Целевая аудитория: Java-разработчики, использующие Spring Boot и работающие с реляционными или NoSQL базами данных.
Версия Java: 11
Цель статьи: понять архитектуру Spring Data, принципы её работы, механизмы генерации реализаций и интеграции с JPA/Hibernate.
Введение
Если вы когда-либо писали код вроде:

— и удивлялись, как это работает без реализации, то эта статья для вас.
Spring Data — это часть экосистемы Spring, которая автоматизирует доступ к данным, будь то реляционные (PostgreSQL, MySQL), документные (MongoDB), ключ-значение (Redis) или другие хранилища.
Но как она устроена «под капотом»? Почему интерфейс без реализации внезапно начинает работать? И что происходит при вызове findByEmail?
Разберёмся шаг за шагом.
1. Основные компоненты Spring Data
Spring Data состоит из нескольких уровней абстракции:
Уровень
Назначение
Spring Data Commons
Общая инфраструктура: Repository, CrudRepository, PagingAndSortingRepository, стратегии именования методов, поддержка QueryDSL и т.д.
Spring Data JPA
Конкретная реализация для JPA-совместимых СУБД (Hibernate, EclipseLink).
Spring Data MongoDB / Redis / Cassandra...
Реализации для других хранилищ.
💡 Ключевая идея: Spring Data Commons определяет единый контракт, а каждая модульная реализация (JPA, MongoDB и др.) предоставляет специфичную логику.
2. Интерфейс Repository и его иерархия
Все начинается с простого маркерного интерфейса:
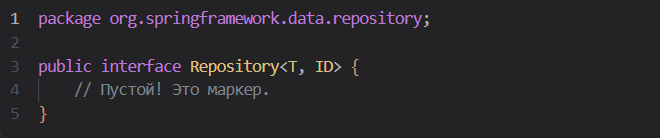
От него наследуются более функциональные интерфейсы:
✅ Практический совет: В большинстве случаев вы наследуетесь от JpaRepository, но если вам не нужны JPA-специфичные методы — достаточно CrudRepository.
3. Как Spring создаёт реализацию интерфейса?
Вы пишете:
public interface UserRepository extends JpaRepository<User, Long> {}
И в сервисе:
Ответ: Proxy и FactoryBean
Spring Data использует механизм динамической генерации реализаций во время запуска контекста.
Этапы:
- Сканирование: Spring находит все интерфейсы, расширяющие Repository.
- Регистрация бина: для каждого такого интерфейса регистрируется специальный FactoryBean.
- Создание прокси: при запросе бина (userRepository) Spring создаёт прокси-объект, который делегирует вызовы внутренней реализации.
Эта реализация зависит от модуля:
- Для JPA — это SimpleJpaRepository.
- Для MongoDB — SimpleMongoRepository.
🔍 Вы можете увидеть это в отладчике: тип userRepository будет com.sun.proxy.$Proxy123, а внутри — ссылка на SimpleJpaRepository.
4. Генерация запросов по имени метода
Одна из самых мощных фич Spring Data — query derivation (вывод запроса из имени метода).
Пример:
List<User> findByEmailAndActiveTrue(String email);
Spring Data разбирает имя метода:
- findBy — префикс (можно также getBy, readBy, queryBy).
- Email → поле email.
- And → логическое И.
- ActiveTrue → поле active = true.
Результат (для JPA):
SELECT u FROM User u WHERE u.email = ?1 AND u.active = true
6. Жизненный цикл операций: от вызова до SQL
Рассмотрим, что происходит при вызове:
userRepository.findById(1L);
- Вызов попадает в прокси-бин UserRepository.
- Прокси делегирует вызов SimpleJpaRepository.findById().
- Тот вызывает EntityManager.find(User.class, 1L).
- Hibernate (или другой провайдер JPA) выполняет SQL:
SELECT * FROM users WHERE id = 1;
Результат маппится в объект User.
Объект возвращается вашему коду.
🔁 Аналогично работают save(), delete() и другие методы — они используют стандартный JPA API.
10. Spring Data и Java 11: совместимость
Spring Data отлично работает с Java 11. Однако учтите:
- Используйте современные версии Spring Boot (2.7+, 3.x).
- Убедитесь, что ваш JPA-провайдер (обычно Hibernate) поддерживает Java 11.
- Избегайте устаревших API (например, javax.* в пользу jakarta.* в Spring Boot 3+).
📌 Если вы используете Spring Boot 2.x, зависимости всё ещё на javax.persistence.
В Spring Boot 3.x — переход на jakarta.persistence.
Заключение
Spring Data — это не «магия», а продуманная архитектура, сочетающая:
- Единый контракт (Repository).
- Динамическую генерацию реализаций.
- Интеллектуальный парсинг имён методов.
- Гибкую настройку через аннотации.
Понимание её устройства помогает:
- Писать более эффективные запросы.
- Отлаживать проблемы с производительностью.
- Расширять функциональность без костылей.
- Чувствовать себя уверенно при работе с любым хранилищем (JPA, MongoDB и др.).