
Компания Zhipu AI представила новую языковую модель GLM-4.7, которая показывает сильные результаты в задачах программирования и технического мышления. Основное внимание в обновлении уделено улучшению работы с кодом и математическими задачами, а также экономичности использования.
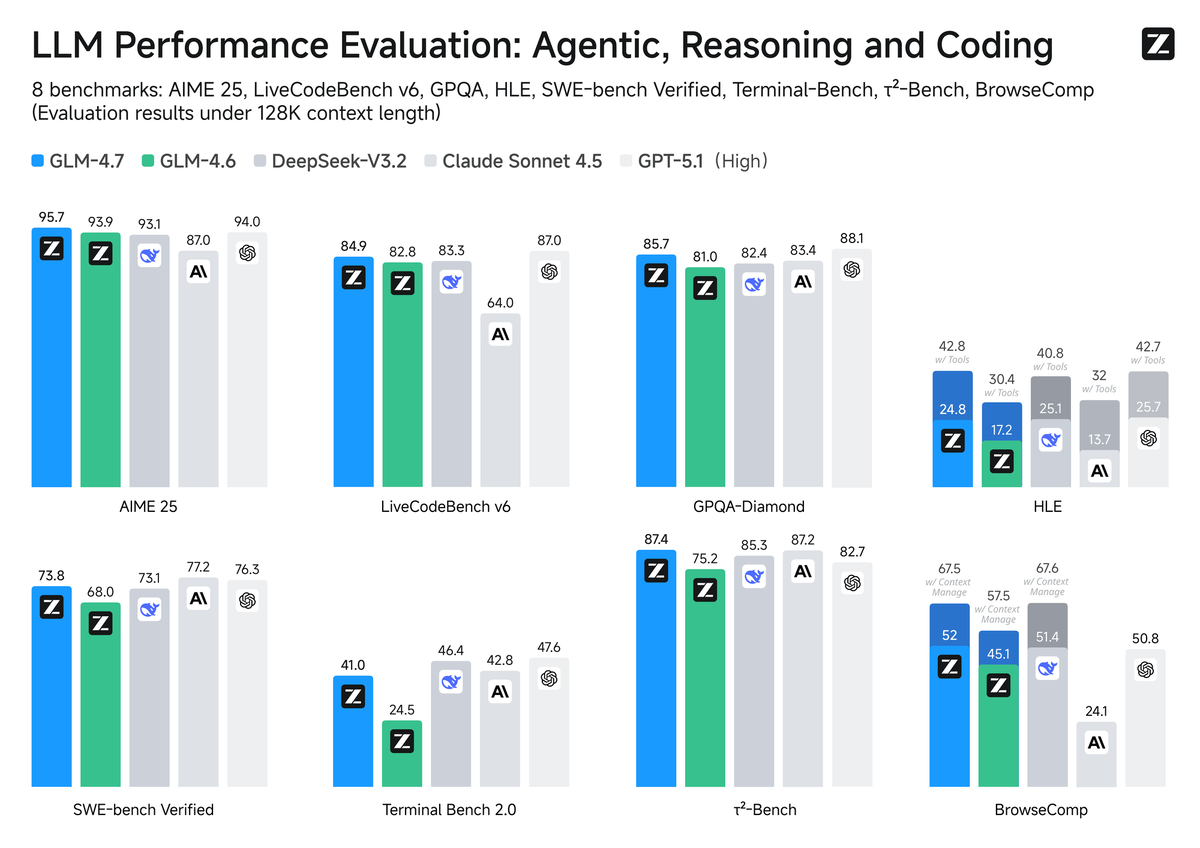
GLM-4.7 серьёзно опережает предшествующую версию GLM-4.6. На тесте SWE-bench модель набрала 73,8%, на многоязычном варианте SWE-bench Multilingual — 66,7%. Ещё один заметный результат получен на Terminal Bench 2.0 — 41%.
Уточняется, что модель теперь эффективнее разбирается в сложных задачах, встречающихся в популярных средах вроде Claude Code, Kilo Code и Cline. При этом разработчики отмечают улучшение визуальной составляющей генерируемого кода, т. к. страницы выглядят современнее, а презентации становятся точнее в оформлении и структуре.
Рост показателей отмечен и в области математики. В сложном бенчмарке HLE модель с инструментами достигла 42,8%, улучшив результат предшественника на 12,4 пункта. На математической олимпиаде AIME 2025 GLM-4.7 заняла первое место среди всех протестированных моделей с результатом 95,7%.
В сравнительной таблице модель сопоставлена с конкурентами вроде GPT-5, GPT-5.1, Claude Sonnet 4.5, Gemini 3.0 Pro и DeepSeek-V3.2. Хотя она не занимает верхние строчки во всех метриках, по ряду позиций GLM-4.7 уверенно входит в лидирующую группу и по отдельным направлениям опережает конкурентов.
Среди технических особенностей появилась функция сохранения логических цепочек в ходе диалога. Это помогает сохранять последовательность размышлений и избегать сбоев при долгосрочной работе с пользователем.
Модель уже доступна через платформу Z.ai. Кроме того, веса модели размещены на HuggingFace и ModelScope, что открывает возможности для локального развёртывания. Подписка на GLM Coding Plan оценивается в сумму, которая в семь раз меньше стоимости аналогичных предложений, при этом лимиты использования увеличены в три раза.