Долгое время я не понимал, что всё это значит в htop.
Я думал, что средняя нагрузка 1.0 на моём двухъядерном компьютере означает, что загрузка процессора составляет 50%. Это не совсем так. А ещё, почему там 1.0?
Я решил всё изучить и задокументировать здесь.
Говорят, что лучший способ чему-то научиться — это попытаться научить этому других.
Перевод https://peteris.rocks/blog/htop/

htop в Ubuntu Server
Вот скриншот htop, который я собираюсь описать.
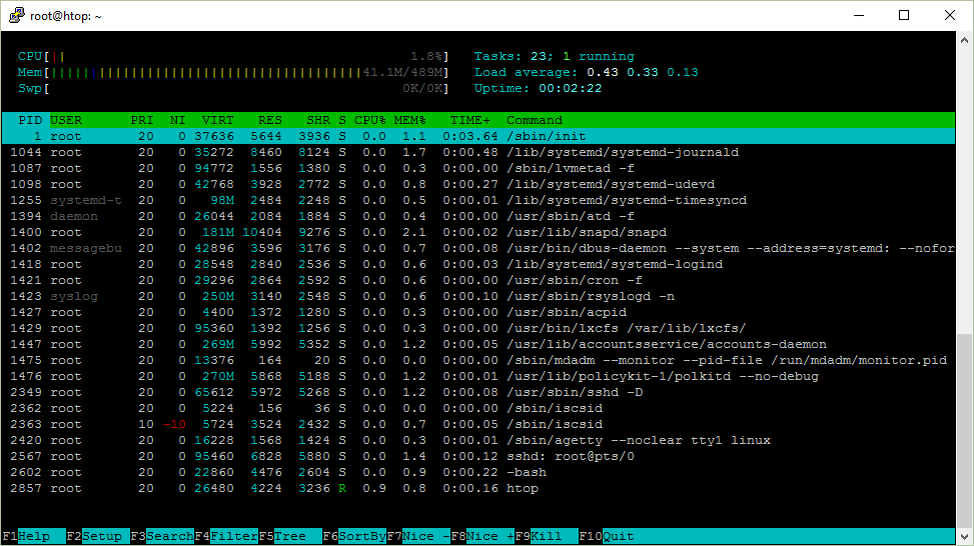
Время безотказной работы
Время безотказной работы показывает, как долго система работает.
Эту же информацию можно получить, выполнив команду uptime:
$ uptime
12:17:58 up 111 days, 31 min, 1 user, load average: 0.00, 0.01, 0.05
Откуда программа uptime это знает?
Она считывает информацию из файла /proc/uptime.
9592411.58 9566042.33
Первое число — это общее количество секунд, в течение которых система работала. Второе число — это количество секунд, в течение которых машина простаивала. Второе значение может быть больше общего времени работы системы на системах с несколькими ядрами, поскольку оно представляет собой сумму.
Откуда я это узнал? Я посмотрел, какие файлы открывает программа uptime при запуске. Для этого можно использовать инструмент strace .
strace uptime
Вывода будет много. Мы можем grep для системного вызова open. Но это не сработает, так как strace выводит всё в стандартный поток ошибок (stderr). Мы можем перенаправить stderr в стандартный поток вывода (stdout) с помощью 2>&1.
Наш результат таков:
$ strace uptime 2>&1 | grep open
...
open("/proc/uptime", O_RDONLY) = 3
open("/var/run/utmp", O_RDONLY|O_CLOEXEC) = 4
open("/proc/loadavg", O_RDONLY) = 4
который содержит файл /proc/uptime, о котором я упоминал.
Оказывается, можно использовать strace -e open uptime и не заморачиваться с поиском.
Так зачем же нам нужна программа uptime, если мы можем просто прочитать содержимое файла? Вывод uptime удобно читать, в то время как количество секунд удобнее использовать в собственных программах или скриптах.
Средняя нагрузка
Помимо времени безотказной работы, были также указаны три числа, обозначающие среднюю нагрузку.
$ uptime
12:59:09 up 32 min, 1 user, load average: 0.00, 0.01, 0.03
Они взяты из файла /proc/loadavg. Если вы ещё раз взглянете на вывод strace , то увидите, что этот файл тоже был открыт.
$ cat /proc/loadavg
0.00 0.01 0.03 1/120 1500
В первых трёх столбцах указана средняя нагрузка на систему за последние 1, 5 и 15 минут. В четвёртом столбце показано количество запущенных в данный момент процессов и общее количество процессов. В последнем столбце указан идентификатор последнего использованного процесса.
Давайте начнём с последнего числа.
При запуске нового процесса ему присваивается идентификационный номер. Идентификационные номера процессов обычно увеличиваются, если только они не исчерпаны и не используются повторно. Идентификационный номер 1 принадлежит /sbin/init процессу, который запускается при загрузке.
Давайте ещё раз посмотрим на содержимое /proc/loadavg и запустим команду sleep в фоновом режиме. Когда она будет запущена в фоновом режиме, отобразится её идентификатор процесса.
$ cat /proc/loadavg
0.00 0.01 0.03 1/123 1566
$ sleep 10 &
[1] 1567
Таким образом, 1/123 означает, что в данный момент выполняется или готов к выполнению один процесс, а всего их 123.
Когда вы запускаете htop и видите только один запущенный процесс, это означает, что это и есть сам процесс htop.
Если вы запустите sleep 30 и снова запустите htop, то заметите, что запущен только один процесс. Это потому, что sleep не запущен, а находится в режиме ожидания или, другими словами, ждёт, пока что-то произойдёт. Запущенный процесс — это процесс, который в данный момент выполняется на физическом процессоре или ожидает своей очереди для выполнения на процессоре.
Если вы запустите cat /dev/urandom > /dev/null , который многократно генерирует случайные байты и записывает их в специальный файл, из которого никогда ничего не считывается, вы увидите, что теперь запущены два процесса.
$ cat /dev/urandom > /dev/null &
[1] 1639
$ cat /proc/loadavg
1.00 0.69 0.35 2/124 1679
Теперь запущены два процесса (генерация случайных чисел и cat, который считывает содержимое /proc/loadavg). Вы также заметите, что средняя нагрузка увеличилась.
Средняя нагрузка представляет собой среднюю нагрузку на систему за определённый период времени.
Показатель загрузки рассчитывается путём подсчёта количества запущенных (в данный момент запущенных или ожидающих запуска) и незавершаемых процессов (ожидающих дисковой или сетевой активности). Таким образом, это просто количество процессов.
Средние значения нагрузки — это среднее количество таких процессов за последние 1, 5 и 15 минут, верно?
Оказывается, всё не так просто.
Среднее значение нагрузки — это экспоненциально сглаженное скользящее среднее значение количества процессов. Из Википедии:
С математической точки зрения, все три значения всегда усредняют нагрузку на систему с момента её запуска. Все они снижаются экспоненциально, но с разной скоростью. Следовательно, среднее значение нагрузки за 1 минуту будет составлять 63 % от нагрузки за последнюю минуту плюс 37 % от нагрузки с момента запуска, за исключением последней минуты. Таким образом, с технической точки зрения неверно, что средняя нагрузка за 1 минуту включает в себя только активность за последние 60 секунд (поскольку она по-прежнему включает в себя 37 % активности за прошлые периоды), но в основном она включает в себя активность за последнюю минуту.
Вы этого ожидали?
Давайте вернёмся к генерации случайных чисел.
$ cat /proc/loadavg
1.00 0.69 0.35 2/124 1679
Хотя с технической точки зрения это неправильно, я упрощаю средние значения нагрузки, чтобы их было легче анализировать.
В данном случае процесс генерации случайных чисел зависит от производительности процессора, поэтому средняя нагрузка за последнюю минуту составляет 1.00 или в среднем 1 запущенный процесс.
Поскольку в моей системе только один процессор, его загрузка составляет 100 %, так как он может одновременно выполнять только один процесс.
Если бы у меня было два ядра, загрузка процессора составляла бы 50 %, поскольку мой компьютер может запускать два процесса одновременно. Средняя нагрузка на компьютер с двумя ядрами при 100 % загрузке процессора составила бы 2.00.
Количество ядер или процессоров можно посмотреть в левом верхнем углу htop или запустив nproc.
Поскольку в число загруженных процессов входят также процессы в состоянии, не допускающем прерывания, которые не оказывают существенного влияния на загрузку ЦП, делать выводы об использовании ЦП на основе средних значений загрузки, как я только что сделал, не совсем корректно. Это также объясняет, почему вы можете видеть высокие средние значения загрузки, но при этом не ощущать значительной нагрузки на ЦП.
Но есть такие инструменты, как mpstat, которые могут показать мгновенную загрузку процессора.
$ sudo apt install sysstat -y
$ mpstat 1
Linux 4.4.0-47-generic (hostname) 12/03/2016 _x86_64_ (1 CPU)
10:16:20 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
10:16:21 PM all 0.00 0.00 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:16:22 PM all 0.00 0.00 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:16:23 PM all 0.00 0.00 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
# ...
# kill cat /dev/urandom
# ...
10:17:00 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
10:17:01 PM all 1.00 0.00 0.00 2.00 0.00 0.00 0.00 0.00 0.00 97.00
10:17:02 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
Зачем же тогда мы используем средние значения нагрузки?
$ curl -s https://raw.githubusercontent.com/torvalds/linux/v4.8/kernel/sched/loadavg.c | head -n 7
/*
* kernel/sched/loadavg.c
*
* This file contains the magic bits required to compute the global loadavg
* figure. Its a silly number but people think its important. We go through
* great pains to make it work on big machines and tickless kernels.
*/
Процессы
В правом верхнем углу htop отображается общее количество процессов и то, сколько из них запущено. Но там написано Задачи, а не процессы. Почему?
Другое название процесса — задача. Ядро Linux внутри себя называет процессы задачами. htop использует слово «задачи» вместо «процессы», вероятно, потому, что оно короче и экономит место на экране.
Вы также можете увидеть потоки в htop. Чтобы включить или выключить отображение потоков, нажмите Shift+H на клавиатуре. Если вы видите Tasks: 23, 10 thr, значит, потоки отображаются.
Вы также можете увидеть потоки ядра с помощью Shift+K. Когда они будут видны, появится надпись Tasks: 23, 40 kthr.
Идентификатор процесса / PID
При запуске нового процесса ему присваивается идентификационный номер (ID), который сокращённо называется идентификатором процесса или PID.
Если вы запустите программу в фоновом режиме (&) из bash, вы увидите номер задания в квадратных скобках и PID.
$ sleep 1000 &
[1] 12503
Если вы пропустили этот шаг, вы можете использовать переменную $! в bash, которая будет расширена до последнего идентификатора процесса, переведённого в фоновый режим.
$ echo $!
12503
Идентификатор процесса очень полезен. С его помощью можно получить подробную информацию о процессе и управлять им.
procfs Это псевдофайловая система, которая позволяет пользовательским программам получать информацию от ядра путём чтения файлов. Обычно она монтируется в /proc/ и выглядит как обычный каталог, который можно просматривать с помощью ls и cd.
Вся информация, связанная с процессом, находится по адресу /proc/<pid>/.
$ ls /proc/12503
attr coredump_filter fdinfo maps ns personality smaps task
auxv cpuset gid_map mem numa_maps projid_map stack uid_map
cgroup cwd io mountinfo oom_adj root stat wchan
clear_refs environ limits mounts oom_score schedstat statm
cmdline exe loginuid mountstats oom_score_adj sessionid status
comm fd map_files net pagemap setgroups syscall
Например, /proc/<pid>/cmdline выдаст команду, которая использовалась для запуска процесса.
$ cat /proc/12503/cmdline
sleep1000$
Ух ты, это неправильно. Оказывается, команда отделяется байтом \0
$ od -c /proc/12503/cmdline
0000000 s l e e p \0 1 0 0 0 \0
0000013
которое мы можем заменить пробелом или переводом строки
$ tr '\0' '\n' < /proc/12503/cmdline
sleep
1000
$ strings /proc/12503/cmdline
sleep
1000
Каталог процесса может содержать ссылки! Например, cwd указывает на текущий рабочий каталог, а exe — на исполняемый двоичный файл.
$ ls -l /proc/12503/{cwd,exe}
lrwxrwxrwx 1 ubuntu ubuntu 0 Jul 6 10:10 /proc/12503/cwd -> /home/ubuntu
lrwxrwxrwx 1 ubuntu ubuntu 0 Jul 6 10:10 /proc/12503/exe -> /bin/sleep
Вот как htop, top, ps и другие диагностические утилиты получают информацию о деталях процесса: они считывают её из /proc/<pid>/<file>.
Дерево процессов
Когда вы запускаете новый процесс, процесс, запустивший новый процесс, называется родительским. Новый процесс становится дочерним по отношению к родительскому процессу. Эти отношения образуют древовидную структуру.
Если вы нажмёте F5 в htop, то увидите иерархию процессов.
Вы также можете использовать f для переключения между ps
$ ps f
PID TTY STAT TIME COMMAND
12472 pts/0 Ss 0:00 -bash
12684 pts/0 R+ 0:00 \_ ps f
или pstree
$ pstree -a
init
├─atd
├─cron
├─sshd -D
│ └─sshd
│ └─sshd
│ └─bash
│ └─pstree -a
...
Если вы когда-нибудь задавались вопросом, почему в качестве родительских процессов для некоторых из них часто указываются bash или sshd, то вот почему.
Вот что происходит, когда вы запускаете, скажем, date из оболочки bash:
- bash создаёт новый процесс, который является копией самого себя (с помощью системного вызова fork)
- затем он загружает программу из исполняемого файла /bin/date в память (с помощью системного вызова exec)
- bash родительский процесс будет ждать завершения дочернего процесса
Таким образом, /sbin/init с идентификатором 1 был запущен при загрузке, что привело к запуску демона SSH sshd. Когда вы подключаетесь к компьютеру, sshd запускает процесс для сеанса, который, в свою очередь, запускает оболочку bash
Мне нравится использовать это древовидное представление в htop, когда мне нужно увидеть все потоки.
Пользователь процесса
Каждый процесс принадлежит пользователю. Пользователи представлены числовыми идентификаторами.
$ sleep 1000 &
[1] 2045
$ grep Uid /proc/2045/status
Uid: 1000 1000 1000 1000
Чтобы узнать имя этого пользователя, можно использовать команду id .
$ id 1000
uid=1000(ubuntu) gid=1000(ubuntu) groups=1000(ubuntu),4(adm)
Оказывается, id получает эту информацию из файлов /etc/passwd и /etc/group .
$ strace -e open id 1000
...
open("/etc/nsswitch.conf", O_RDONLY|O_CLOEXEC) = 3
open("/lib/x86_64-linux-gnu/libnss_compat.so.2", O_RDONLY|O_CLOEXEC) = 3
open("/lib/x86_64-linux-gnu/libnss_files.so.2", O_RDONLY|O_CLOEXEC) = 3
open("/etc/passwd", O_RDONLY|O_CLOEXEC) = 3
open("/etc/group", O_RDONLY|O_CLOEXEC) = 3
...
Это происходит потому, что в файле конфигурации Name Service Switch (NSS) /etc/nsswitch.conf указано использовать эти файлы для разрешения имён.
$ head -n 9 /etc/nsswitch.conf
# ...
passwd: compat
group: compat
shadow: compat
Значение compat (режим совместимости) такое же, как и files , за исключением того, что разрешены другие специальные записи. files означает, что база данных хранится в файле (загружается с помощью libnss_files.so). Но вы также можете хранить своих пользователей в других базах данных и сервисах или использовать, например, облегчённый протокол доступа к каталогам (Lightweight Directory Access Protocol, LDAP).
/etc/passwd и /etc/group — это обычные текстовые файлы, в которых числовые идентификаторы сопоставляются с удобочитаемыми именами.
$ cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
ubuntu:x:1000:1000:Ubuntu:/home/ubuntu:/bin/bash
$ cat /etc/group
root:x:0:
adm:x:4:syslog,ubuntu
ubuntu:x:1000:
passwd? А где пароли?
На самом деле они в /etc/shadow.
$ sudo cat /etc/shadow
root:$6$mS9o0QBw$P1ojPSTexV2PQ.Z./rqzYex.k7TJE2nVeIVL0dql/:17126:0:99999:7:::
daemon:*:17109:0:99999:7:::
ubuntu:$6$GIfdqlb/$ms9ZoxfrUq455K6UbmHyOfz7DVf7TWaveyHcp.:17126:0:99999:7:::
Что это за тарабарщина?
- $6$используется алгоритм хеширования паролей, в данном случае это sha512
- далее следует случайно сгенерированная соль для защиты от атак с использованием радужных таблиц
- и, наконец, хеш вашего пароля + соль
При запуске программы она будет работать от имени вашего пользователя. Даже если исполняемый файл принадлежит не вам.
Если вы хотите запустить программу от имени root или другого пользователя, для этого и нужен sudo .
$ id
uid=1000(ubuntu) gid=1000(ubuntu) groups=1000(ubuntu),4(adm)
$ sudo id
uid=0(root) gid=0(root) groups=0(root)
$ sudo -u ubuntu id
uid=1000(ubuntu) gid=1000(ubuntu) groups=1000(ubuntu),4(adm)
$ sudo -u daemon id
uid=1(daemon) gid=1(daemon) groups=1(daemon)
Но что, если вы хотите войти в систему под другим пользователем, чтобы запустить различные команды? Используйте sudo bash или sudo -u user bash. Вы сможете использовать оболочку от имени этого пользователя.
Если вам не нравится, что вас постоянно просят ввести пароль root, вы можете просто отключить эту функцию, добавив своего пользователя в файл /etc/sudoers .
Давайте попробуем:
$ echo "$USER ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
-bash: /etc/sudoers: Permission denied
Верно, это может сделать только root.
$ sudo echo "$USER ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
-bash: /etc/sudoers: Permission denied
Что за чёрт?
Здесь происходит следующее: вы выполняете команду echo от имени пользователя root, но добавляете строку в файл /etc/sudoers от имени своего пользователя.
Обычно есть два способа решить эту проблему:
- echo "$USER ALL=(ALL) NOPASSWD: ALL" | sudo tee -a /etc/sudoers
- sudo bash -c "echo '$USER ALL=(ALL) NOPASSWD: ALL' >> /etc/sudoers"
В первом случае tee -a добавит стандартный ввод в файл, и мы выполним эту команду от имени пользователя root.
Во втором случае мы запускаем bash от имени пользователя root и просим его выполнить команду (-c), и вся команда будет выполнена от имени пользователя root. Обратите внимание на хитрую конструкцию "/', которая определяет, когда будет раскрыта переменная $USER
Если вы посмотрите на файл /etc/sudoers, то увидите, что он начинается с
$ sudo head -n 3 /etc/sudoers
#
# This file MUST be edited with the 'visudo' command as root.
#
О- о-о.
Это полезное предупреждение о том, что вам следует редактировать этот файл с помощью sudo visudo. Это позволит проверить содержимое файла перед сохранением и предотвратит ошибки. Если вы не используете visudo и допустите ошибку, это может привести к тому, что вы не сможете sudo. То есть вы не сможете исправить свою ошибку!
Допустим, вы хотите изменить свой пароль. Это можно сделать с помощью команды passwd . Как мы уже видели ранее, она сохранит пароль в файле /etc/shadow .
Этот файл является конфиденциальным, и доступ к нему есть только у root:
$ ls -l /etc/shadow
-rw-r----- 1 root shadow 1122 Nov 27 18:52 /etc/shadow
Так как же получается, что программа passwd, запущенная обычным пользователем, может записывать данные в защищённый файл?
Ранее я говорил, что при запуске процесса он становится вашим, даже если владельцем исполняемого файла является другой пользователь.
Оказывается, это поведение можно изменить, изменив права доступа к файлу. Давайте посмотрим.
$ ls -l /usr/bin/passwd
-rwsr-xr-x 1 root root 54256 Mar 29 2016 /usr/bin/passwd
Обратите внимание на букву s в начале. Это было сделано с помощью sudo chmod u+s /usr/bin/passwd. Это означает, что исполняемый файл будет запущен от имени владельца файла, которым в данном случае является root.
Вы можете найти так называемые setuid исполняемые файлы с помощью find /bin -user root -perm -u+s.
Обратите внимание, что то же самое можно сделать с группой (g+s).
Состояние процесса
Далее мы рассмотрим столбец состояния процесса в htop, который обозначается просто буквой S.
Вот возможные значения:
R running or runnable (on run queue)
S interruptible sleep (waiting for an event to complete)
D uninterruptible sleep (usually IO)
Z defunct ("zombie") process, terminated but not reaped by its parent
T stopped by job control signal
t stopped by debugger during the tracing
X dead (should never be seen)
Я расположил их в порядке частоты появления.
Обратите внимание, что при запуске ps также будут отображаться подсостояния, такие как Ss, R+, Ss+ и т. д.
$ ps x
PID TTY STAT TIME COMMAND
1688 ? Ss 0:00 /lib/systemd/systemd --user
1689 ? S 0:00 (sd-pam)
1724 ? S 0:01 sshd: vagrant@pts/0
1725 pts/0 Ss 0:00 -bash
2628 pts/0 R+ 0:00 ps x
R — выполняется или может быть выполнено (в очереди на выполнение)
В этом состоянии процесс либо выполняется, либо находится в очереди на выполнение.
Что значит «выполняется»?
Когда вы компилируете исходный код написанной вами программы, этот машинный код превращается в инструкции для процессора. Он сохраняется в файле, который можно запустить. Когда вы запускаете программу, она загружается в память, а затем процессор выполняет эти инструкции.
По сути, это означает, что центральный процессор физически выполняет инструкции. Или, другими словами, обрабатывает числа.
S — прерывистый сон (ожидание завершения события)
Это означает, что инструкции кода этого процесса не выполняются на центральном процессоре. Вместо этого процесс ожидает какого-то события или условия. Когда происходит событие, ядро переводит процесс в состояние выполнения.
Один из примеров — утилита sleep из coreutils. Она приостанавливает выполнение команд на определённое количество секунд (приблизительно).
$ sleep 1000 &
[1] 10089
$ ps f
PID TTY STAT TIME COMMAND
3514 pts/1 Ss 0:00 -bash
10089 pts/1 S 0:00 \_ sleep 1000
10094 pts/1 R+ 0:00 \_ ps f
Значит, это прерываемый сон. Как мы можем его прервать?
Отправив сигнал.
Вы можете отправить сигнал в htop, нажав F9 и выбрав один из сигналов в меню слева.
Отправка сигнала также известна как kill. Это связано с тем, что kill — это системный вызов, который может отправить сигнал процессу. Существует программа /bin/kill, которая может выполнять этот системный вызов из пользовательского пространства, а сигнал по умолчанию — это TERM, который запрашивает завершение процесса или, другими словами, пытается его убить.
Сигнал — это просто число. Числа сложно запомнить, поэтому мы даём им названия. Названия сигналов обычно пишутся заглавными буквами и могут начинаться с SIG.
Некоторые часто используемые сигналы: INT, KILL, STOP, CONT, HUP.
Давайте прервём процесс сна, отправив сигнал INT aka SIGINT aka 2 aka Terminal interrupt .
$ kill -INT 10089
[1]+ Interrupt sleep 1000
То же самое происходит, когда вы нажимаете CTRL+C на клавиатуре. bash отправит процессу переднего плана сигнал SIGINT, как мы только что сделали вручную.
Кстати, в bashkill является встроенной командой, хотя в большинстве систем есть /bin/kill . Почему? Она позволяет завершать процессы, если достигнуто ограничение на количество создаваемых процессов.
Эти команды выполняют одну и ту же функцию:
- kill -INT 10089
- kill -2 10089
- /bin/kill -2 10089
Ещё один полезный сигнал — SIGKILL или 9. Возможно, вы использовали его, чтобы завершить процесс, который не реагировал на ваши отчаянные нажатия клавиш CTRL+C.
При написании программы вы можете настроить обработчики сигналов — функции, которые будут вызываться, когда ваш процесс получит сигнал. Другими словами, вы можете перехватить сигнал, а затем выполнить какое-то действие, например корректно завершить работу. Таким образом, отправка SIGINT (пользователь хочет прервать процесс) и SIGTERM (пользователь хочет завершить процесс) не означает, что процесс будет завершён.
Возможно, вы сталкивались с этим исключением при запуске скриптов Python:
$ python -c 'import sys; sys.stdin.read()'
^C
Traceback (most recent call last):
File "<string>", line 1, in <module>
KeyboardInterrupt
Вы можете указать ядру принудительно завершить процесс и не давать ему возможности ответить, отправив сигнал KILL:
$ sleep 1000 &
[1] 2658
$ kill -9 2658
[1]+ Killed sleep 1000
D — режим непрерывного сна (обычно для ввода-вывода)
В отличие от прерывистого сна, этот процесс нельзя разбудить с помощью сигнала. Именно поэтому многие люди боятся этого состояния. Такие процессы нельзя завершить, потому что завершение означает отправку SIGKILL сигналов процессам.
Это состояние используется, если процесс должен выполняться без прерываний или если ожидается, что событие произойдёт быстро. Например, при чтении с диска. Но это должно происходить лишь в течение доли секунды.
Вот отличный ответ на StackOverflow.
Непрерываемые процессы ОБЫЧНО ожидают ввода-вывода после сбоя страницы. Процесс/задача не может быть прервана в этом состоянии, потому что она не может обрабатывать никакие сигналы. Если бы она могла, произошёл бы ещё один сбой страницы, и процесс вернулся бы в прежнее состояние.
Другими словами, это может произойти, если вы используете сетевую файловую систему (NFS) и чтение и запись в неё занимают много времени.
Или, по моему опыту, это может означать, что некоторые процессы часто используют подкачку, а значит, у вас слишком мало свободной памяти.
Давайте попробуем перевести процесс в режим непрерывного сна.
8.8.8.8 — это общедоступный DNS-сервер от Google. У них нет открытого NFS. Но это нас не остановит.
$ sudo mount 8.8.8.8:/tmp /tmp &
[1] 12646
$ sudo ps x | grep mount.nfs
12648 pts/1 D 0:00 /sbin/mount.nfs 8.8.8.8:/tmp /tmp -o rw
Как выяснить, что является причиной этого? strace!
Давайте strace выполним команду, указанную в выводе ps выше.
$ sudo strace /sbin/mount.nfs 8.8.8.8:/tmp /tmp -o rw
...
mount("8.8.8.8:/tmp", "/tmp", "nfs", 0, ...
Таким образом, системный вызов mount блокирует процесс.
Если вам интересно, вы можете запустить mount с параметром intr для прерывистого выполнения: sudo mount 8.8.8.8:/tmp /tmp -o intr.
Z — завершённый («зомби») процесс, который был остановлен, но не был собран родительским процессом
Когда процесс завершается с помощью exit и у него остаются дочерние процессы, эти дочерние процессы становятся зомби-процессами.
- Если зомби-процессы существуют недолго, это совершенно нормально
- Зомби-процессы, которые существуют долгое время, могут указывать на ошибку в программе
- Зомби-процессы не потребляют память, только идентификатор процесса
- Вы не можете kill зомби-процесс
- Вы можете вежливо попросить родительский процесс избавиться от зомби (сигнал SIGCHLD)
- Вы можете kill родительский процесс зомби, чтобы избавиться от родителя и его зомби
Я напишу код на C, чтобы показать это.
Вот наша программа.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
printf("Running\n");
int pid = fork();
if (pid == 0) {
printf("I am the child process\n");
printf("The child process is exiting now\n");
exit(0);
} else {
printf("I am the parent process\n");
printf("The parent process is sleeping now\n");
sleep(20);
printf("The parent process is finished\n");
}
return 0;
}
Давайте установим компилятор GNU C (GCC).
sudo apt install -y gcc
Скомпилируйте его, а затем запустите
gcc zombie.c -o zombie
./zombie
Посмотрите на дерево процессов
$ ps f
PID TTY STAT TIME COMMAND
3514 pts/1 Ss 0:00 -bash
7911 pts/1 S+ 0:00 \_ ./zombie
7912 pts/1 Z+ 0:00 \_ [zombie] <defunct>
1317 pts/0 Ss 0:00 -bash
7913 pts/0 R+ 0:00 \_ ps f
Мы получили нашего зомби!
Когда родительский процесс завершается, зомби исчезает.
$ ps f
PID TTY STAT TIME COMMAND
3514 pts/1 Ss+ 0:00 -bash
1317 pts/0 Ss 0:00 -bash
7914 pts/0 R+ 0:00 \_ ps f
Если вы замените sleep(20) на while (true) ;, зомби-процесс сразу исчезнет.
При использовании exit вся связанная с ним память и ресурсы освобождаются, чтобы их могли использовать другие процессы.
Зачем тогда оставлять зомби-процессы?
У родительского процесса есть возможность узнать код завершения дочернего процесса (в обработчике сигналов) с помощью системного вызова wait . Если процесс находится в спящем режиме, ему нужно дождаться пробуждения.
Почему бы просто не разбудить его силой и не убить? По той же причине, по которой вы не выбрасываете своего ребёнка на помойку, когда он вам надоедает. Могут случиться плохие вещи.
T — остановлен сигналом управления работой
Я открыл два окна терминала и могу просматривать процессы своего пользователя с помощью ps u.
$ ps u
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
ubuntu 1317 0.0 0.9 21420 4992 pts/0 Ss+ Jun07 0:00 -bash
ubuntu 3514 1.5 1.0 21420 5196 pts/1 Ss 07:28 0:00 -bash
ubuntu 3528 0.0 0.6 36084 3316 pts/1 R+ 07:28 0:00 ps u
Я опущу процессы -bash и ps u в приведенном ниже выводе.
Теперь запустите cat /dev/urandom > /dev/null в одном окне терминала. Его состояние — R+, что означает, что он запущен.
$ ps u
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
ubuntu 3540 103 0.1 6168 688 pts/1 R+ 07:29 0:04 cat /dev/urandom
Нажмите CTRL+Z, чтобы остановить процесс.
$ # CTRL+Z
[1]+ Stopped cat /dev/urandom > /dev/null
$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
ubuntu 3540 86.8 0.1 6168 688 pts/1 T 07:29 0:15 cat /dev/urandom
Его состояние сейчас T.
Запустите fg в первом терминале, чтобы возобновить работу.
Другой способ остановить подобный процесс - отправить процессу STOP сигнал с помощью kill. Чтобы возобновить выполнение процесса, вы можете использовать CONT сигнал.
t — остановлен отладчиком во время трассировки
Сначала установите отладчик GNU (gdb)
sudo apt install -y gdb
Запустите программу, которая будет прослушивать входящие сетевые подключения на порту 1234.
$ nc -l 1234 &
[1] 3905
Он «спит», то есть ожидает получения данных из сети.
$ ps u
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
ubuntu 3905 0.0 0.1 9184 896 pts/0 S 07:41 0:00 nc -l 1234
Запустите отладчик и подключите его к процессу с идентификатором 3905.
sudo gdb -p 3905
Вы увидите, что состояние равно t, что означает, что этот процесс отслеживается в отладчике.
$ ps u
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
ubuntu 3905 0.0 0.1 9184 896 pts/0 t 07:41 0:00 nc -l 1234
Время процесса
Linux — это многозадачная операционная система, а это значит, что даже при наличии одного процессора вы можете запускать несколько процессов одновременно. Вы можете подключиться к своему серверу по SSH и посмотреть на вывод htop в то время, как ваш веб-сервер доставляет контент вашего блога читателям через Интернет.
Как такое возможно, если один процессор может выполнять только одну инструкцию за раз?
Ответ: разделение времени.
Один процесс выполняется в течение некоторого времени, затем он приостанавливается, а другие процессы, ожидающие своей очереди, выполняются в течение некоторого времени. Время, в течение которого выполняется процесс, называется временным отрезком.
Временной интервал обычно составляет несколько миллисекунд, поэтому вы не замечаете его, если система не сильно нагружена. (Было бы интересно узнать, сколько обычно составляют временные интервалы в Linux.)
Это должно помочь вам понять, почему средняя нагрузка — это среднее количество запущенных процессов. Если у вас одно ядро и средняя нагрузка составляет 1.0, значит, процессор загружен на 100%. Если средняя нагрузка выше 1.0, это означает, что количество процессов, которые хотят запуститься, превышает возможности процессора, поэтому вы можете столкнуться с замедлением работы или задержками. Если нагрузка ниже 1.0, это означает, что процессор иногда простаивает и ничего не делает.
Это также должно помочь вам понять, почему иногда время выполнения процесса, который работает 10 секунд, больше или меньше ровно 10 секунд.
Точность и приоритетность процесса
Когда задач больше, чем доступных ядер процессора, нужно каким-то образом решить, какие задачи выполнять в первую очередь, а какие отложить. За это отвечает планировщик задач.
Планировщик в ядре Linux отвечает за выбор следующего процесса в очереди на выполнение. Выбор зависит от алгоритма планировщика, используемого в ядре.
Как правило, вы не можете повлиять на планировщик, но можете сообщить ему, какие процессы для вас важнее, и планировщик может принять это во внимание.
Приятность (NI) - это приоритет пользовательского пространства для процессов в диапазоне от -20, который является наивысшим приоритетом, до 19, который является низшим приоритетом. Это может сбивать с толку, но вы можете думать, что приятный процесс уступает место менее приятному процессу. Таким образом, чем приятнее процесс, тем больше он дает.
Судя по тому, что я узнал, читая StackOverflow и другие сайты, повышение уровня оптимизации на 1 должно увеличить время, которое процессор выделяет процессу, на 10 %.
Приоритет (PRI) — это приоритет в пространстве ядра, который использует ядро Linux. Приоритеты варьируются от 0 до 139, при этом от 0 до 99 — это режимы реального времени, а от 100 до 139 — пользовательские режимы.
Вы можете изменить значение nice, и ядро примет это во внимание, но вы не можете изменить приоритет.
Соотношение между значением nice и приоритетом следующее:
PR = 20 + NI
Таким образом, значение PR = 20 + (-20 to +19) находится в диапазоне от 0 до 39, что соответствует диапазону от 100 до 139.
Вы можете установить приоритет процесса перед его запуском.
nice -n niceness program
Измените параметры, когда программа уже запущена, с помощью renice.
renice -n niceness -p PID
Вот что означают цвета, обозначающие загрузку процессора:
- Синий: потоки с низким приоритетом (nice > 0)
- Зеленый: потоки с обычным приоритетом
- Красный: потоки ядра
http://askubuntu.com/questions/656771/process-niceness-vs-priority
Использование памяти — VIRT/RES/SHR/MEM
У процесса создаётся иллюзия того, что он является единственным в памяти. Это достигается за счёт использования виртуальной памяти.
Процесс не имеет прямого доступа к физической памяти. Вместо этого у него есть собственное виртуальное адресное пространство, а ядро преобразует адреса виртуальной памяти в адреса физической памяти или может отображать часть виртуальной памяти на диске. Поэтому может показаться, что процессы используют больше памяти, чем установлено на вашем компьютере.
Я хочу сказать, что определить, сколько памяти занимает процесс, не так-то просто. Вы также хотите подсчитать объём общих библиотек или отображённой в память области диска? Но ядро предоставляет и htop показывает некоторую информацию, которая может помочь вам оценить использование памяти.
Вот что означают цвета, обозначающие использование памяти:
- Зелёный: используемая память
- Синий: буферы
- Оранжевый: кэш
VIRT/VSZ — виртуальный образ
Общий объём виртуальной памяти, используемой задачей. Сюда входят весь код, данные и общие библиотеки, а также страницы, которые были выгружены, и страницы, которые были отображены, но не использовались.
VIRT Это использование виртуальной памяти. Сюда входит всё, включая файлы, отображаемые в память.
Если приложение запрашивает 1 ГБ памяти, но использует только 1 МБ, то VIRT покажет 1 ГБ. Если оно mmapит файл размером 1 ГБ и никогда его не использует, VIRT также покажет 1 ГБ.
В большинстве случаев это бесполезное число.
RES/RSS — размер резидентной памяти
Объём физической памяти, не используемой задачей.
RES — это использование оперативной памяти, то есть то, что в данный момент находится в физической памяти.
Хотя RES может быть более точным показателем того, сколько памяти использует процесс, чем VIRT, имейте в виду, что
- сюда не входит выгруженная память
- часть памяти может использоваться совместно с другими процессами
Если процесс использует 1 ГБ памяти и вызывает fork(), то в результате форка появятся два процесса, у которых RES равен 1 ГБ, но фактически будет использоваться только 1 ГБ, поскольку в Linux используется копирование при записи.
SHR — размер общей памяти
Объём общей памяти, используемой задачей. Это просто показатель объёма памяти, который потенциально может использоваться совместно с другими процессами.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
printf("Started\n");
sleep(10);
size_t memory = 10 * 1024 * 1024; // 10 MB
char* buffer = malloc(memory);
printf("Allocated 10M\n");
sleep(10);
for (size_t i = 0; i < memory/2; i++)
buffer[i] = 42;
printf("Used 5M\n");
sleep(10);
int pid = fork();
printf("Forked\n");
sleep(10);
if (pid != 0) {
for (size_t i = memory/2; i < memory/2 + memory/5; i++)
buffer[i] = 42;
printf("Child used extra 2M\n");
}
sleep(10);
return 0;
}
fallocate -l 10G
gcc -std=c99 mem.c -o mem
./mem
Process Message VIRT RES SHR
main Started 4200 680 604
main Allocated 10M 14444 680 604
main Used 5M 14444 6168 1116
main Forked 14444 6168 1116
child Forked 14444 5216 0
main Child used extra 2M 8252 1116
child Child used extra 2M 5216 0
TODO: мне нужно закончить это.
MEM% - Использование памяти
Доля доступной физической памяти, используемая задачей в данный момент.
Это RES делённое на общий объём имеющейся у вас оперативной памяти.
Если RES равно 400M и у вас 8 гигабайт оперативной памяти, то MEM% будет равно 400/8192*100 = 4.88%.
Процессы
Давайте посмотрим на список процессов на скриншоте htop.
Они вам действительно нужны?
Вот мои заметки об исследованиях процессов, которые запускаются при старте нового сервера Digital Ocean с Ubuntu Server 16.04.1 LTS x64.
До того , как
/sbin/init
Программа /sbin/init (также называемая init) координирует остальную часть процесса загрузки и настраивает среду для пользователя.
Когда запускается команда init, она становится родительским или прародительским процессом для всех автоматически запускающихся в системе процессов.
Это systemd?
$ dpkg -S /sbin/init
systemd-sysv: /sbin/init
Да, это так.
Что произойдёт, если вы его убьёте?
Ничего.
/lib/systemd/systemd-journald
systemd-journald — это системная служба, которая собирает и хранит данные журналов. Она создаёт и поддерживает структурированные индексированные журналы на основе информации из журналов, получаемой из различных источников.
Другими словами:
Одним из основных изменений в journald стала замена простых текстовых файлов журналов на файлы специального формата, оптимизированные для хранения сообщений журнала. Этот формат файлов позволяет системным администраторам более эффективно получать доступ к нужным сообщениям. Кроме того, он привносит в отдельные системы некоторые возможности централизованной системы ведения журналов на основе баз данных.
Для запроса файлов журналов следует использовать команду journalctl .
- journalctl _COMM=sshdлоги sshd
- journalctl _COMM=sshd -o json-prettyлоги sshd в формате JSON
- journalctl --since "2015-01-10" --until "2015-01-11 03:00"
- journalctl --since 09:00 --until "1 hour ago"
- journalctl --since yesterday
- journalctl -bлоги с момента загрузки
- journalctl -fдля отслеживания логов
- journalctl --disk-usage
- journalctl --vacuum-size=1G
Довольно круто.
Похоже, что удалить или отключить эту службу невозможно, можно только отключить ведение журнала.
/sbin/lvmetad -f
Демон lvmetad кэширует метаданные LVM, чтобы команды LVM могли считывать метаданные без сканирования дисков.
Кэширование метаданных может быть полезным, поскольку сканирование дисков занимает много времени и может мешать нормальной работе системы и дисков.
Но что такое LVM (управление логическими томами)?
LVM можно рассматривать как «динамические разделы». Это означает, что вы можете создавать, изменять размер и удалять «разделы» LVM (на языке LVM они называются «логическими томами») из командной строки во время работы вашей системы Linux: не нужно перезагружать систему, чтобы ядро узнало о вновь созданных разделах или разделах с изменённым размером.
Судя по всему, вам следует оставить его, если вы используете LVM.
$ lvscan
$ sudo apt remove lvm2 -y --purge
/lib/systemd/udevd
systemd-udevd прослушивает события ядра uevents. Для каждого события systemd-udevd выполняет соответствующие инструкции, указанные в правилах udev.
udev — это менеджер устройств для ядра Linux. Являясь преемником devfsd и hotplug, udev в первую очередь управляет узлами устройств в каталоге /dev.
Таким образом, эта служба управляет /dev.
Я не уверен, что мне нужно запускать её на виртуальном сервере.
/lib/systemd/timesyncd
systemd-timesyncd — это системная служба, которую можно использовать для синхронизации локальных системных часов с удалённым сервером протокола сетевого времени.
Итак, это заменяет ntpd.
$ timedatectl status
Local time: Fri 2016-08-26 11:38:21 UTC
Universal time: Fri 2016-08-26 11:38:21 UTC
RTC time: Fri 2016-08-26 11:38:20
Time zone: Etc/UTC (UTC, +0000)
Network time on: yes
NTP synchronized: yes
RTC in local TZ: no
Если мы посмотрим на открытые порты на этом сервере:
$ sudo netstat -nlput
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 2178/sshd
tcp6 0 0 :::22 :::* LISTEN 2178/sshd
Замечательно!
Раньше в Ubuntu 14.04 было так
$ sudo apt-get install ntp -y
$ sudo netstat -nlput
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1380/sshd
tcp6 0 0 :::22 :::* LISTEN 1380/sshd
udp 0 0 10.19.0.6:123 0.0.0.0:* 2377/ntpd
udp 0 0 139.59.256.256:123 0.0.0.0:* 2377/ntpd
udp 0 0 127.0.0.1:123 0.0.0.0:* 2377/ntpd
udp 0 0 0.0.0.0:123 0.0.0.0:* 2377/ntpd
udp6 0 0 fe80::601:6aff:fxxx:123 :::* 2377/ntpd
udp6 0 0 ::1:123 :::* 2377/ntpd
udp6 0 0 :::123 :::* 2377/ntpd
Фу.
/usr/sbin/atd -f
atd — запускает задания, поставленные в очередь на последующее выполнение. atd запускает задания, поставленные в очередь с помощью at.
at и batch считывают команды из стандартного ввода или указанного файла, которые должны быть выполнены позднее
В отличие от cron, который планирует периодическое выполнение задач, at запускает задачу один раз в определённое время.
$ echo "touch /tmp/yolo.txt" | at now + 1 minute
job 1 at Fri Aug 26 10:44:00 2016
$ atq
1 Fri Aug 26 10:44:00 2016 a root
$ sleep 60 && ls /tmp/yolo.txt
/tmp/yolo.txt
На самом деле я никогда им не пользовался.
sudo apt remove at -y --purge
/usr/lib/snapd/snapd
Snappy Ubuntu Core — это новая версия Ubuntu с транзакционными обновлениями. Это минимальный образ сервера с теми же библиотеками, что и в современной Ubuntu, но с более простым механизмом установки приложений.
Что?
Разработчики из нескольких дистрибутивов Linux и компаний объявили о сотрудничестве в области универсального формата пакетов Linux «snap», который позволяет одному двоичному пакету идеально и безопасно работать на любом настольном компьютере, сервере, в облаке или на любом устройстве с Linux.
Судя по всему, это упрощённый deb-пакет, и предполагается, что все зависимости будут собраны в один snap-пакет, который можно распространять.
Я никогда не использовал snappy для развёртывания или распространения приложений на серверах.
sudo apt remove snapd -y --purge
/usr/bin/dbus-daemon
В вычислительной технике D-Bus или DBus — это механизм межпроцессного взаимодействия (IPC) и удалённого вызова процедур (RPC), который обеспечивает связь между несколькими компьютерными программами (то есть процессами), одновременно работающими на одном компьютере
Насколько я понимаю, он нужен для настольных сред, но на сервере он используется для запуска веб-приложений?
sudo apt remove dbus -y --purge
Интересно, который сейчас час и синхронизируется ли он с NTP?
$ timedatectl status
Failed to create bus connection: No such file or directory
Упс. Наверное, стоит это сохранить.
/lib/systemd/systemd-logind
systemd-logind — это системная служба, которая управляет входом пользователей в систему.
/usr/sbin/cron -f
cron — демон для выполнения команд по расписанию (Vixie Cron)
-f Оставайтесь в режиме переднего плана, не переходите в фоновый режим.
Вы можете запланировать периодическое выполнение задач с помощью cron.
Используйте crontab -e для редактирования конфигурации вашего пользователя. В Ubuntu я обычно использую каталоги /etc/cron.hourly, /etc/cron.daily, и т. д.
Вы можете просмотреть файлы журнала с помощью
- grep cron /var/log/syslogили
- journalctl _COMM=cronили даже
- journalctl _COMM=cron --since="date" --until="date"
Скорее всего, вам понадобится cron.
Но если нет, то вам следует остановить и отключить службу:
sudo systemctl stop cron
sudo systemctl disable cron
Потому что в противном случае при попытке удалить его с помощью apt remove cron будет предпринята попытка установить postfix!
$ sudo apt remove cron
The following packages will be REMOVED:
cron
The following NEW packages will be installed:
anacron bcron bcron-run fgetty libbg1 libbg1-doc postfix runit ssl-cert ucspi-unix
Похоже, что для отправки электронных писем cron нужен почтовый транспортный агент (MTA).
$ apt show cron
Package: cron
Version: 3.0pl1-128ubuntu2
...
Suggests: anacron (>= 2.0-1), logrotate, checksecurity, exim4 | postfix | mail-transport-agent
$ apt depends cron
cron
...
Suggests: anacron (>= 2.0-1)
Suggests: logrotate
Suggests: checksecurity
|Suggests: exim4
|Suggests: postfix
Suggests: <mail-transport-agent>
...
exim4-daemon-heavy
postfix
/usr/sbin/rsyslogd -n
Rsyslogd — это системная утилита, обеспечивающая поддержку ведения журнала сообщений.
Другими словами, это то, что заполняет файлы журналов в /var/log/ таких как /var/log/auth.log сообщениями об аутентификации, например о попытках входа в SSH.
Файлы конфигурации находятся в /etc/rsyslog.d.
Вы также можете настроить rsyslogd для отправки файлов журналов на удаленный сервер и реализовать централизованное ведение журнала.
Вы можете использовать команду logger для записи сообщений в /var/log/syslog в фоновых сценариях, например в тех, которые запускаются при загрузке.
#!/bin/bash
logger Starting doing something
# NFS, get IPs, etc.
logger Done doing something
Верно, но у нас уже запущен systemd-journald . Нужно ли нам также запускать rsyslogd ?
Rsyslog и Journal — два приложения для ведения журналов, установленные в вашей системе, — имеют ряд отличительных особенностей, которые делают их подходящими для конкретных случаев использования. Во многих ситуациях полезно объединить их возможности, например для создания структурированных сообщений и их хранения в файловой базе данных. Коммуникационный интерфейс, необходимый для такого взаимодействия, обеспечивается модулями ввода и вывода в Rsyslog и коммуникационным сокетом в Journal.
Так что, может быть? Я оставлю его на всякий случай.
/usr/sbin/acpid
acpid — демон событий расширенной конфигурации и интерфейса питания
acpid предназначен для уведомления пользовательских программ о событиях ACPI. acpid должен запускаться во время загрузки системы и по умолчанию работает в фоновом режиме.
В вычислительной технике спецификация Advanced Configuration and Power Interface (ACPI) обеспечивает открытый стандарт, который операционные системы могут использовать для выполнения обнаружения и настройки компонентов компьютерного оборудования, для управления питанием, например, переводя неиспользуемые компоненты в спящий режим, и для мониторинга состояния.
Но я нахожусь на виртуальном сервере, который я не собираюсь приостанавливать/возобновлять.
Я собираюсь удалить его ради забавы и посмотреть, что произойдёт.
sudo apt remove acpid -y --purge
Мне удалось успешно reboot создать каплю, но после halt Digital Ocean решил, что она всё ещё активна, поэтому мне пришлось выключить её через веб-интерфейс.
Так что, наверное, мне стоит это сохранить.
/usr/bin/lxcfs /var/lib/lxcfs/
Lxcfs — это файловая система fuse, предназначенная в основном для использования в контейнерах lxc. В системе Ubuntu 15.04 она по умолчанию используется для двух целей: во-первых, для виртуализации некоторых файлов /proc; во-вторых, для фильтрации доступа к файловым системам cgroup хоста.
Таким образом, на хосте с версией 15.04 теперь можно создать контейнер обычным способом: lxc-create ... Полученный контейнер будет выдавать «правильные» результаты для uptime, top и т. д.
По сути, это обходной путь в пользовательском пространстве для изменений, которые было сочтено нецелесообразным вносить в ядро. Благодаря этому контейнеры воспринимаются как отдельные системы, а не как их часть.
Не используете контейнеры LXC? Вы можете удалить его с помощью
sudo apt remove lxcfs -y --purge
/usr/lib/accountservice/accounts-daemon
Пакет AccountsService предоставляет набор интерфейсов D-Bus для запроса и изменения информации об учётных записях пользователей, а также реализацию этих интерфейсов на основе команд usermod(8), useradd(8) и userdel(8).
Когда я удалил DBus, это привело к сбою timedatectl, и я задумался, к чему приведёт удаление этой службы.
sudo apt remove accountsservice -y --purge
Время покажет.
/sbin/mdadm
mdadm — это утилита Linux, используемая для управления программными RAID-устройствами и мониторинга их работы.
Название происходит от термина md (multiple device, «несколько устройств»), обозначающего узлы устройств, которыми он управляет, и заменяет предыдущую утилиту mdctl. Изначально он назывался «Зеркальный диск», но название было изменено по мере расширения функциональности.
RAID — это метод использования нескольких жёстких дисков как одного. У RAID две цели: 1) Увеличение ёмкости диска: RAID 0. Если у вас есть два жёстких диска по 500 ГБ, то общий объём составит 1 ТБ. 2) Предотвращение потери данных в случае сбоя диска: например, RAID 1, RAID 5, RAID 6 и RAID 10.
Вы можете удалить его с помощью
sudo apt remove mdadm -y --purge
/usr/lib/policykit-1/polkitd --no-debug
polkitd — демон PolicyKit
polkit - Фреймворк авторизации
Насколько я понимаю, это что-то вроде sudo с мелкими настройками. Вы можете разрешить пользователям без прав администратора выполнять определённые действия от имени пользователя root. Например, перезагружать компьютер, если вы используете Linux на настольном компьютере.
Но у меня запущен сервер. Вы можете удалить его с помощью
sudo apt remove policykit-1 -y --purge
Всё ещё думаю, не сломается ли что-нибудь.
/usr/sbin/sshd -D
sshd (демон OpenSSH) — это программа-демон для ssh.
-D Если указан этот параметр, sshd не будет отключаться и не станет демоном. Это упрощает мониторинг sshd.
/sbin/iscsid
iscsid — это демон (системная служба), который работает в фоновом режиме, настраивая iSCSI и управляя подключениями. Из справочной страницы:
iscsid реализует канал управления протоколом iSCSI, а также некоторые средства управления. Например, демон можно настроить на автоматический перезапуск обнаружения при запуске на основе содержимого постоянной базы данных iSCSI.
http://unix.stackexchange.com/questions/216239/iscsi-vs-iscsid-services
Я никогда не слышал о iSCSI:
В вычислительной технике iSCSI (Listeni/aɪˈskʌzi/ ай-скузи) — это аббревиатура от Internet Small Computer Systems Interface, стандарта сетевых хранилищ на основе интернет-протокола (IP) для подключения устройств хранения данных.
Благодаря передаче команд SCSI по IP-сетям iSCSI используется для упрощения передачи данных по интранет-сетям и управления хранилищами на больших расстояниях. iSCSI можно использовать для передачи данных по локальным сетям (LAN), глобальным сетям (WAN) или Интернету, а также для хранения и извлечения данных независимо от местоположения.
Протокол позволяет клиентам (называемым инициаторами) отправлять команды SCSI (CDB) на устройства хранения данных SCSI (адресаты) на удалённых серверах. Это протокол сети хранения данных (SAN), который позволяет организациям объединять хранилища в массивы хранения данных в центрах обработки данных, создавая для хостов (таких как серверы баз данных и веб-серверы) иллюзию локально подключённых дисков.
Вы можете удалить его с помощью
sudo apt remove open-iscsi -y --purge
/sbin/agetty --noclear tty1 linux
agetty — альтернатива Linux getty
getty, сокращение от «get tty», — это программа Unix, работающая на хост-компьютере и управляющая физическими или виртуальными терминалами (TTY). При обнаружении подключения она запрашивает имя пользователя и запускает программу «login» для аутентификации пользователя.
Изначально в традиционных системах Unix getty обрабатывала соединения с последовательными терминалами (часто с телетайпами), подключёнными к главному компьютеру. Часть tty в названии означает Teletype, но со временем стало обозначать любой тип текстового терминала.
Это позволяет вам войти в систему, когда вы физически находитесь на сервере. В Digital Ocean вы можете нажать на Console в разделе с информацией о виртуальной машине, и вы сможете взаимодействовать с этим терминалом в браузере (по-моему, это подключение по протоколу VNC).
Раньше при загрузке системы запускалось несколько терминалов (настроенных в /etc/inittab), но сейчас они запускаются по запросу systemd.
Ради забавы я удалил этот файл конфигурации, который запускает и генерирует agetty:
sudo rm /etc/systemd/system/getty.target.wants/getty@tty1.service
sudo rm /lib/systemd/system/getty@.service
Когда я перезагрузил сервер, я по-прежнему мог подключиться к нему по SSH, но больше не мог войти в систему через веб-консоль Digital Ocean.
sshd: root@pts/0 & -bash & htop
sshd: root@pts/0 означает, что для пользователя был установлен сеанс SSH root на #0 псевдотерминальном (pts). Псевдотерминал эмулирует реальный текстовый терминал.
bash это оболочка, которую я использую.
Почему в начале стоит прочерк? Пользователь Reddit хирнброт любезно объяснил это:
В начале стоит дефис, потому что запуск команды как «-bash» сделает её оболочкой для входа в систему. Оболочка для входа в систему — это оболочка, первым символом аргумента нулевого порядка которой является -, или оболочка, запущенная с параметром --login. В этом случае она будет считывать другой набор файлов конфигурации.
htop Это интерактивный инструмент для просмотра процессов, запущенных на скриншоте.
После
sudo apt remove lvm2 -y --purge
sudo apt remove at -y --purge
sudo apt remove snapd -y --purge
sudo apt remove lxcfs -y --purge
sudo apt remove mdadm -y --purge
sudo apt remove open-iscsi -y --purge
sudo apt remove accountsservice -y --purge
sudo apt remove policykit-1 -y --purge
Экстремальная версия:
sudo apt remove dbus -y --purge
sudo apt remove rsyslog -y --purge
sudo apt remove acpid -y --purge
sudo systemctl stop cron && sudo systemctl disable cron
sudo rm /etc/systemd/system/getty.target.wants/getty@tty1.service
sudo rm /lib/systemd/system/getty@.service
Я следовал инструкциям в своём блоге о самостоятельной установке WordPress на Ubuntu Server, и всё работает.
Вот nginx, PHP7 и MySQL.
Приложение
Исходный код
Иногда недостаточно просто посмотреть на strace.
Другой способ понять, что делает программа, — изучить её исходный код.
Сначала мне нужно понять, с чего начать.
$ which uptime
/usr/bin/uptime
$ dpkg -S /usr/bin/uptime
procps: /usr/bin/uptime
Здесь мы узнаем, что uptime на самом деле находится по адресу /usr/bin/uptime и что в Ubuntu это часть procps пакета.
Затем вы можете перейти на страницу packages.ubuntu.com и выполнить поиск посылки там.
Вот страница дляprocps: http://packages.ubuntu.com/source/xenial/procps
Если вы прокрутите страницу вниз, то увидите ссылки на репозитории исходного кода:
- Исходный репозиторий пакетов Debian git://git.debian.org/collab-maint/procps.git
- Исходный репозиторий пакетов Debian (доступный для просмотра) https://anonscm.debian.org/cgit/collab-maint/procps.git/
Файловые дескрипторы и перенаправление
Если вы хотите перенаправить стандартную ошибку (stderr) на стандартный вывод (stdout), что нужно использовать: 2&>1 или 2>&1?
Вы можете запомнить, где находится амперсанд &, зная, что echo something > file запишет something в файл file. Это то же самое, что echo something 1> file. Теперь echo something 2> file запишет вывод stderr в file.
Если вы пишете echo something 2>1, это означает, что вы перенаправляете stderr в файл с именем 1. Добавьте пробелы, чтобы было понятнее: echo something 2> 1.
Если вы добавляете & перед 1, это означает, что 1 — это не имя файла, а идентификатор потока. То есть это echo something 2>&1.
Цвета в шпаклевке
Если при использовании PuTTY в htop отсутствуют какие-то элементы, вот как это можно исправить.
- Щелкните правой кнопкой мыши на строке заголовка
- Выберите "Изменить настройки"...
- Перейдите в "Окно" -> "Цвета"
- Выберите переключатель "Оба"
- Нажмите "Применить"
Оболочка в C
Давайте напишем очень простую оболочку на языке C, которая демонстрирует использование системных вызовов fork/exec/wait . Вот программа shell.c.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/wait.h>
int main() {
printf("Welcome to my shell\n");
char line[1024];
while (1) {
printf("> ");
fgets(line, sizeof(line), stdin);
line[strlen(line)-1] = '\0'; // strip \n
if (strcmp(line, "exit") == 0) // shell built-in
break;
int pid = fork();
if (pid == 0) {
printf("Executing: %s\n", line);
if (execlp(line, "", NULL) == -1) {
printf("ERROR!\n");
exit(1);
}
} else if (pid > 0) {
int status;
waitpid(pid, &status, 0);
printf("Child exited with %d\n", WEXITSTATUS(status));
} else {
printf("ERROR!\n");
break;
}
}
return 0;
}
Скомпилируйте программу.
gcc shell.c -o shell
И запустите его.
$ ./shell
Welcome to my shell
> date
Executing: date
Thu Dec 1 14:10:59 UTC 2016
Child exited with 0
> true
Executing: true
Child exited with 0
> false
Executing: false
Child exited with 1
> exit
Вы когда-нибудь задумывались о том, что, запуская процесс в фоновом режиме, вы видите, что он завершился, только через некоторое время, когда нажимаете Enter?
$ sleep 1 &
[1] 11686
$ # press Enter
[1]+ Done sleep 1
Это происходит потому, что оболочка ожидает ваших действий. Только когда вы вводите команду, она проверяет статус фоновых процессов и показывает, завершены ли они.
TODO
Вот о чём я хотел бы узнать побольше.
- подстатусы состояния процесса (Ss, Ss+, R+, и т. д.)
- потоки ядра
- /dev/pts
- подробнее о памяти (CODE, DATA, SWAP)
- определение длины временных интервалов
- алгоритм планировщика Linux
- привязка процессов к ядрам
- описание страниц руководства
- цвета процессора/памяти в виде полос
- ограничение идентификатора процесса и форк-бомба
- lsof, ionice, schedtool
Заключительные замечания
Пожалуйста, дайте мне знать, если в этом посте что-то не так! Я с радостью исправлю это.
Обсудить эту статью можно в Телеграм канале: https://t.me/linautonet