Вероятностное обучение вместо точной подгонки может изменить экономику ИИ.
Китайские исследователи предложили, пожалуй, один из самых «вайбкодинговых» подходов к обучению нейросетей за последние годы. В работе, опубликованной в Nature Communications, команда из Чжэцзянского и Фуданьского университетов показала, как отказаться от навязчивой точности и научить мемристоры обучать ИИ на интуиции и вероятности, снижая энергопотребление почти на шесть порядков по сравнению с GPU.
Метод получил название EaPU (Error-aware Probabilistic Update) — вероятностное обновление с осознанностью ошибок. Идея проста, но радикальна: если «железо» шумит, не пытайся его переупрямить — подстрой под него сам алгоритм.
Мемристоры: мозг хочет, алгоритм — нет
Мемристоры давно выглядят как идеальные кандидаты для аналогового ИИ. Они хранят вес и одновременно участвуют в вычислениях, напоминая биологические синапсы. Матричные операции выполняются напрямую в памяти — без бесконечных перегонов данных, которые сегодня сжигают энергию в дата-центрах.
На этапе вывода всё это уже работает: эксперименты IBM, Stanford и других показывают впечатляющую энергоэффективность. Но обучение глубоких сетей упирается в фундаментальный конфликт:
- алгоритмы требуют микроскопических, точно рассчитанных обновлений весов;
- мемристоры обновляются грубо, шумно и со временем «плывут».
Это как пытаться настроить радио сломанной ручкой: вместо аккуратного щелчка получаются хаотичные скачки.
Вайбкодинг вместо микроменеджмента
Большинство предыдущих решений шло по одному из двух путей:
- либо жертвовать точностью,
- либо тратить море энергии, заставляя мемристоры «попадать в точку».
EaPU выбирает третий путь — принять неопределённость как данность.
Ключевое наблюдение команды: в реальных нейросетях большинство обновлений весов в 10–100 раз меньше, чем собственный шум мемристоров. Эти обновления всё равно «тонут» в хаосе.
Поэтому EaPU делает следующее:
- маленькие обновления не пишутся напрямую;
- вместо этого применяется крупный пороговый импульс — но с вероятностью, пропорциональной нужному изменению;
- либо обновление просто пропускается.
В среднем веса сходятся туда же, куда и при классическом backpropagation, но без попыток контролировать каждый электрон. Это и есть чистый вайбкодинг: не контролировать каждое движение, а управлять статистикой.
99,9% обновлений — в мусорку
Побочный эффект оказался ошеломляющим. EaPU сокращает число физических записей весов более чем на 99%.
Для ResNet-152:
- обновления требовались лишь 0,86 параметра на тысячу на каждом шаге обучения;
- остальные веса просто «оставались в покое».
Это сразу даёт три эффекта:
- резкое снижение энергопотребления;
- рост стабильности обучения;
- увеличение срока службы мемристоров примерно в 1000 раз.
Проверка реальностью, а не только симуляциями
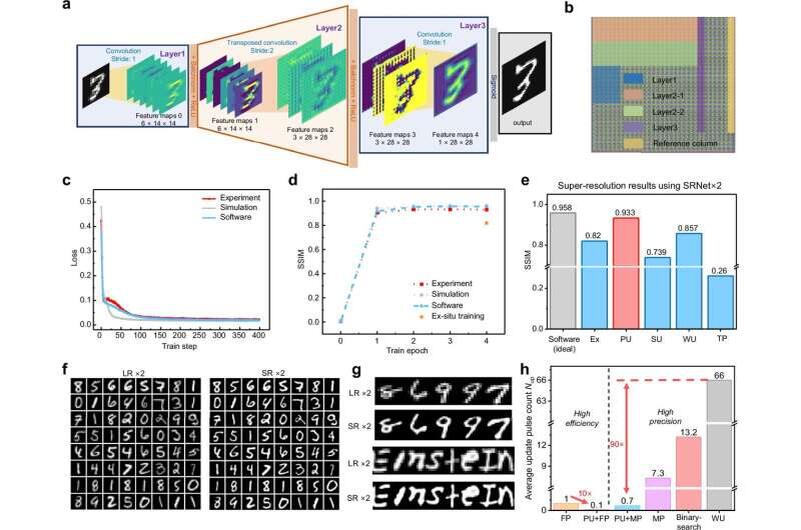
Метод протестировали не только на моделях, но и на реальном железе — 180-нм мемристорных массивах. На задачах подавления шума и сверхразрешения система достигла показателей структурного сходства (SSIM) 0,896 и 0,933, сопоставимых или лучших, чем у традиционного обучения — но при кратно меньших энергозатратах.
Для крупных моделей, которые пока невозможно полностью реализовать в железе, использовались симуляции, основанные на экспериментальных данных. Там EaPU:
- успешно обучил ResNet до 152 слоёв;
- показал значительный прирост точности для Vision Transformers;
- превзошёл стандартный backpropagation на шумном оборудовании более чем на 60% по точности.
Экономика ИИ меняется
В цифрах эффект выглядит ещё жёстче:
- в 50 раз меньше энергии по сравнению с предыдущими методами обучения на мемристорах;
- в 13 раз меньше, чем у продвинутого метода MADEM;
- и почти на шесть порядков экономичнее GPU при обучении.
Для индустрии, где обучение крупных моделей уже измеряется мегаватт-часами и миллионами долларов, это не оптимизация — это смена парадигмы.
Что дальше
Авторы подчёркивают, что EaPU — не эксклюзив для мемристоров. Метод можно адаптировать для:
- ферроэлектрических транзисторов,
- MRAM,
- других шумных аналоговых вычислительных платформ.
Отдельный и самый интригующий вектор — обучение крупных языковых моделей. Низкая частота обновлений означает меньший износ оборудования и радикально более низкое энергопотребление.
Вывод: EaPU показывает, что будущее энергоэффективного ИИ — не в борьбе с физикой, а в умении кодировать «по вайбу». Когда алгоритм перестаёт требовать невозможной точности от железа, масштабирование ИИ перестаёт быть энергетическим кошмаром.
Источник: https://techxplore.com/news/2026-01-memristor-method-slashes-ai-energy.html
Больше интересного – на медиапортале https://www.cta.ru/