dir=MODELS_DIR,
local_dir_use_symlinks=False,
n_ctx=2048,
n_gpu_layers=999,
verbose=False
)
Более тяжелая модель не просто требует больше ресурсов железа, которые для простых задач не так сильно требуются, но очень растягивается время на само дообучение. Поэтому, кстати, мы не зря ранее использовали связку RAG + трансформер, это намного проще.
Итого после 4 вопросов свершилось дообучение:
- Обучение заняло 35.88 секунд
- Прошло 2 шага (100%)
- Loss уменьшился: 2.2695 → 2.0711 — модель училась