
Если в столбце есть пустые строки, пробелы и “пусто” как текст — Excel легко покажет вам красивое, но неправильное число “уникальных”. В итоге отчёт не сходится, категории “размножаются”, а пустые то считаются, то исчезают.
В этой статье вы получите 3 рабочих способа (от самого простого до более “железобетонного”) и сможете посчитать уникальные значения, включая пустые, без сюрпризов.
Внутри:
- как быстро посчитать через сводную;
- как сделать формулами в Excel 2016 (без динамических массивов);
- как собрать устойчивый вариант в Power Query;
- типовые ошибки и проверки результата.
Оглавление
- Что получим на выходе
- Мини-данные для повтора (копируй-вставляй)
- Шаг 0: приводим “пустые” и пробелы к порядку
- Способ 1: сводная таблица (быстро и наглядно)
- Способ 2: формулы Excel 2016 (контрольный, без PQ)
- Способ 3: Power Query (самый стабильный для регулярных отчётов)
- Артефакт пользы: шпаргалка “ситуация → решение”
- Типовые ошибки и как не сломать
- Применение в реальной задаче аналитика
- Вариации/улучшения
- Проверка результата
- Финал и следующий выпуск серии
Аналитика без боли #1
(серия про Excel / Power Query / BI / SQL для тех, кто работает с данными)
Что получим на выходе
На выходе у вас будет количество уникальных значений в столбце и количество пустых — так, чтобы:
- “Москва”, “москва” и “Москва ” не считались разными категориями (если вы так хотите);
- пустые строки не исчезали “по настроению”;
- вы могли повторять расчёт на новых выгрузках без ручной уборки.
Результаты:
- Unique_non_empty — уникальные непустые значения;
- Empty_count — количество пустых;
- (опционально) Unique_including_empty — уникальные с учётом “Пусто” как отдельной категории.
Пошаговый разбор
Шаг 1. Мини-данные (копируй-вставляй)
Создайте в Excel таблицу из двух колонок: id и category. Вставьте данные:
id category
1 Москва
2 Москва
3 москва
4 Санкт-Петербург
5
6
7 Пусто
8 пусто
9 Казань
10 Казань
Что здесь специально “вредное”:
- строка 2: пробел в конце (“Москва ”);
- строки 5–6: пустая и “пустая из пробелов”;
- строки 7–8: “Пусто” как текст, причём в разном регистре.
Шаг 2. Шаг 0 (обязательный): создаём “нормализованную” категорию
Перед любым подсчётом делаем столбец, который убирает “мусор”.
Рядом добавьте колонку category_norm и в первой строке данных (например, C2) поставьте формулу:
=ЕСЛИ(СЖПРОБЕЛЫ(B2)="";"";СТРОЧН(СЖПРОБЕЛЫ(B2)))
Что делает формула:
- СЖПРОБЕЛЫ убирает лишние пробелы и превращает строку из пробелов в пустую;
- СТРОЧН приводит к нижнему регистру (чтобы “Пусто” и “пусто” были одним значением);
- ЕСЛИ(...="";"";...) оставляет пустые пустыми, не превращая их в “0” или “ЛОЖЬ”.
Протяните формулу вниз.
Зачем так:
Если не нормализовать, Excel честно посчитает “Москва” и “Москва ” как две разные категории — и формально он будет прав.
Шаг 3. Способ 1: сводная таблица (самый быстрый)
Подходит, если нужен ответ “здесь и сейчас” и вы не против кликать мышкой.
Действие:
- Выделите таблицу с данными.
- Вставка → Сводная таблица.
- В поля сводной:
category_norm → Строки
id → Значения (подсчёт)
Как получить “уникальные” и “пустые”:
- Уникальные непустые = количество строк в сводной без пустой строки.
- Пустые = строка “(пусто)” (если она появилась) и её значение.
Важно: сводная иногда прячет “(пусто)” в зависимости от настроек/фильтров. Если не видите пустые:
- Откройте фильтр по category_norm в строках и проверьте, не снята ли галочка “(пусто)”.
Зачем так:
Сводная — самый простой способ увидеть распределение и сразу понять, “что считается” категориями.
Шаг 4. Способ 2: формулы Excel 2016 (контрольный, без Power Query)
Это вариант, когда вы хотите получить числа в ячейках и не зависеть от сводной.
4.1. Считаем пустые
Если category_norm в диапазоне C2:C11, пустые:
=СЧЁТЕСЛИ(C2:C11;"")
4.2. Считаем уникальные непустые (через “вес” первых вхождений)
В Excel 2016 нет удобной UNIQUE(), поэтому делаем классический приём через СЧЁТЕСЛИ.
В ячейке, где нужен результат, используйте формулу массива (важно!):
- Введите формулу:
=СУММ(ЕСЛИ(C2:C11<>"";1/СЧЁТЕСЛИ(C2:C11;C2:C11);0))
- Нажмите Ctrl+Shift+Enter (а не просто Enter).
Excel возьмёт формулу в фигурные скобки {} — руками не ставьте.
Результат может быть дробным из-за вычислений, но итог обычно целый. При необходимости:
=ОКРУГЛ(СУММ(ЕСЛИ(C2:C11<>"";1/СЧЁТЕСЛИ(C2:C11;C2:C11);0));0)
Зачем так:
Мы складываем “вклад” только первых вхождений (1/частота). Для каждой уникальной категории сумма даст 1.
Шаг 5. Способ 3: Power Query (самый стабильный для регулярных выгрузок)
Если у вас отчёт повторяется, а данные “грязные” каждый раз — PQ выигрывает.
Действие (логика, без излишней теории):
- Превратите диапазон в таблицу (Ctrl+T).
- Данные → Из таблицы/диапазона (откроется Power Query).
- Добавьте шаг очистки category:
Преобразование → Формат → Очистить (если доступно)
Преобразование → Формат → Усечь (Trim)
Преобразование → Формат → В нижний регистр - Замените пустые строки из пробелов на null (если после trim стало пусто):
Добавьте пользовательский столбец category_norm:
если Text.Trim([category]) = "" → null
иначе Text.Lower(Text.Trim([category])) - Для уникальных непустых:
Отфильтруйте null в category_norm
Удалите дубликаты по category_norm
Посчитайте строки (или загрузите результат как таблицу уникальных) - Для пустых:
Отфильтруйте null
Посчитайте строки
Пример “псевдо-M” логики (читаемо):
category_norm =
if Text.Trim([category]) = "" then null
else Text.Lower(Text.Trim([category]))
Зачем так:
Power Query делает очистку и правила единообразными. Вы просто обновляете запрос — и получаете те же корректные числа на новой выгрузке.
4.3) Артефакт пользы: шпаргалка “ситуация → решение”
Сохраните — это как раз то, что пригодится снова через неделю.
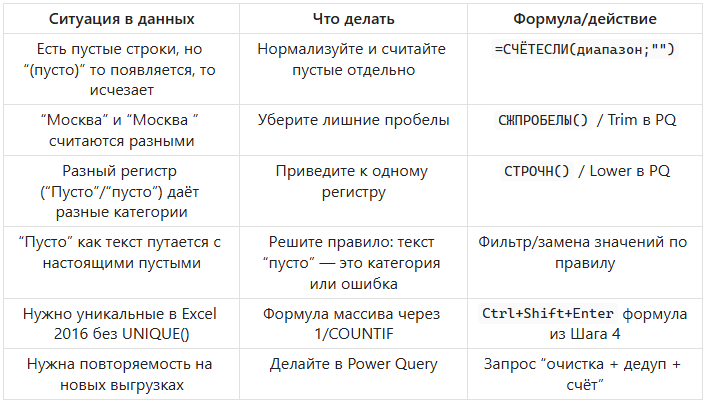
Типовые ошибки и как не сломать (5 пунктов)
- Считаете уникальные по “сырому” столбцу.
Исправление: добавьте category_norm (trim + lower + пустые в ""/null). - Путаете пустые и текст “Пусто”.
Исправление: заранее определите правило: “Пусто” — это реальная категория или “ошибка ввода”. Дальше либо оставляйте как категорию, либо заменяйте на null. - Формула массива введена обычным Enter.
Исправление: Excel 2016 требует Ctrl+Shift+Enter, иначе результат будет неверным или странным. - Диапазон “плавает”, вы считаете не те строки.
Исправление: используйте “умную” таблицу (Ctrl+T) или фиксированные диапазоны на время проверки. - В Power Query забыли типы/обновление, и цифры не совпадают.
Исправление: после преобразований проверьте, что category_norm — текст, и обновляйте запрос перед сверкой.
4.5) Применение в реальной задаче аналитика (2 сценария)
- Отчёт по категориям обращений/инцидентов.
Нормализация убирает “размножение” категорий из-за пробелов и регистра, а отдельный счёт пустых показывает качество заполнения (сколько записей пришло без категории). - Сверка двух выгрузок от разных систем.
Один и тот же справочник “категорий” может быть записан по-разному. category_norm делает сравнение корректным, и вы видите реальную разницу, а не “Москва ” vs “Москва”.
Вариации/улучшения (3 идеи)
- Словарь синонимов: “СПб” → “санкт-петербург”, “мск” → “москва” (особенно для ручного ввода).
- Контроль качества: доля пустых = Empty_count / total_rows и порог тревоги (например, >5%).
- Отдельная витрина уникальных значений: выгружайте список уникальных category_norm как справочник для BI/SQL.
Проверка результата (4 проверки)
- Контроль суммы: Empty_count + NonEmpty_count = Total_rows (где NonEmpty_count = всего строк минус пустые).
- Сверка способов: сводная vs формулы vs PQ должны дать одинаковые Unique_non_empty и Empty_count.
- Тест на пробелы: добавьте “Москва ” и убедитесь, что после нормализации она не создаёт новую категорию.
- Тест на “пусто как текст”: “Пусто” должно считаться как категория (если вы так решили) и не попадать в пустые.
Финал
Теперь вы умеете считать уникальные значения в столбце так, чтобы результат был устойчивым, и отдельно видеть пустые — без сюрпризов из-за пробелов, регистра и “пусто как текста”.
Если было полезно для работы с данными — сохраните статью (эти приёмы всплывают чаще, чем хочется) и подпишитесь, чтобы не пропустить продолжение серии.