SAM Audio opensource
Позволяет извлекать любые звуки из любого аудио или видео источника, используя простые промпты
Работает с тремя категориями звуков:
Музыка
Изолирует инструменты и вокал
Речь
Извлекает речь из фонового шума, чёткая изоляция говорящего и разделение голосов
Общие звуки
Отделяет повседневные звуки - от шума трафика до лая собак - из сложных аудио миксов
Три типа промптов:
- Текстовые промпты - описываете звук словами
- Визуальные промпты - кликаете на часть видео, где слышен нужный звук
- Временные промпты (span prompts) - выбираете временной отрезок с целевым аудио
Использует Flow-matching Diffusion Transformer для генерации высококачественного аудио.
Работает в латентном пространстве DAC-VAE.
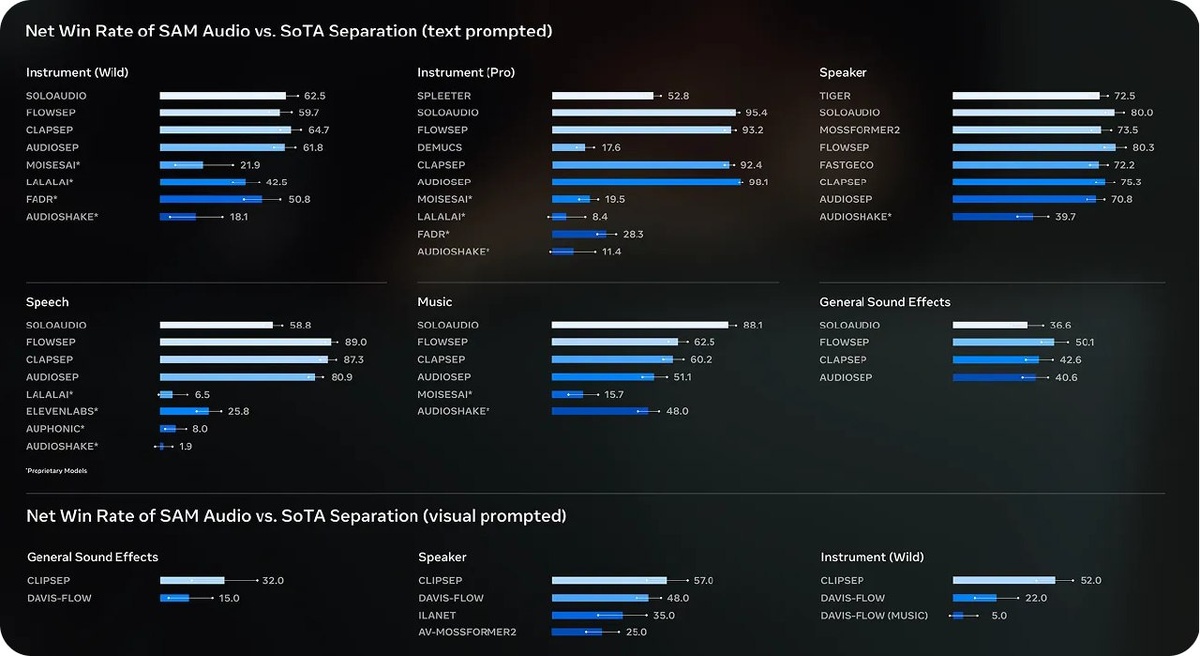
Достигает очень хорошей производительности во всех режимах промптинга.
Включает новый Perception Encoder Audio Video (PE-AV), открытую модель с аудио-возможностями