Часто работаешь со строками в Python и пишешь одну проверку за другой? Значит, пора познакомиться с регулярными выражениями. Вместо ручной возни ты задаёшь шаблон поиска — и Python сам находит, что нужно. Вот пять жизненных примеров, когда модуль re прокачивает даже простой скрипт до уровня умного инструмента.
Проверь любого пользователя: ловим хитрые данные за пару секунд
Валидация пользовательских данных без re обычно превращается в длинные и неудобные условия. Например, если нужно проверить, что имя соответствует правилам:
Столкнёшься с этим не раз. Вот типичный вариант на голом Python без re:
Такой код, конечно, работает, но с каждым новым правилом разрастается и усложняется, а разобраться в нём — целая история. Вот тут и приходит спасение: регулярным выражением ты всё задаёшь одной строкой через re.compile() — и используешь шаблон без лишней боли.
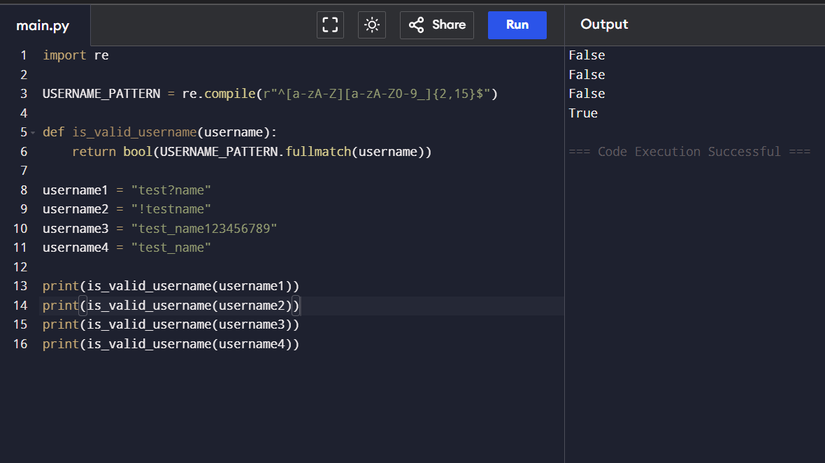
Давай разберёмся, в чём тут фокус.
Как только попробуешь валидировать с re, возвращаться к длинным if-цепочкам не захочется: правила описал — Python всё остальное возьмёт на себя.
6 причин, почему интерактивный Python перевернул моё представление о программировании
Нет опыта? Это не проблема!
Добывай смысл из хаоса: как быстро вытаскивать данные из грязного текста
Почти в любом Python-проекте однажды появляется «грязный» текст: логи, дампы, e-mail, HTML — примеров масса. И каждый раз хочется найти в этом беспорядке структуру, не превращая код в свалку костылей.
Например, у тебя есть лог-файл — нужно вытащить из каждой строки время и сообщение об ошибке. Вот пример строки:
Скорее всего, ты начнёшь с чего-то вроде этого:
Работает… пока не изменится формат. Пропущенный пробел, лишняя скобка или другая деталь — и всё ломается. Главное — такие пляски нагромождают код и прячут всю логику. С re ты чётко формулируешь, что ищешь, и забываешь о split и индексах.
Здесь уже явно указано: ищи временную метку в скобках, дальше ERROR, а потом — текст ошибки.
Грязный текст уйдёт за секунду: нормализация одной командой
Обработка текста кажется пустяком, пока не натыкаешься на случайные пробелы, разные разделители, левые символы и форматирование. Всё это быстро превращает обработку данных в головоломку.
Например, тебе нужно привести введённый пользователем текст к порядку — перед сохранением или сравнением. Вот твои условия:
Обычный способ без re — это масса циклов, if-условий и replace для каждого случая по отдельности:
Тоже вариант, но только код становится всё длиннее и запутаннее. Добавилось новое требование — ищи и редактируй лишний раз.
А теперь смотри, как re.sub() одной командой чистит любой беспорядок в тексте:
Результат тот же — но код проще и читается в разы легче.
7 приёмов для работы с текстовыми файлами на Python — экономь своё время
Забудь о рутинной трате времени — автоматизируй обработку текстов с помощью Python.
Умные замены: найди и измени только то, что важно
Все знают про str.replace() — просто, но слишком прямолинейно. Как только требуется замена только в подходящем контексте, он бессилен. Если нужно обрабатывать куски выборочно — str.replace() уже не справляется.
Допустим, у тебя есть логи или база с личной информацией, и надо скрыть e-mail адреса перед публикацией.
Задача: показать только домен, а имя пользователя замаскировать.
Сделать это стандартными методами сложно — разные пробелы, сложные адреса, куча условий, а код терпит кучу правок.
С re.sub() ты находишь любой e-mail, разбиваешь его на части и за одну команду подменяешь только что нужно — с помощью групп и обратных ссылок.
Вот так re находит e-mail в любом виде, разбивает и изменяет только нужную часть через 2. Получается не просто массовая замена, а умный подход к задаче.
Полусырые данные? re справится без split и лишней головоломки
Даже если структура слегка хромает — модуль re спасает. Допустим, тебе достались строки вот такого вида:
Задача — превратить строку в словарь. Формат вроде бы повторяется, но порядок и пробелы скачут, часть ключей может пропасть. Обычно сразу хочется применить split():
Поначалу работает, но чуть что изменилось — поиск и обработка переплетаются и всё усложняется.
Подпишись и забирай лучшие приёмы и шаблоны для regex в Python!
А если использовать re.findall(), можно чётко описать шаблон и вытянуть все пары ключ=значение за один проход.
Весь формат задаёшь одним шаблоном: ключ (слово), знак равенства, значение без пробелов. re соберёт все пары за один раз.
8 сценариев для Python os — автоматизируй по-взрослому
Познакомься с настоящим мостом между Python и ОС.
Если ты до сих пор обходишь регулярные выражения стороной, начни с простого. Попробуй re.fullmatch() для валидации, используй re.sub() для очистки текста. Как только освоишь шаблоны — сам удивишься, насколько твой код станет проще и короче.
Если вам понравилась эта статья, подпишитесь, чтобы не пропустить еще много полезных статей!
Премиум подписка - это доступ к эксклюзивным материалам, чтение канала без рекламы, возможность предлагать темы для статей и даже заказывать индивидуальные обзоры/исследования по своим запросам!Подробнее о том, какие преимущества вы получите с премиум подпиской, можно узнать здесь
Также подписывайтесь на нас в:
- Telegram: https://t.me/gergenshin
- Youtube: https://www.youtube.com/@gergenshin
- Яндекс Дзен: https://dzen.ru/gergen
- Официальный сайт: https://www-genshin.ru