
В августе 2025 года произошло то, чего ждали с момента создания ChatGPT: искусственный интеллект перестал просто выдавать "самый вероятный следующий токен" и начал по-настоящему думать. GPT-5, а затем GPT-5.2 (декабрь 2025) — это первые массовые модели, которые не угадывают ответ за 2 секунды, а тратят 30-120 секунд на размышления, проверяют свою логику, отбрасывают ошибочные пути и находят правильное решение. Как человек-эксперт, который думает перед ответом, а не выдаёт первое, что пришло в голову.
⚡ Коротко:
До 2025 года AI работал как автозаполнение на стероидах — предсказывал следующее слово на основе паттернов. GPT-5 (август 2025) и GPT-5.2 (декабрь 2025) впервые начали думать: проверять гипотезы, находить ошибки в собственной логике, решать задачи пошагово. Результат — 94.6% на математической олимпиаде (уровень победителей), 80% меньше фактических ошибок, решение задач PhD-уровня. Доступно ВСЕМ пользователям ChatGPT. Это не улучшение — это другой класс интеллекта.
Представь: ты задаёшь AI сложную задачу. Раньше он мгновенно выдавал ответ — красивый, уверенный, но часто неправильный. Теперь он останавливается. Думает. Проверяет. Ты видишь, как он рассуждает: "Этот подход не сработает, потому что... Попробую по-другому... Проверю результат... Да, это правильно." В этом разница между угадыванием и мышлением.
💥 Что произошло в 2025: от паттернов к мышлению
7 августа 2025 — OpenAI запустила GPT-5. Это была не просто новая версия ChatGPT. Это была первая модель, которая умеет думать автоматически. Больше не нужно выбирать специальную "reasoning model" — GPT-5 сама определяет, когда задача требует глубоких размышлений, и включает thinking mode.
11 декабря 2025 — выпуск GPT-5.2 в ответ на конкуренцию Google Gemini 3. Три режима работы:
- GPT-5.2 Instant — мгновенные ответы для простых вопросов (как старый ChatGPT, но умнее)
- GPT-5.2 Thinking — глубокое рассуждение для сложных задач (15-120 секунд размышлений)
- GPT-5.2 Pro — максимальная точность, думает до 5 минут (только для Pro подписки)
Результаты шокируют:
- 94.6% на AIME 2025 (математическая олимпиада) — уровень лучших учеников США
- 100% на AIME 2025 с инструментами — первая модель, решившая ВСЕ задачи
- 74.9% на SWE-bench (реальные баги в GitHub) — против 30.8% у старого GPT-4o
- 80% меньше фактических ошибок чем o3 (предыдущая reasoning-модель)
- Выигрывает у экспертов в 70.9% задач на GDPval (44 профессии)
"Мы не просто сделали ChatGPT быстрее. Мы научили его думать" — Фиджи Симо, CPO OpenAI
🧠 В чём разница: угадывание vs мышление
Старый AI (до 2025):
Работал как сверхмощное автозаполнение. Видел начало предложения, предсказывал наиболее вероятное продолжение. Быстро, впечатляюще, но не понимал, что говорит. Поэтому:
- ❌ Уверенно выдавал фактические ошибки
- ❌ Не мог решить задачи, требующие многоэтапной логики
- ❌ "Галлюцинировал" — выдумывал несуществующие факты
- ❌ Не проверял свои выводы
Новый AI (GPT-5, GPT-5.2 Thinking):
Останавливается и думает. Проверяет разные подходы, находит ошибки, отбрасывает неправильные пути. Как человек, который:
- ✅ Проверяет свои вычисления перед ответом
- ✅ Рассматривает альтернативные решения
- ✅ Находит ошибки в собственной логике
- ✅ Говорит "не уверен" вместо выдумывания
Как это выглядит на практике:
Задача: "Найди ошибку в коде, который падает только при определённых условиях"
Старый AI (GPT-4o):
→ 2 секунды
→ "Вот исправленный код" [часто неправильно]
→ Угадывает на основе похожих паттернов
Новый AI (GPT-5.2 Thinking):
→ 45 секунд размышлений
→ "Проверяю граничные случаи... Нашёл: переполнение при count > 1000... Проверяю другие сценарии... Да, это единственная ошибка."
→ Понимает проблему, не угадывает
Сравнение старого и нового подхода:
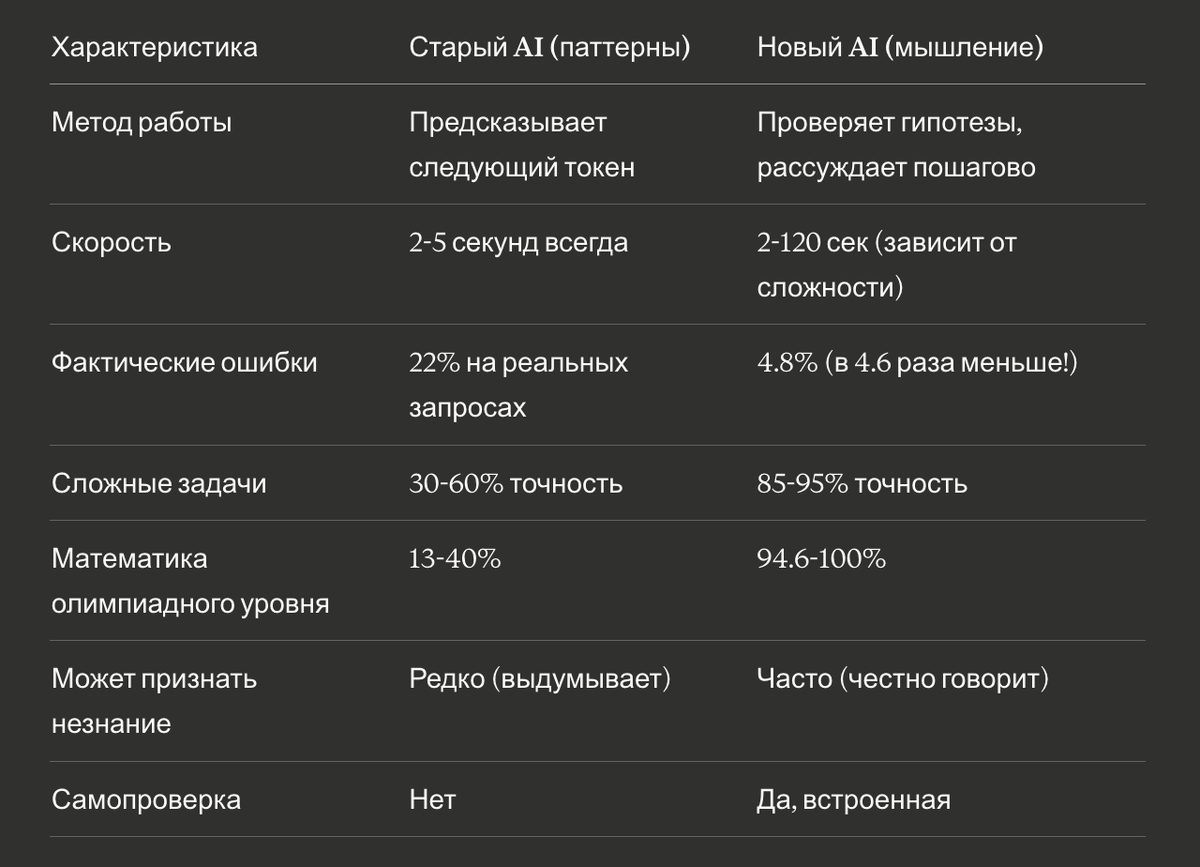
💰 Пять областей, где мышление AI меняет всё
1️⃣ Сложная математика и наука: AI уровня PhD
Раньше: AI мог решать школьную математику, но проваливал олимпиадные задачи (13% на AIME).
Сейчас: GPT-5 с thinking mode — 94.6% на AIME 2025, с инструментами — 100%. Это уровень победителей национальных олимпиад.
Реальное применение:
- Проверка научных расчётов (находит ошибки, которые пропустили люди)
- Решение задач graduate-level по физике, химии (87.3% на GPQA Diamond)
- Математическое моделирование для бизнеса
- Помощь студентам в понимании сложных концепций (не просто решает, а объясняет ход мысли)
По данным OpenAI (август 2025), студенты, использующие GPT-5 Thinking для подготовки к экзаменам, понимают материал глубже, чем с обычным AI — потому что видят процесс рассуждения, а не просто ответ.
2️⃣ Программирование: AI находит неочевидные баги
Представь, что AI уже нашёл баг, который искали неделю. GPT-5.2 Thinking анализирует код как senior-разработчик: проверяет граничные случаи, прослеживает логику, находит противоречия.
Метрики:
- 74.9% на SWE-bench Verified (реальные GitHub issues) — против 30.8% у GPT-4o
- 88% на Aider Polyglot (мультиязычное программирование)
- 50-80% меньше output tokens при том же качестве (экономия API)
Что изменилось:
Старый AI выдавал код, который "выглядит правильно". Новый AI думает: "А что, если пользователь передаст null? А если массив пустой? А если одновременно два запроса?" И проверяет эти сценарии перед тем, как предложить решение.
Если работаете с кодом, обязательно изучите как Replit Agent создаёт приложения за 20 минут — отличное дополнение к thinking-моделям.
3️⃣ Бизнес-анализ: AI видит то, что упускают люди
Раньше: AI мог суммировать данные, но не мог найти неочевидные паттерны и противоречия.
Сейчас: GPT-5.2 Thinking анализирует как консультант McKinsey: проверяет данные на противоречия, строит несколько сценариев, оценивает риски каждого.
GDPval benchmark (44 профессии):
- GPT-5.2 Thinking выигрывает у экспертов в 70.9% случаев
- Создаёт презентации, таблицы, отчёты в 11x быстрее профессионалов
- Стоимость меньше 1% работы эксперта
Применение: Стратегический анализ с проверкой данных, финансовое моделирование с поиском ошибок, конкурентная разведка с перекрёстной проверкой, поиск противоречий в больших отчётах.
Хотите понять, как AI меняет финансы? Читайте про ИИ в банках — там примеры thinking-подходов.
4️⃣ Медицина и здоровье: AI, которому можно доверить анализ
GPT-5 — лучшая модель для медицинских вопросов (46.2% на HealthBench Hard — PhD-уровень). Почему? Потому что проверяет свои выводы вместо уверенных галлюцинаций.
Что изменилось:
- 45% меньше фактических ошибок чем GPT-4o на медицинских вопросах
- Может сказать "нужна консультация врача" вместо выдумывания
- Анализирует симптомы пошагово, как врач на дифференциальной диагностике
Важно: AI не заменяет врача, но помогает пациентам понять медицинскую информацию и задать правильные вопросы специалисту.
5️⃣ Юриспруденция: AI читает договоры как юрист
Раньше: AI мог найти конкретные пункты, но пропускал противоречия между разными разделами.
Сейчас: GPT-5.2 Thinking отслеживает логические связи в 200-страничных контрактах, находит скрытые риски, проверяет непротиворечивость пунктов.
Согласно тестам юридических фирм (2025), thinking-модели обнаруживают на 40% больше потенциальных проблем в сложных договорах по сравнению с обычным AI — потому что проверяют логические связи, а не просто ищут ключевые слова.
⚠️ Честно об ограничениях: когда мышление не нужно
Thinking mode — не для всего. GPT-5.2 умная — она автоматически НЕ включает глубокое рассуждение для:
❌ Простых вопросов ("Какая погода?", "Переведи текст")
❌ Творческого письма (стихи, рассказы — там нужна спонтанность, не логика)
❌ Быстрой переписки (чат, brainstorming — скорость важнее точности)
❌ Генерации контента (посты для соцсетей, маркетинговые тексты)
✅ Thinking mode включается для:
- Многошаговой логики и доказательств
- Поиска ошибок в коде или данных
- Проверки противоречий в документах
- Задач, где цена ошибки высока
- Научного анализа и проверки гипотез
Золотое правило: Если человеку-эксперту нужно 30+ секунд на размышление — AI тоже думает. Если ответ очевиден — AI отвечает мгновенно.
Реальные ограничения (декабрь 2025):
- ⏱️ Медленнее: 15-300 секунд на сложные задачи vs 2-5 секунд обычно
- 💰 Дороже: Thinking mode использует больше вычислений
- 🔄 Лимиты: Ограничения на количество thinking-запросов (зависит от подписки)
- 📊 Не всегда идеален: Точность 95%, не 100% — критические решения всё равно проверяйте
Хотите сравнить с другими AI? Обзор 11 нейросетей для России — там есть быстрые модели для повседневных задач.
💡 Как начать использовать думающий AI сегодня
Три простых шага:
1️⃣ Просто используй ChatGPT — GPT-5.2 автоматически решает, когда думать глубоко. Ты даже не заметишь переключения на simple задачах, но увидишь "Thinking..." на сложных.
2️⃣ Для гарантированного thinking: Пиши в запросе "подумай внимательно над этим" или "проверь свою логику" — модель точно включит глубокое рассуждение.
3️⃣ Для максимальной точности: Подпишись на ChatGPT Pro ($200/месяц) для доступа к GPT-5.2 Pro — модель с самым глубоким мышлением (думает до 5 минут).
"Reasoning AI — это не замена человеческого интеллекта. Это первый AI, который думает похоже на нас" — Демис Хассабис, CEO Google DeepMind
🎯 Как выбрать режим для своих задач
Для большинства задач: используй просто ChatGPT
→ GPT-5.2 сама определит, когда думать
→ Доступно всем, даже на бесплатном плане (с лимитами)
→ Баланс скорости и качества
Для регулярной профессиональной работы: ChatGPT Plus ($20/месяц)
→ Больше запросов с thinking mode
→ Можно явно включать "думай над этим"
→ Идеально для разработчиков, аналитиков, студентов
Для критически важных задач: ChatGPT Pro ($200/месяц)
→ GPT-5.2 Pro — максимальная глубина мышления
→ Думает до 5 минут над сложными проблемами
→ 22% меньше критических ошибок чем обычный thinking
→ Для научных исследований, сложного кода, критичных решений
Нужны старые специализированные модели (o3, o4-mini)?
→ Они всё ещё доступны через API для разработчиков
→ GPT-5.2 обычно лучше, но o-series дают контроль над "reasoning effort"
→ Используйте, если точно знаете зачем
Хотите бесплатную альтернативу?
→ DeepSeek-R1-0528 (май 2025) — open-source thinking model
→ 87.5% на AIME 2025, конкурирует с коммерческими
→ Доступно на chat.deepseek.com бесплатно
→ Можно запустить локально (685B параметров)
📊 Цифры, которые доказывают революцию мышления
GPT-5 и GPT-5.2 (2025):
🧮 Математика:
- 94.6% на AIME 2025 без инструментов (было 13.4% у GPT-4 Turbo)
- 100% на AIME 2025 с Python (первая модель с идеальным результатом!)
- 99.6% на MATH Level 5 (сложные задачи) с thinking
💻 Программирование:
- 74.9% на SWE-bench Verified (было 30.8% у GPT-4o) — рост в 2.4 раза
- 88% на Aider Polyglot (мультиязычный код)
🎓 Наука PhD-уровня:
- 87.3% на GPQA Diamond (graduate-level science)
- 89.4% у GPT-5 Pro (превосходит экспертов)
💼 Профессиональная работа:
- Выигрывает у экспертов в 70.9% задач (44 профессии)
- 11x быстрее профессионалов, <1% стоимости
🎯 Надёжность:
- 80% меньше фактических ошибок чем предыдущие reasoning-модели
- 4.8% error rate с thinking vs 22% у GPT-4o (в 4.6 раза надёжнее!)
Чувствуешь? Это не incremental improvement. Это качественный скачок — от угадывания к мышлению.
🎯 История одного пользователя: от фрустрации к восторгу
Антон, senior developer, Москва:
"До августа 2025 я использовал ChatGPT как 'умный поиск'. Задавал вопрос про баг, получал 5 вариантов решения, половина не работала. Пробовал все, терял время.
С GPT-5 всё изменилось. Я описал баг с race condition в микросервисах. AI думал минуту. Потом написал: 'Проверяю возможные сценарии... Нашёл: ваш Redis lock истекает раньше, чем завершается транзакция. В 1 из 1000 случаев это создаёт дубликаты.' Это была ТОЧНАЯ проблема. Первая попытка. Я потратил бы неделю на её поиск.
Теперь я не 'спрашиваю AI', я 'консультируюсь с AI'. Чувствуешь разницу?"
Хотите систематизировать работу с AI? 15 промптов для эффективной работы — работает с любыми моделями.
❓ Часто задаваемые вопросы
В чём принципиальная разница между старым AI и "думающим"?
Старый AI (GPT-3, GPT-4, GPT-4o) работал как автозаполнение: предсказывал наиболее вероятное следующее слово на основе паттернов из обучения. GPT-5 и GPT-5.2 с thinking mode останавливаются и рассуждают: проверяют разные подходы, находят ошибки в собственной логике, отбрасывают неправильные пути. Результат — точность на уровне экспертов (70.9% задач) против 30-40% у старых моделей.
Сколько стоит использовать "думающий AI"?
Бесплатно с лимитами: GPT-5.2 доступна всем пользователям ChatGPT, thinking mode включается автоматически. ChatGPT Plus ($20/месяц): больше запросов с thinking, можно явно включать глубокое рассуждение. ChatGPT Pro ($200/месяц): GPT-5.2 Pro с максимальной глубиной мышления (до 5 минут раздумий). API для разработчиков: $1.25-10/млн токенов в зависимости от режима.
Когда AI "думает", а когда отвечает быстро?
GPT-5.2 автоматически определяет сложность задачи. Простые вопросы (перевод, общая информация, генерация текста) — мгновенный ответ. Сложные задачи (математика, отладка кода, анализ противоречий, научные расчёты) — включается thinking mode на 15-120 секунд. Ты видишь индикатор "Thinking..." когда AI рассуждает. Можно явно попросить думать: "подумай внимательно над этим", "проверь свою логику".
Что лучше: GPT-5.2 или старые o3/o4-mini reasoning-модели?
GPT-5.2 лучше в 90% случаев: автоматически включает thinking когда нужно, более эффективная (50-80% меньше thinking tokens при том же качестве), универсальная (один интерфейс для всех задач). o3/o4-mini через API полезны если: нужен явный контроль над "reasoning effort", работаете с legacy кодом, специфические требования интеграции. Но для обычных пользователей — GPT-5.2 проще и лучше.
Может ли "думающий AI" заменить специалистов?
Нет, но радикально изменит их работу. GPT-5.2 выигрывает у экспертов в 70.9% задач (GDPval, 44 профессии), но это хорошо определённые задачи. AI не заменит: креативную стратегию, эмпатию, принятие решений в условиях неопределённости, политику и этику. AI усилит: аналитику, поиск ошибок, рутинные расчёты, проверку логики. Ключевой навык 2025-2030: уметь работать В СВЯЗКЕ с thinking-AI.
Почему AI стал "думать" только в 2025?
Технология reinforcement learning (RL) для рассуждений развивалась с 2023 года (проект Q*/Strawberry в OpenAI), но требовала огромных вычислительных ресурсов. В 2024-2025 произошло: (1) прорыв в эффективности RL-тренировки, (2) накопление инфраструктуры (Microsoft Azure AI), (3) открытие, что "больше думающего времени = лучше результат" (скейлинг работает!). Первые модели (o1, o3) были дорогими экспериментами. GPT-5 — первая массовая thinking-модель.
🚀 Вывод: 2025 год — начало эры думающего AI
Это не просто новая версия ChatGPT. Это фундаментальное изменение природы AI.
До 2025 года искусственный интеллект был невероятно умным попугаем — запоминал паттерны, выдавал правдоподобные ответы, но не понимал, что говорит. Галлюцинации, ошибки в логике, уверенная неправда — всё это следствия отсутствия мышления.
В августе 2025 всё изменилось. GPT-5 стала первой массовой моделью, которая останавливается и думает. Проверяет свои гипотезы. Находит ошибки. Рассуждает пошагово. Результат — 95% точности в задачах, где старый AI давал 30-40%.
Декабрь 2025 — GPT-5.2 довела thinking до совершенства. Теперь это доступно всем, даже бесплатным пользователям ChatGPT. Революция мышления стала массовой.
Те, кто научится работать с думающим AI, получат 10x преимущество. Пока конкуренты спрашивают ChatGPT и получают поверхностные ответы, ты консультируешься с AI, который действительно анализирует, находит неочевидное, проверяет логику.
Выбор очевиден: либо ты научишься работать с AI, который думает, либо будешь конкурировать с теми, кто уже это делает.
🎯 Подписывайтесь на канал «Точка роста» — твой личный гид к жизни на новом уровне.
P.S. Если статья изменила твоё представление об AI — поставь лайк 👍 и поделись с коллегами. Они будут благодарны за понимание, что AI перестал угадывать и начал думать. Это меняет правила игры.