
Стек: Java 11+
Цель: понять, что такое ForkJoinPool, как он работает под капотом, когда его использовать — и когда лучше не трогать.
🔍 Введение: зачем нужен ForkJoinPool?
Представьте: вам нужно обработать огромный массив данных, найти сумму, отсортировать, применить сложную функцию.
Вы можете сделать это последовательно — но это медленно.
Или разбить задачу на подзадачи, выполнить их параллельно — и собрать результат.
Именно для таких рекурсивно разделяемых задач (divide-and-conquer) и был создан ForkJoinPool — особый пул потоков, введённый в Java 7 и улучшенный в последующих версиях (включая Java 11).
Что такое ForkJoinPool? Основные идеи
ForkJoinPool — это специализированный ExecutorService, оптимизированный для выполнения большого числа мелких задач, которые могут:
- «Разветвляться» (fork) — создавать подзадачи,
- «Собираться» (join) — ждать результат подзадач.
Ключевые особенности:
Особенность
Объяснение
Work-stealing
Потоки «крадут» задачи у других, если их собственная очередь пуста → максимальная загрузка CPU.
Рекурсивная декомпозиция
Идеально для задач вроде quickSort, map, reduce.
Число потоков ≈ числу ядер
По умолчанию: ForkJoinPool.commonPool() использует Runtime.getRuntime().availableProcessors() - 1 потоков.
Не для блокирующих задач
Если задача ждёт I/O, сеть, БД — ForkJoinPool неэффективен (лучше обычный ThreadPoolExecutor).
Как работает ForkJoinPool: архитектура
Каждый поток в ForkJoinPool имеет свою двустороннюю очередь (deque):
- Новые подзадачи добавляются в хвост очереди.
- Поток забирает задачи из головы своей очереди.
- Если очередь пуста — поток «крадёт» задачу из хвоста чужой очереди (work-stealing).
💡 Это минимизирует конкуренцию и балансирует нагрузку без блокировок.
Как использовать ForkJoinPool в Java 11
Есть два основных способа:
Способ 1️⃣: Использовать общий пул (ForkJoinPool.commonPool())
Подходит для лёгких, неблокирующих задач, особенно с CompletableFuture (по умолчанию CompletableFuture использует именно его!).
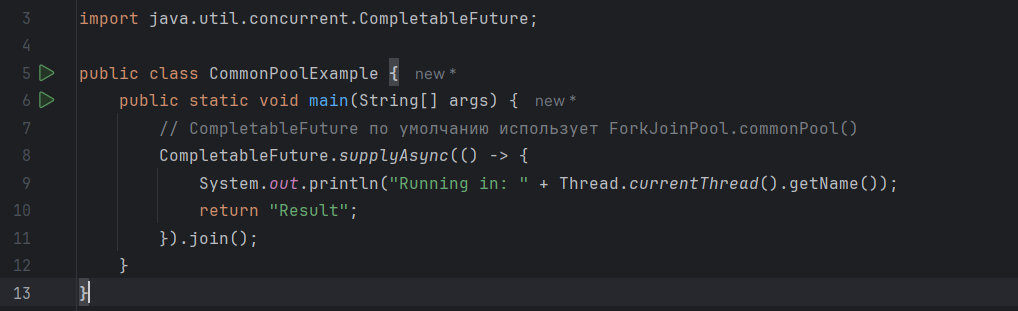
⚠️ Осторожно: если вы заблокируете общий пул (например, вызовете Thread.sleep() или I/O), все CompletableFuture в приложении замедлятся!
Способ 2️⃣: Создать свой ForkJoinPool
Для контроля и изоляции тяжелых вычислений.
Пример: рекурсивная сумма массива
Покажем истинную мощь ForkJoinPool — на задаче, которую он любит.
Комментарии:
- Наследуем RecursiveTask<T> (если нужен результат) или RecursiveAction (если нет).
- fork() — отправляет задачу в очередь (асинхронно).
- join() — ждёт результат.
- Порог (THRESHOLD) — критически важен: слишком малый → накладные расходы на fork/join; слишком большой → мало параллелизма.
✅ Преимущества ForkJoinPool
- Эффективен для CPU-bound задач (математика, сортировка, обработка данных).
- Work-stealing обеспечивает равномерную загрузку ядер.
- Минимум блокировок — высокая производительность.
- Интеграция с CompletableFuture и Stream API (.parallelStream() использует общий пул!).
Заключение
Пример, рассмотренный в статье, можно найти по адресу:
https://github.com/ShkrylAndrei/blog_yandex/tree/main/src/main/java/info/shkryl/forkjoinpool