От вражды к симбиозу: как в IT примирили две непримиримые армии и создали суперспособность доставлять ценность за минуты, а не месяцы
Представьте себе стройку небоскреба. На площадке работают две команды. Первая — архитекторы и прорабы (инженеры-строители). Их задача — разработать фантастический проект, рассчитать нагрузки, выбрать материалы, создать красивейшие чертежи. Они хотят творить, внедрять инновации, делать что-то особенное. Вторая команда — бригадиры, монтажники и обслуживание. Их задача — чтобы здание стояло крепко, не шаталось на ветру, чтобы в нём не текли трубы, работали лифты, а уборщики могли помыть окна. Их главный страх — что архитектор придумает какую-нибудь сумасшедшую стеклянную крышу, которую невозможно обслуживать зимой, или фундамент, который начнёт проседать через год.
Теперь представьте, что эти команды работают в полной изоляции. Архитекторы передают готовый проект через бронированную дверь с надписью «Утверждено. К исполнению». И уходят. Строители начинают работу, но тут же натыкаются на тысячи проблем: на чертежах не учтены реальные коммуникации, материалы заказаны не те, конструкции не сходятся. Здание строится медленно, со скрипом, и когда жильцы наконец заселяются, оказывается, что вентиляция не справляется, а электропроводка опасна. Команды обвиняют друг друга, процесс стоит колоссальных денег и нервов.
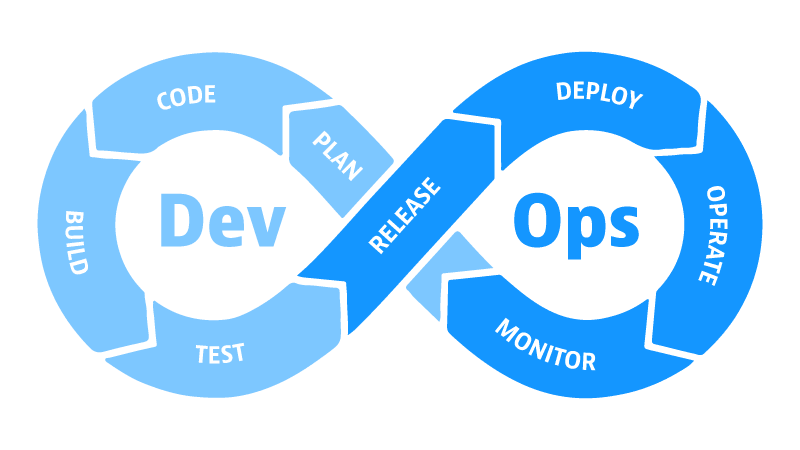
Именно так, в виде двух изолированных и часто враждующих лагерей — разработки (Development, Dev) и эксплуатации (Operations, Ops) — десятилетиями жил и болел весь мир информационных технологий. Разработчики хотели как можно быстрее выкатывать новые функции пользователям, а системные администраторы хотели, чтобы ничего не ломалось и всё было стабильно. Их цели, по определению, казались противоположными: скорость против стабильности. Пока однажды не появилась простая, но гениальная мысль: а что если не разделять эти процессы, а объединить их в единый, непрерывный цикл? Что если заставить эти команды работать вместе с самого начала? Так родилась философия, культура и набор практик под названием DevOps. И она не просто изменила IT — она перевернула правила игры для всего цифрового бизнеса.

Суть DevOps: ломаем стену, строим мост
DevOps — это не должность и не одна конкретная технология. Это, в первую очередь, культура совместной работы и общая ответственность за итоговый продукт, который работает и приносит ценность. Это набор практик, которые автоматизируют и ускоряют процессы между написанием кода и его работой у реального пользователя.
Проще говоря, DevOps — это мост между «написал» и «заработало». Его цель — сделать так, чтобы ценность (новая функция, исправление ошибки) доходила до пользователя максимально быстро, безопасно и предсказуемо.
Чтобы понять, как это работает, давайте представим идеальный, автоматизированный конвейер доставки программного обеспечения — CI/CD-пайплайн (Continuous Integration / Continuous Delivery — непрерывная интеграция и непрерывная доставка). Этот пайплайн — сердце DevOps-практик.
Давайте пройдём по этому конвейеру шаг за шагом, как по сборочной линии.
Всё начинается с того, что разработчик заканчивает работу над небольшой функцией — например, новой кнопкой «поделиться» в приложении. Он не просто сохраняет файл, а отправляет (делает git push) свои изменения в общий репозиторий кода, например, в GitLab, GitHub или Bitbucket. Это момент «непрерывной интеграции» (CI). Как только код попадает в общую ветку, автоматически, без чьего-либо участия, запускается наш конвейер.
Первая автоматическая станция — сборка (Build). Система (например, Jenkins, GitLab CI или GitHub Actions) берёт свежий код и «собирает» его: компилирует, если это нужно, и упаковывает во что-то готовое к запуску. Чаще всего сегодня это Docker-контейнер — легковесная, стандартизированная упаковка приложения со всеми его зависимостями (библиотеками, настройками). Контейнер гарантирует, что приложение будет работать абсолютно одинаково на ноутбуке разработчика, на тестовом сервере и в огромном облаке. Это решает вечную проблему: «У меня на компьютере работало!».
Следующая станция — автоматическое тестирование (Test). Здесь в дело вступают заранее написанные скрипты. Сначала запускаются юнит-тесты — они проверяют, правильно ли работают самые маленькие кирпичики программы (отдельные функции). Потом могут запуститься интеграционные тесты — проверяют, как эти кирпичики работают вместе. Если хоть один тест падает, конвейер останавливается немедленно, и разработчик получает уведомление о том, что именно сломалось. Это принцип «поломка на раннем этапе — самая дешёвая поломка». Гораздо лучше найти ошибку сейчас, чем когда функция уже попала к пользователям.
Дальше — станция проверки безопасности и качества кода (Security & Code Quality). Автоматические сканеры (например, SonarQube или Trivy для контейнеров) проверяют код на наличие известных уязвимостей, утечек паролей, плохих практик. Это не заменяет хакеров-профессионалов, но отсекает огромный пласт глупых и распространённых ошибок.
Если все проверки пройдены, артефакт (наш Docker-контейнер) попадает на финальные станции — непрерывную доставку и развертывание (CD). В продвинутых компаниях этот процесс тоже полностью автоматизирован. Контейнер сначала автоматически выкатывается на тестовое/промежуточное окружение (staging), максимально похожее на боевое. Там могут запуститься сложные сквозные (end-to-end) тесты, имитирующие действия реального пользователя. И если всё хорошо, система может сама, или после лёгкого подтверждения, развернуть новую версию на боевых серверах (production).
Вот так выглядит идеальный поток. Фактически, за несколько минут (а в лидерах вроде Amazon — за секунды) код из-под пальцев разработчика превращается в работающую функцию для миллионов пользователей. И самое главное — вся инфраструктура, на которой это происходит, описана в коде (Infrastructure as Code, IaC).
Инфраструктура как код: когда программируют даже серверы
Это, пожалуй, самый революционный аспект DevOps. Раньше системный администратор настраивал сервер вручную: устанавливал операционную систему, настраивал веб-сервер, правила брандмауэра, подключал базу данных. Это было долго, а главное — неповторимо. Конфигурация жила в голове админа и в куче разрозненных заметок. Восстановить сервер после сбоя или создать десять одинаковых — адский труд.
DevOps меняет это кардинально. Теперь инфраструктура (серверы, сети, настройки) описывается с помощью специальных декларативных языков в виде файлов-скриптов. Самые популярные инструменты для этого — Terraform, Ansible, Puppet, Chef.
Что это даёт? Во-первых, повторяемость и скорость. Чтобы поднять копию всего кластера серверов в другом регионе, нужно просто запустить тот же самый скрипт. Во-вторых, контроль версий. Файлы инфраструктуры хранятся в том же Git, что и код приложения. Можно видеть, кто и когда изменил настройку брандмауэра, и, если что-то сломалось, — откатиться к рабочей версии. Инфраструктура становится предсказуемой и управляемой.
Не только автоматизация: культура, метрики и общие цели
Но DevOps — это не только роботы и скрипты. Без правильной культуры вся эта техническая мощь бесполезна. Культура DevOps строится на трёх китах:
Общая ответственность. Разработчики больше не могут сказать «на моей машине работало, это проблемы ops». Они вовлечены в создание наблюдаемого, тестируемого и сопровождаемого кода. Ops-инженеры (которые в DevOps-культуре часто называются SRE — Site Reliability Engineers, инженеры надежности сайтов) участвуют в проектировании архитектуры приложения на ранних этапах, чтобы оно было готово к масштабированию и мониторингу. Команда едина.
Фокус на метриках, а не на мнениях. Вместо споров «стабильно ли это?» или «быстро ли работает?» все смотрят на цифры. Ключевые метрики, известные как «Четыре ключа» из книги «Accelerate», это:
- Частота развертывания — как часто вы доставляете новые версии.
- Время выполнения изменений — сколько времени проходит от коммита кода до его работы в продакшене.
- Среднее время восстановления — как быстро вы исправляете сбой в работе.
- Процент неудачных изменений — какой процент развертываний вызывает инциденты.
Компании, которые улучшают эти метрики, объективно становятся более эффективными и конкурентными.
Непрерывное обучение и экспериментирование. DevOps поощряет создание культуры, где не страшно ошибаться в контролируемой среде, а из инцидентов извлекаются уроки без поиска виноватых (практика blameless postmortem — разбор полётов без обвинений).
Кому и зачем это нужно? Эволюция, а не панацея
DevOps — это не серебряная пуля для всех. Для небольшого стартапа с одним продуктом и командой из пяти человек, где все и так общаются за одним столом, формальные DevOps-практики могут быть избыточны. Но как только компания растёт, появляется несколько команд, несколько продуктов, сложная инфраструктура — без DevOps-подхода начинается хаос.
Это эволюционный ответ на потребность бизнеса в гибкости, скорости и надёжности в цифровую эпоху. Когда Netflix может выпускать тысячи обновлений в день, когда банк может безопасно обновлять мобильное приложение каждую неделю, а интернет-магазин — автоматически масштабироваться в час распродаж в 1000 раз — всё это заслуга культурных и технических принципов DevOps.
В итоге, быть DevOps — это значит уметь говорить на языках и разработки, и эксплуатации, и бизнеса. Это мышление, которое стирает границы, чтобы сосредоточиться на главном: быстрой и безопасной доставке ценности конечному пользователю. Это путь от хаотичного ручного труда к предсказуемому, управляемому и невероятно эффективному цифровому потоку.
👍 Ставьте лайки если хотите разбор других интересных тем.
👉 Подписывайся на IT Extra на Дзен чтобы не пропустить следующие статьи
Если вам интересно копать глубже, разбирать реальные кейсы и получать знания, которых нет в открытом доступе — вам в IT Extra Premium.
Что внутри?
✅ Закрытые публикации: Детальные руководства, разборы сложных тем (например, архитектура высоконагруженных систем, глубокий анализ уязвимостей, оптимизация кода, полезные инструменты объяснения сложных тем простым и понятным языком).
✅ Конкретные инструкции: Пошаговые мануалы, которые вы сможете применить на практике уже сегодня.
✅ Без рекламы и воды: Только суть, только концентрат полезной информации.
✅ Ранний доступ: Читайте новые материалы первыми.
Это — ваш личный доступ к экспертизе, упакованной в понятный формат. Не просто теория, а инструменты для роста.
👉 Переходите на Premium и начните читать то, о чем другие только догадываются.
👇
Понравилась статья? В нашем Telegram-канале ITextra мы каждый день делимся такими же понятными объяснениями, а также свежими новостями и полезными инструментами. Подписывайтесь, чтобы прокачивать свои IT-знания всего за 2 минуты в день!