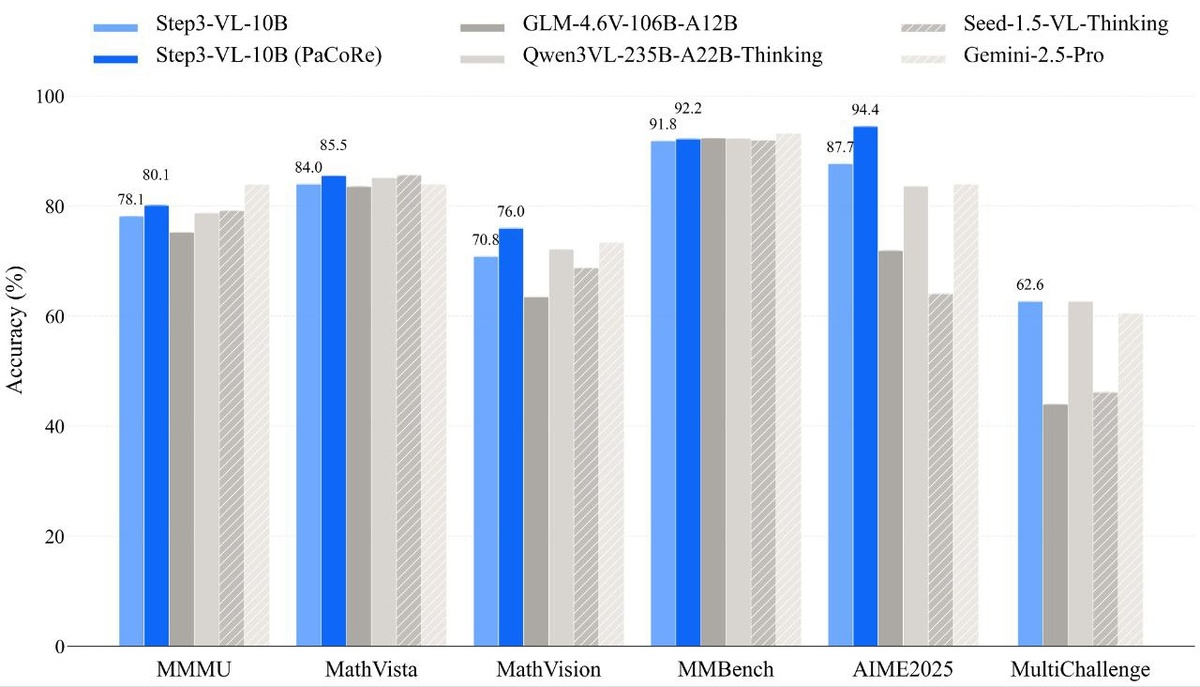
StepFun выкатили Step3-VL-10B: открытая мультимодалка на 10B, которая по бенчам лезет в драку с моделями в 10–20× крупнее (GLM-4.6V, Qwen3-VL и даже рядом с Gemini 2.5 Pro/Seed).
Что заявляют по цифрам
(SeRe / PaCoRe):
✅ MMMU: 78.11 → 80.11
✅ MathVista: 83.97 → 85.50
✅ MathVision: 70.81 → 75.95
✅ MMBench (EN): 92.05 → 92.38
✅ OCRBench: 86.75 → 89.00
✅ AIME 2025: 87.66 → 94.43
Главная фишка тут в режиме параллельного рассуждения: модель не “думает” одним единственным ходом, а гоняет несколько вариантов рассуждения параллельно, вытаскивает из них подтверждения и уже потом собирает финальный ответ. За счёт этого она стабильнее в задачах, где обычно всё рассыпается: математика по картинке, OCR, понимание экранов и интерфейсов, длинные многошаговые вопросы. Плюс заявлен длинный контекст (до 128K), чтобы не задыхаться на больших промптах.
Ссылки: HF Base: https://huggingface.co/stepfun-ai/Step3-VL-10B-Base
ModelScope Base: https://modelscope.cn/models/stepfun-ai/Step3-VL-10B-Base
#AI #VLM #Multimodal #OpenSource #StepFun #Step3VL #OCR #Reasoning #Agents