GLM-4.7
Новая версия лмки для программирования, агентных систем и сложных рассуждений
Базовое программирование
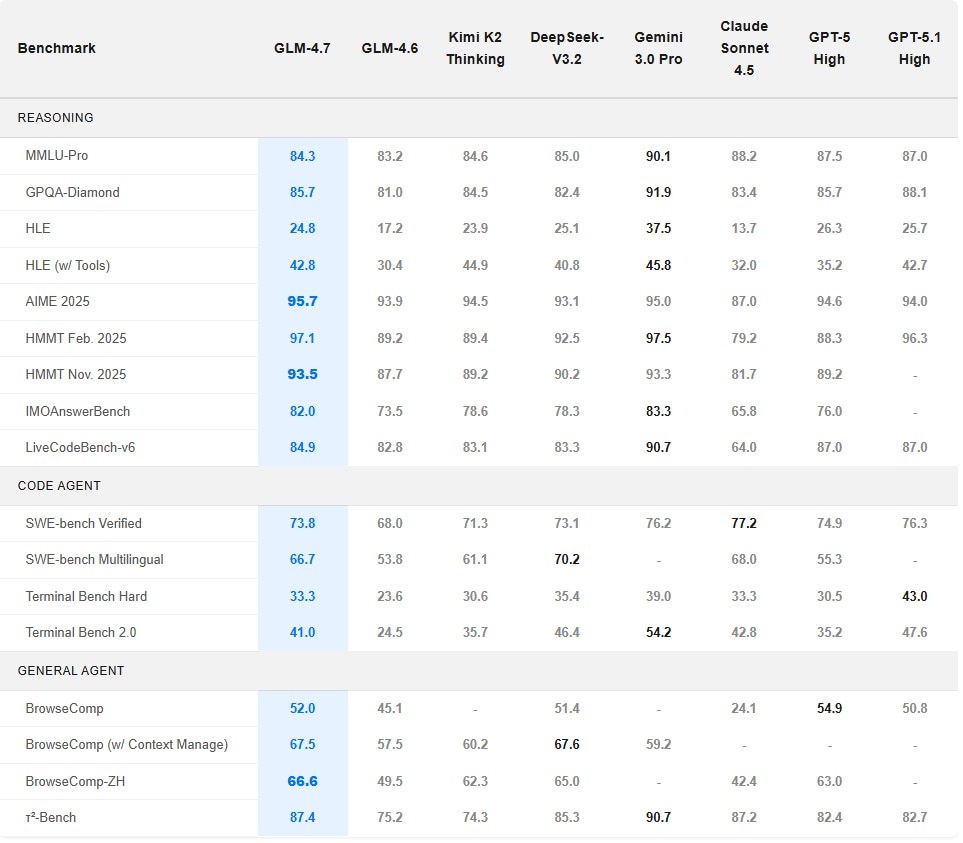
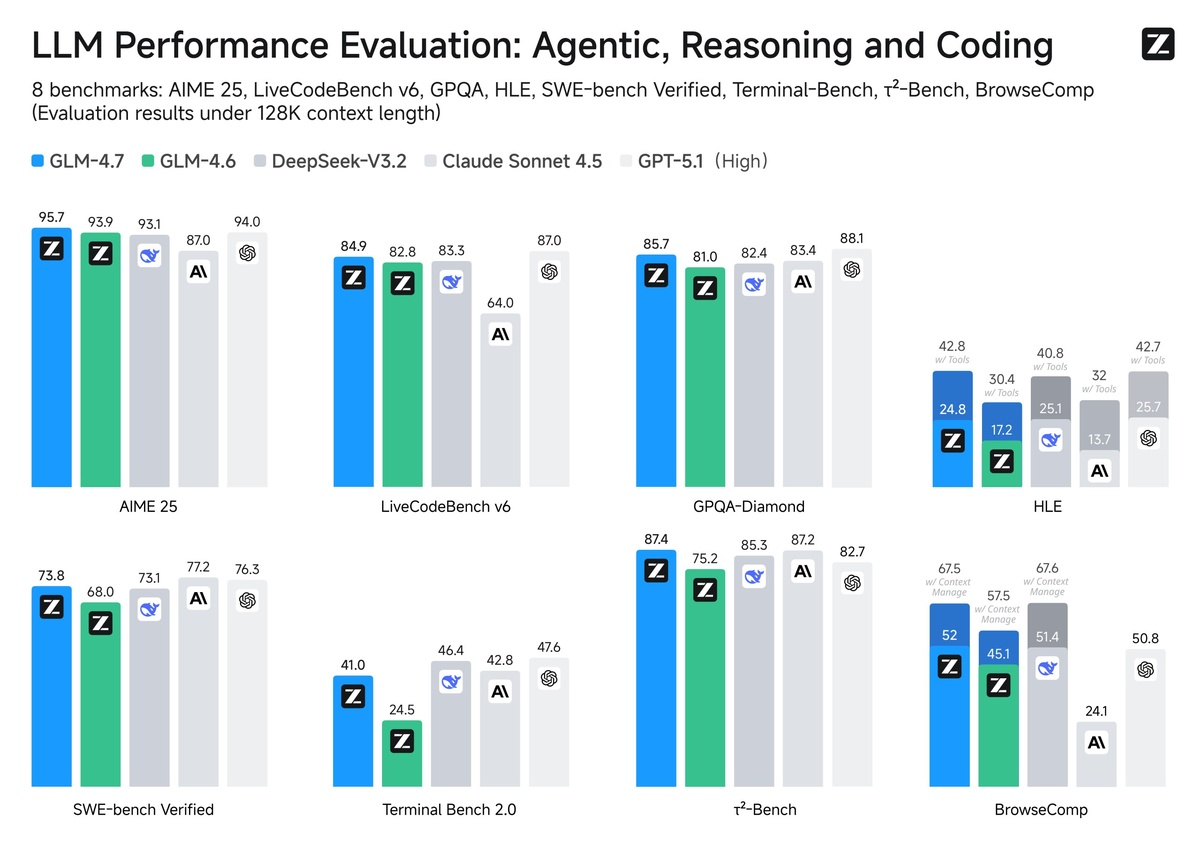
- 73.8% (+5.8%) на SWE-bench
- 66.7% (+12.9%) на SWE-bench Multilingual (многоязычный)
- 41% (+16.5%) на Terminal Bench 2.0
Поддерживает режим «думать перед действием», особенно эффективно в популярных агентных фреймворках: Claude Code, Kilo Code, Cline и Roo Code
Vibe Coding
- Более чистые и современные веб-страницы
- Улучшенная генерация слайдов с точной компоновкой и размерами
Работа с инструментами
- 87.4% на τ²-Bench (против 75.2% у GLM-4.6)
- Улучшенная производительность веб-браузинга на BrowseComp
Сложные рассуждения
- 42.8% (+12.4%) на HLE (Humanity's Last Exam) с инструментами
- 95.7% на AIME 2025
- 97.1% на HMMT February 2025
Конкурирует с GPT-5.1-High, Claude Sonnet 4.5, Gemini 3.0 Pro, DeepSeek-V3.2 и Kimi K2 Thinking на 17 разных бенчмарках
По новым функциям:
Interleaved Thinking
Думает перед каждым ответом и вызовом инструмента, улучшая следование инструкциям и качество генерации
Preserved Thinking
В задачах кодирования автоматически сохраняет все блоки мышления между диалогами, переиспользуя существующие рассуждения вместо повторного вывода с нуля, нужно это чтобы снижать потерю информации и хорошо зайдет для долгосрочных сложных задач
Turn-level Thinking
Поддержка пошагового контроля над рассуждениями
- Отключение мышления для лёгких запросов = снижение задержки и стоимости
- Включение для сложных задач = повышение точности и стабильности
Советую зайти к ним на страницу блога и посмотреть прикольные кейсы