DeepSeek OCR: Как запустить мощную модель распознавания текста на своем сервере
Отсканированные документы, PDF-файлы без текстового слоя, изображения с текстом — все это можно распознать с помощью искусственного интеллекта. Сегодня расскажу про DeepSeek OCR — одну из самых мощных vision-моделей для распознавания текста, которая показывает отличные результаты, особенно на русском языке.
Что такое DeepSeek OCR и почему он хорош?
DeepSeek OCR — это vision-language модель от компании DeepSeek с 3 миллиардами параметров. Она специально создана для оптического распознавания символов (OCR) и понимания документов. Модель использует инновационную технику "оптического сжатия контекста", которая позволяет эффективно обрабатывать 2D-макеты документов.
Ключевые преимущества:
- Высокая точность: до 97% точности распознавания
- Эффективность: использует в 10 раз меньше vision токенов, чем текстовые LLM-модели, что делает её в 10 раз более эффективной
- Поддержка сложных форматов: отлично справляется с таблицами, научными статьями и даже рукописным текстом
- Многоязычность: поддерживает почти 100 языков в одной модели
- Качество русского языка: по нашим тестам, качество распознавания русского языка заметно лучше, чем у других vision-моделей
- Сохранение структуры: восстанавливает структуру документа (заголовки, списки, таблицы) и выдает результат в формате Markdown
Как работает DeepSeek OCR?
Модель принимает на вход только изображение — это vision-модель, которая "читает" картинки и понимает, что там написано. Вам не нужны текстовые слои в PDF, не нужна предварительная обработка — просто отправляете изображение, получаете распознанный текст.
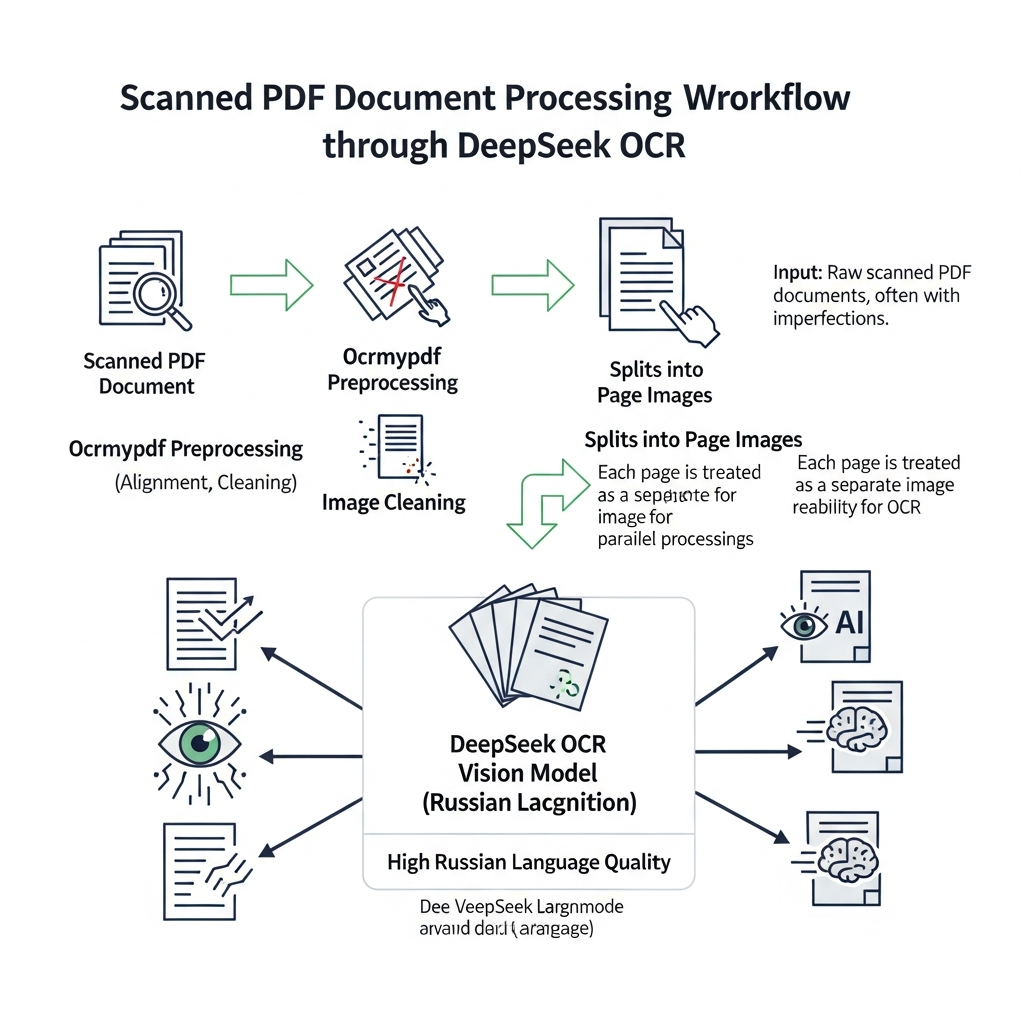
Для PDF-файлов мы используем специальный пайплайн:
1. Предобработка через ocrmypdf — исправляет ориентацию, выравнивает таблицы и текст, убирает артефакты сканирования
2. Разбивка на изображения — каждая страница PDF конвертируется в картинку
3. Распознавание через DeepSeek OCR — модель обрабатывает каждое изображение
4. Сборка документа обратно — все распознанные страницы объединяются в единый документ
Требования к железу для запуска DeepSeek OCR
Для запуска модели нужно довольно мощное железо, особенно если планируете обрабатывать большие объемы документов.
Минимальные требования:
- Видеокарта: NVIDIA GPU с поддержкой CUDA (минимум 8GB VRAM, рекомендуется 16GB+)
- Процессор: современный многоядерный процессор (AMD или Intel)
- Оперативная память: минимум 16GB RAM, рекомендуется 32GB+
- Дисковое пространство: минимум 20GB свободного места (для модели, библиотек и временных файлов)
- Операционная система: Linux (Ubuntu 20.04+ или Ubuntu Server 24.04)
Рекомендуемая конфигурация:
- Видеокарта: NVIDIA RTX 5090 (32GB VRAM) или RTX 4090/4080
- Процессор: AMD Ryzen 9 или Intel Core i9
- Оперативная память: 64GB RAM
- Диск: NVMe SSD с объемом 100GB+
Почему нужна мощная видеокарта? Модель DeepSeek OCR весит около 6-7GB в формате float16 и требует значительных вычислительных ресурсов для обработки изображений. Чем больше VRAM, тем больше страниц можно обрабатывать пакетно, что ускоряет работу.
Необходимые компоненты системы
Для запуска DeepSeek OCR должны быть установлены:
- Python 3.8+
- CUDA Toolkit 12.x (для RTX 5090)
- vLLM (для запуска модели)
- PyTorch с поддержкой CUDA
- poppler-utils (для работы с PDF)
- ocrmypdf (для предобработки PDF)
- pdf2image или PyMuPDF (для конвертации PDF в изображения)
Базовая документация по установке: https://docs.unsloth.ai/models/deepseek-ocr-how-to-run-and-fine-tune
Загрузка и запуск модели
Для запуска модели используем vLLM с моделью unsloth/DeepSeek-OCR. Вот как это реализовано:
```python
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
# Загрузка модели (загружается один раз)
llm = LLM(
model="unsloth/DeepSeek-OCR",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
gpu_memory_utilization=0.9,
max_model_len=8192,
)
# Настройки для обработки
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args=dict(
ngram_size=30,
window_size=90,
whitelist_token_ids={128821, 128822}, # whitelist: <td>, </td>
),
skip_special_tokens=False,
)
# Обработка одного изображения
prompt = "<image>\nFree OCR."
image = Image.open("your_image.jpg").convert("RGB")
outputs = llm.generate([{
"prompt": prompt,
"multi_modal_data": {"image": image}
}], sampling_params)
text = outputs[0].outputs[0].text
print(text)
```
При первом запуске модель загрузится с Hugging Face (это может занять 5-10 минут в зависимости от скорости интернета). Модель весит около 6-7GB.
Оптимизация для RTX 5090
RTX 5090 имеет 32GB VRAM, что позволяет работать с моделью в полной точности (float16) без необходимости квантизации. С таким объемом памяти можно обрабатывать несколько изображений одновременно в пакетном режиме.
Пакетная обработка PDF-файлов
Для обработки PDF используется пайплайн: предобработка через ocrmypdf → конвертация в изображения → распознавание через DeepSeek OCR → сборка обратно.
```python
from pdf2image import convert_from_path
import subprocess
from pathlib import Path
import tempfile
def process_pdf(pdf_path, output_path, llm):
# Шаг 1: Предобработка через ocrmypdf (исправление ориентации)
with tempfile.NamedTemporaryFile(suffix='.pdf', delete=False) as tmp:
temp_pdf = tmp.name
subprocess.run([
'ocrmypdf',
'--rotate-pages', # Автоматическое исправление ориентации
'--skip-text', # Пропускать страницы с текстом
'-l', 'rus+eng', # Языки для определения ориентации
pdf_path,
temp_pdf
])
# Шаг 2: Конвертация PDF в изображения
images = convert_from_path(temp_pdf, dpi=300)
# Шаг 3: OCR через DeepSeek OCR
results = []
for i, image in enumerate(images, 1):
outputs = llm.generate([{
"prompt": "<image>\nFree OCR.",
"multi_modal_data": {"image": image}
}], sampling_params)
text = outputs[0].outputs[0].text
results.append(f"## Страница {i}\n\n{text}\n\n")
# Шаг 4: Сохранение результата
with open(output_path, 'w', encoding='utf-8') as f:
f.write(''.join(results))
# Удаление временного файла
os.unlink(temp_pdf)
# Использование
llm = LLM(model="unsloth/DeepSeek-OCR", ...) # Загружаем модель один раз
process_pdf("input.pdf", "output.md", llm)
```
Ключевые настройки:
- **ocrmypdf**: `--rotate-pages` для исправления ориентации, `--skip-text` для ускорения, `-l rus+eng` для русских и английских документов
- **vLLM**: `temperature=0.0` для детерминированных результатов, `max_tokens=8192` для длинных документов
- **ngram_size=30, window_size=90** — параметры для улучшения качества распознавания таблиц
Результаты работы
По нашим тестам, DeepSeek OCR показывает отличные результаты на русском языке. Качество распознавания заметно лучше, чем у других vision-моделей, особенно на сложных документах с таблицами, формулами и смешанным форматированием.
Модель отлично справляется с:
- Отсканированными документами
- PDF-файлами без текстового слоя
- Документами с таблицами
- Научными статьями с формулами
- Документами с рукописными заметками
Возможные проблемы и решения
1. Нехватка памяти GPU: Уменьшите `gpu_memory_utilization` в настройках vLLM (например, до 0.7-0.8). Для RTX 5090 с 32GB VRAM это обычно не требуется
2. Медленная загрузка модели: При первом запуске модель скачивается с Hugging Face. Последующие запуски будут быстрее, так как модель кэшируется локально
3. Ошибки с CUDA: Убедитесь, что версия PyTorch совместима с вашей версией CUDA. Для RTX 5090 нужна CUDA 12.1+
4. Проблемы с poppler: Если возникают ошибки при работе с PDF, убедитесь, что poppler-utils установлен
5. Ошибки ocrmypdf: Проверьте, что ocrmypdf установлен и доступен в PATH
Выводы
DeepSeek OCR — это мощный инструмент для распознавания текста из изображений и документов. При правильной настройке и достаточных ресурсах (особенно VRAM на GPU) модель показывает отличные результаты, особенно на русском языке.
Для запуска на Ubuntu Server 24.04 с RTX 5090 достаточно следовать инструкциям выше. Главное — иметь достаточно VRAM (32GB на RTX 5090 более чем достаточно) и правильно настроить окружение.
Если у вас есть опыт работы с OCR или вопросы по установке — делитесь в комментариях!