
Зачем всё это и для кого
Ручной поиск вакансий - это когда ты вроде как работаешь, а по факту бесконечно жмёшь «следующая страница» на HeadHunter и копируешь таблички, как офисный RPA из 2007 года. В какой‑то момент понимаешь: либо ты ставишь на это крест, либо ставишь на это n8n и превращаешь скучный кликер в нормальный, предсказуемый процесс, который шуршит 24/7 без твоего участия.
Эта статья для технарей, аналитиков и автоматизаторов, которые хотят собирать вакансии через API HH, а не шаманить скриптами или копипастой. Плюсом это зайдёт тем, кто:
- как соискатель хочет ловить «вкусные» вакансии раньше толпы;
- как нанимающий хочет первым снимать сливки с рынка по своему стеку.
Дальше - разбор архитектуры парсинга HH.ru на n8n: как собрать воркфлоу, не попасть под лимиты API, не утонуть в кривых данных и не превратить всё в хрупкую поделку, падающую через час активной работы.
Архитектура workflow: из чего состоит парсер
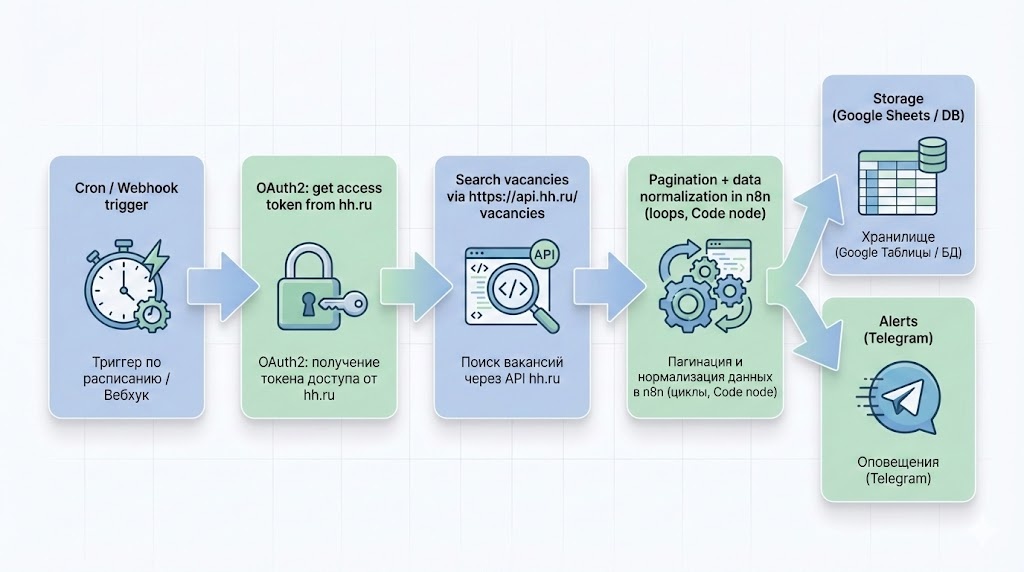
Если выкинуть весь романтизм, любой рабочий парсер вакансий HH на n8n раскладывается на пять уровней - от триггера до уведомлений.
1. Триггер: кто даёт старт
- В боевом режиме живёт Cron‑триггер, который дергает сценарий, например, раз в 2 часа.
- Для разовых прогонов и экспериментов - ручной запуск или Webhook, если этот парсер дергает другая система.
2. Аутентификация: договариваемся с HH.ru
- HH использует OAuth2: сначала отдельный HTTP Request (POST) меняет client_id + client_secret на access_token через https://hh.ru/oauth/token
- Токен не выпрашиваем на каждый чих: один раз получили, аккуратно храним и подставляем в заголовок Authorization: Bearer {token} при следующих запросах.
3. Получение вакансий: основной поток данных
- Базовый запрос летит на https://api.hh.ru/vacancies с параметрами вроде text, area,experience,salary_from, only_with_salary, professional_role и т.п.
- HH отдаёт результаты постранично, при этом общее количество возвращаемых вакансий в поиске ограничено примерно 2000, а per_page технически упирается в максимум около 500 элементов на страницу.
4. Пагинация и цикл обработки
- Ответ приходит постранично, поэтому через Loop / Split In Batches гоняемся по page, пока API не скажет «всё, больше вакансий нет» (служебное поле pages + проверка длины выдачи).
- На каждом шаге выдираем только то, что реально нужно: название, работодатель, зарплата, город, ссылка, требования; description и key_skills в коротком поиске нет - их тянем дополнительно по /vacancies/{id}, когда надо.
5. Сохранение и оповещения
- На выходе чистые данные складываются в Google Sheets, базу или что тебе ближе - через Google Sheets‑ноду или DB‑ноды.
- Параллельно можно швырять алерты в Telegram:
«нашли 5 новых вакансий в Москве на позицию … , вот ссылки».
Примеры запросов к API HH
Чтобы не гадать по документам, проще сразу опираться на живые примеры.
Поиск Python‑разработчиков в Москве, 100 штук на страницу
https://api.hh.ru/vacancies?text=Python+developer&area=1&per_page=100&page=0
Поиск по России, но разбивкой по городам, чтобы не упереться в лимит 2000
- Москва: area=1
- Санкт‑Петербург: area=2
- Россия (кроме мегаполисов) - area=113 с фильтрами по профессиональным ролям и зарплате, чтобы сузить выборку.
Ключевой момент:
- `per_page` - в обсуждениях и практических примерах фигурирует максимум около 100–500 элементов на страницу, даже если в базовой доке явно это не подчёркнуто.
- Общее число вакансий в выдаче ограничено примерно 2000, так что для «всей России» по популярным технологиям придётся дробить запросы на сегменты и потом склеивать данные по id вакансии.
Ключевые ноды в n8n: что крутит эту мясорубку
Магии нет - всё держится на аккуратно настроенных базовых нодах.
HTTP Request: рабочая лошадка
- Для токена: POST https://hh.ru/oauth/token c client_id, client_secret и нужным grant_type в body или query.
- Для поиска: GET https://api.hh.ru/vacancies с query‑параметрами (text, area, per_page, page, фильтры по опыту/ЗП/формату) и заголовком `Authorization: Bearer {token}`.
Пагинация, лимиты и паузы
- HH ограничивает частоту запросов: при агрессивной стрельбе начинаются 429 Too Many Requests.
- Практика: Split In Batches (например, по 10–20 вакансий) + Wait‑нода на 1–3 секунды между запросами, чтобы оставаться в лимитах и не увидать 429 в самый интересный момент.
Нормализация данных: Code Node в бой
- Типичный набор полей: id, name, employer.name, salary.from/to/currency, area.name, experience.id/name, alternate_url. Описание и навыки - при отдельном запросе по vacancy_id.
- Проблема: salary бывает объектом или null, часть полей может отсутствовать, описание приходит с HTML‑разметкой.
- В Code‑ноде приводим всё к единому виду: пустую зарплату - в null/0 (как договоришься), навыки - в список строк, город - в нормализованный справочник, описание - чистим от лишней разметки.
Google Sheets: дешёвое и сердитое хранилище
- Чаще всего достаточно операции Append - тупо дописываем новые строки как лог.
- Чтобы не плодить дубли, перед вставкой сверяемся по id вакансии: если уже есть - пропускаем (через отдельный поиск по листу или простую БД‑прослойку)
Ошибки, лимиты и защита: чтобы всё не падало через час работы
Если workflow падает от одного таймаута, это не автоматизация, а хрупкая поделка.
1. Retry on Fail (но с проверкой)
- В HTTP‑нодах включаем Retry on Fail: 3–5 попыток, интервал 1000–2000 мс.
- Но в некоторых версиях n8n отмечались баги, когда Retry on Fail конфликтовал с режимами On Error: Continue или ретраил все входные элементы целиком, а не только упавший. Поэтому перед боевым запуском прогоняем это на тестовом API и смотрим, как оно реально ведёт себя.
2. Явный бэкофф по 429/5xx
- Дополнительно к встроенному Retry имеет смысл вешать собственную обработку статусов 429/5xx:
- при 429 увеличивать задержку 1 → 2 → 4 → 8 секунд;
- при 500/502/504 тоже пробовать пару повторов с увеличением паузы.
3. Continue on Error там, где не критично
- Если не удалось дотянуть детали по одной конкретной вакансии (второй запрос к /vacancies/{id} отвалился) - нет смысла валить весь запуск.
- В таких нодах включаем Continue on Error и логируем проблемные id в отдельное хранилище.
4. Error Trigger и отдельный «антипожарный» workflow
- n8n умеет запускать отдельный воркфлоу от Error Trigger и передавать туда детали упавшего процесса.
- Дальше классика: Telegram / email с инфой, какой сценарий, на каком шаге и с каким кодом упал.
5. Fallback‑логика
- Если OAuth‑путь временно не работает, можно переключаться на более простой сценарий (например, запросы с уменьшенным per_page или урезанным набором фильтров), чтобы не останавливаться полностью.
Масштабирование: от 300 вакансий до 5000+ и ИИ‑анализа
Когда базовая схема работает, хочется либо больше данных, либо умнее аналитику.
SubWorkflow и параллельные ветки
- Один сценарий режем на подворкфлоу: Москва - отдельный поток, Питер - отдельный, регионы - третий.
- Это позволяет держать каждую ветку в своих лимитах и проще отлавливать проблемы (упал Питер - Москва продолжает жить).
Асинхронная схема с Redis или БД
- Паттерн «двух ходов»:
1) собираем ID вакансий по разным сегментам в Redis/БД;
2) отдельным воркфлоу асинхронно вытягиваем детали по этим ID и складываем в основное хранилище.
- Так проще параллелить запросы и контролировать нагрузку, не убивая API HH.
Подключение LLM прямо в цепочку
- После нормализации прогоняем описание через LLM: извлечь требования, оценить вилку ЗП, классифицировать по стеку/уровню.
- Это удобно, когда нужно строить «AI‑радар» по рынку, а не просто собирать голые вакансии.
Подходы к обработке: что выбрать
Живой пример
Один из боевых сценариев для технаря, который мониторит рынок Python‑вакансий по Москве.
- Cron - каждые 2 часа.
- HTTP Request - токен по OAuth2.
- HTTP Request - поиск по text="Python developer", area=1, per_page=50, page в цикле, пока не пройдём все страницы или не упрёмся в лимит.
- Split In Batches - по 10 вакансий на шаг.
- Code Node - нормализация зарплаты, города, навыков, чистка описаний.
- Проверка дубликатов → Google Sheets: Append или запись в БД.
- Telegram - алерт о новых вакансиях с краткой сводкой по ЗП и ссылками.
- Error Trigger - ловит фейлы и шлёт предупреждения.
Окей, а если я тоже так хочу?
Если ты дочитал до этого места и у тебя уже вертится мысль «хочу такого же зверя, чтобы узнавать о вкусных вакансиях раньше остальных» - это нормальная реакция. Или наоборот: ты сам нанимаешь людей и хочешь первым снимать сливки, как только кандидат с нужным стеком и вилкой выложил резюме и начал шевелиться на рынке.
В обоих кейсах можно не изобретать велосипед и не тратить недели на эксперименты с лимитами HH и капризами n8n. Пиши мне:
- скинь стек, города, примерный объём (типа «20 вакансий в день в табличку» или «надо мониторить 5000+ по нескольким ролям»);
- выберем архитектуру под твой случай, договоримся, что именно парсим, куда складываем и какие метрики считаем.
Цель простая: собрать тебе рабочий парсер за вменяемое время, без «мы сделаем MVP за три месяца», а с понятным результатом - стабильный воркфлоу, который каждые N часов выгружает вакансии, чистит мусор, шлёт алерты и помогает либо зарабатывать, либо экономить время.
P.S. Главное правило парсинга HH - уважай лимиты API. Держи частоту около 1 запроса в несколько секунд, особенно на массовых выборках, иначе словишь 429 и временную блокировку, а твой ночной запуск превратится в тыкву.