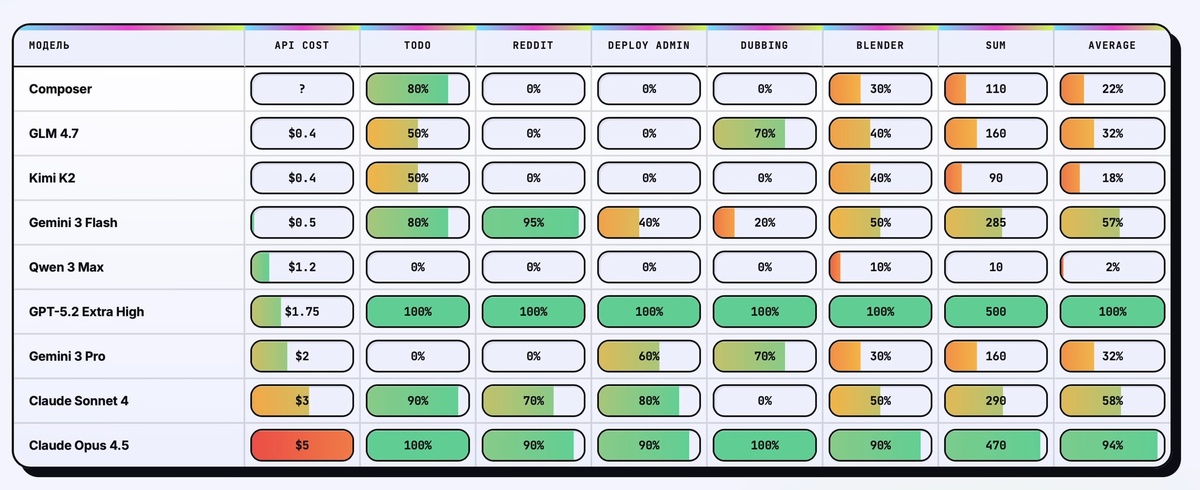
Свежий тест моделей нейросетей для вайбкодинга на реальных задачах
На канале 📱 Олега Стефанова вышел новый ролик где он комплексно сравнивает каждую модель на равных условиях в разных задачах. Результат вполне объективный, и, самое главное, полностью совпадает с моим топом, который последний месяц жестко зафиксировался и ставит GPT 5.2 в безоговорочные лидеры.
Топ моделей:
👑 GPT‑5.2 Extra High
2️⃣ Claude Code Opus 4.5
3️⃣ Claude Code Sonnet 4.5 (на скрине очепятка)
4️⃣ Gemini 3 Flash
5️⃣ Gemini 3 Pro
6️⃣ GLM 4.7
7️⃣ Composer
8️⃣ Kimi K2
9️⃣ Qwen 3 Max
Самое важное часто упускается, когда мы сравниваем GPT и Claude Code, а это количество денежных средств, затраченных на решение проблемы. Токены считать смысла нет без привязки к тарифам. Так что 1,75$ у GPT против 5$ у Opus является жирной точкой в сравнении данных моделей.
Конечно, выборка для теста смешная, но даже тех примеров, что были на видео, с головой достаточно, чтобы выявить слабые и сильные стороны каждой модели, я уверяю.
То, что GPT метит в топы, было ясно еще с 5.1 версии, уже тогда они значительно бустанули модель. Ждем релизов от Anthropic, уверен, что скоро представят что-то интересное.