Автор: Денис Аветисян
Представлена семейство открытых моделей HeartMuLa, способных создавать продолжительные музыкальные композиции с беспрецедентным контролем и эффективностью.
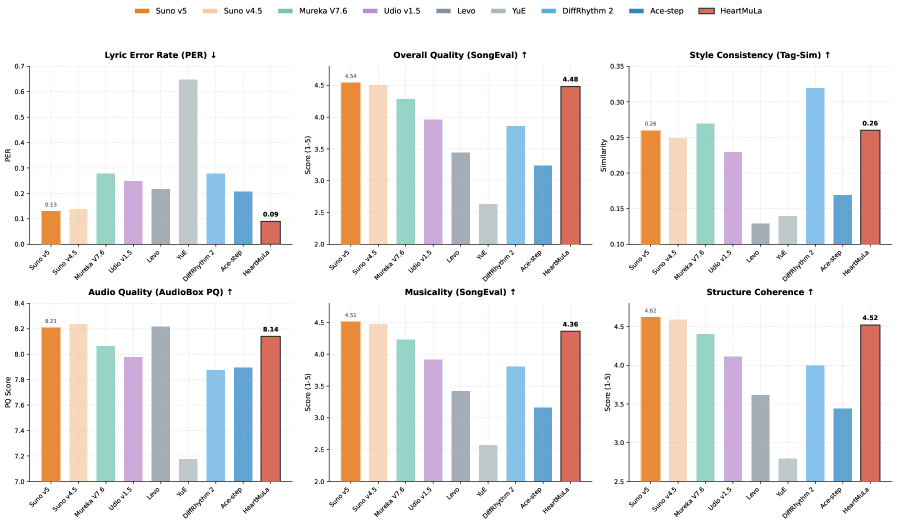
HeartMuLa использует иерархическое аудио-языковое моделирование с ультра-низкочастотными музыкальными токенами для эффективной генерации длинных музыкальных фрагментов.
Несмотря на значительный прогресс в области генерации музыки, создание открытых и контролируемых моделей, способных к долгосрочному синтезу, остается сложной задачей. В данной работе представлена семейство моделей HeartMuLa: A Family of Open Sourced Music Foundation Models, включающее в себя инструменты для выравнивания аудио и текста, распознавания текстов песен, кодирования музыки с низкой частотой кадров и, наконец, генерации музыки на основе больших языковых моделей. Ключевым достижением является создание эффективного и контролируемого фреймворка для генерации высококачественной музыки с учетом различных параметров, от текстового стиля до референсного аудио. Какие новые возможности для мультимодального контента и исследований в области искусственного интеллекта откроет эта платформа?
Музыка и Слова: Преодолевая Разрыв в Понимании Искусственного Интеллекта
Традиционные методы извлечения информации из музыки часто сталкиваются с трудностями при распознавании тонких смысловых нюансов, обрабатывая аудиосигнал как простой набор волн. Для эффективной генерации музыки и поиска композиций по текстовым запросам, например, по содержанию текстов песен, необходима точная связь между музыкой и текстом, что представляет собой серьезную задачу. Современные подходы зачастую не способны уловить сложные взаимосвязи между музыкальным содержанием и его словесным описанием, упуская из виду эмоциональную окраску, контекст и подтекст, которые делают музыку осмысленной и близкой человеку. В результате, искусственный интеллект испытывает трудности в интерпретации музыкальных произведений и создании осмысленных музыкальных текстов.
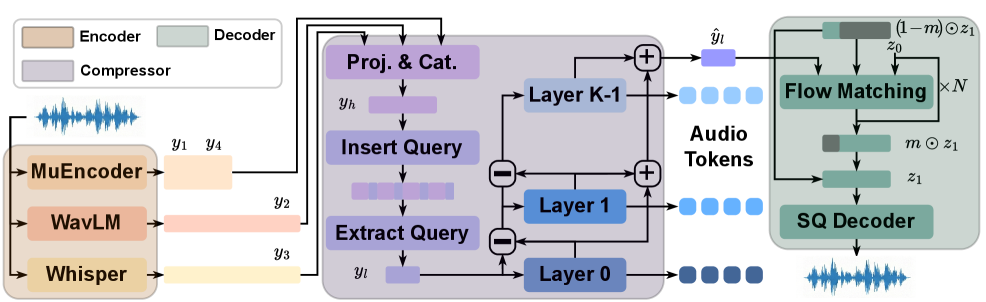
Музыкальный код: Основа для универсального искусственного интеллекта
Представлена платформа HeartMuLa, объединяющая передовые методы для эффективного анализа и генерации музыкального контента. В основе системы лежит представление звука в виде дискретных единиц, что позволяет значительно упростить процесс обучения и создания музыки искусственным интеллектом. Ключевым компонентом является HeartTranscriptor - система, способная точно распознавать текст песен, а также HeartCLAP, обеспечивающий согласование между текстом и музыкой. Благодаря такому подходу, HeartMuLa открывает новые возможности в области музыкального ИИ, позволяя создавать и анализировать музыку с беспрецедентной эффективностью и точностью.
Музыка в цифровом коде: компактное представление звука
В основе разработки HeartMuLa лежит принципиально новый подход к представлению аудио, использующий технологию Residual Vector Quantization (RVQ) и модели вроде MuCodec. Этот метод позволяет сжать музыкальную информацию, выделив наиболее важные элементы и представив их в виде дискретных, легко обрабатываемых “токенов”. Такое кодирование не только значительно снижает вычислительную нагрузку при работе с музыкой, но и открывает возможности для более эффективного анализа и манипулирования звуком. Для достижения высокого качества реконструированного звука применяются такие техники, как Flow Matching, позволяющая плавно восстанавливать аудиосигнал, а также Autoencoders - нейронные сети, способные эффективно сжимать и восстанавливать информацию, обеспечивая максимальную детализацию и естественность звучания.
Раскрывая смысл музыки без учителя
Современные модели машинного обучения, такие как WavLM и HuBERT, способны извлекать глубокое понимание музыкального контента, анализируя лишь саму музыку, без необходимости в ручной разметке. Этот подход, известный как самообучение, позволяет моделям самостоятельно находить закономерности и структуру в звуковых волнах, подобно тому, как человек учится понимать музыку, просто слушая её. Обучаясь на огромных объемах неразмеченных аудиозаписей, эти системы формируют надежные представления о музыкальном содержании. Такая предварительная самообучающаяся тренировка значительно повышает эффективность в решении различных задач, включая синхронизацию музыки с текстом и даже создание новой музыки, демонстрируя потенциал искусственного интеллекта в понимании и воспроизведении музыкального творчества.
Музыка по запросу: новый уровень контроля над генерацией
Разработана новая платформа HeartMuLa, позволяющая с беспрецедентной точностью сопоставлять музыку и текстовые описания. В основе лежит методика контрастного обучения, реализованная в HeartCLAP, которая обеспечивает точное соответствие между желаемыми характеристиками музыки, заданными в виде простого текстового запроса, и генерируемым музыкальным произведением. Эта технология позволяет пользователям управлять процессом создания музыки, указывая конкретные параметры и стили. Полученная модель демонстрирует передовые результаты, превосходя существующие аналоги, такие как Laion-CLAP и MuQ-MuLan, по показателям точности поиска релевантных музыкальных фрагментов и общей эффективности. При этом, скорость генерации музыки значительно увеличена - в 5.4 раза быстрее, чем у предыдущих систем, что открывает новые возможности для создания музыки в реальном времени и персонализированного музыкального контента.
Изучение HeartMuLa подтверждает давно известную истину: системы не создаются, они взращиваются. Авторы стремятся к контролю над генерацией музыки, используя иерархическое языковое моделирование и низкочастотные токены. Однако, подобно любым сложным структурам, HeartMuLa - это компромисс, застывший во времени. Ключевой аспект - эффективность генерации длинных музыкальных фрагментов - лишь одна грань системы, чья истинная сложность проявится в непредсказуемых взаимодействиях. Как говорил Клод Шеннон: «Информация - это не количество материи, а ее организация». В данном случае, организация музыкальных токенов - ключ к успеху, но и источник будущих ограничений. Стремление к контролю - благородно, но иллюзорно; система всегда найдёт способ проявить свою волю.
Что Дальше?
Представленная работа, как и любая попытка обуздать сложность музыкального потока, лишь аккуратно отодвинула горизонт нерешенных задач. Архитектура, основанная на иерархическом моделировании аудио, представляется неизбежной, но каждая новая ступень абстракции - это новое пророчество о будущих артефактах. Уменьшение частоты дискретизации до ультранизких значений - элегантное решение для масштабирования, однако оно же - обещание неизбежной потери нюансов, которые, возможно, и составляют суть музыки.
Контролируемая генерация - это мираж. Любой параметр, добавленный для "управления", неминуемо порождает новые, непредсказуемые взаимодействия. Модель, способная генерировать длинные музыкальные формы, неминуемо породит и длинные цепочки ошибок, которые невозможно предвидеть. Каждый деплой - маленький апокалипсис, и каждая новая версия - это лишь отсрочка неизбежного.
Вопрос документации кажется наивным. Кто пишет пророчества после их исполнения? Скорее, стоит задаться вопросом о создании систем, способных к самовосстановлению, к адаптации к неизбежным сбоям, к обучению на собственных ошибках. Ибо экосистемы не строятся, они вырастают, и в этом их хрупкая, но завораживающая красота.
Полный обзор с формулами: denisavetisyan.com/serdcze-muzyki-otkrytye-modeli-dlya-sozdaniya-kompoziczij
Оригинал статьи: https://arxiv.org/pdf/2601.10547.pdf
Связаться с автором: linkedin.com/in/avetisyan