MiMo-V2-Flash
Xiaomi представили свою MoE лмку
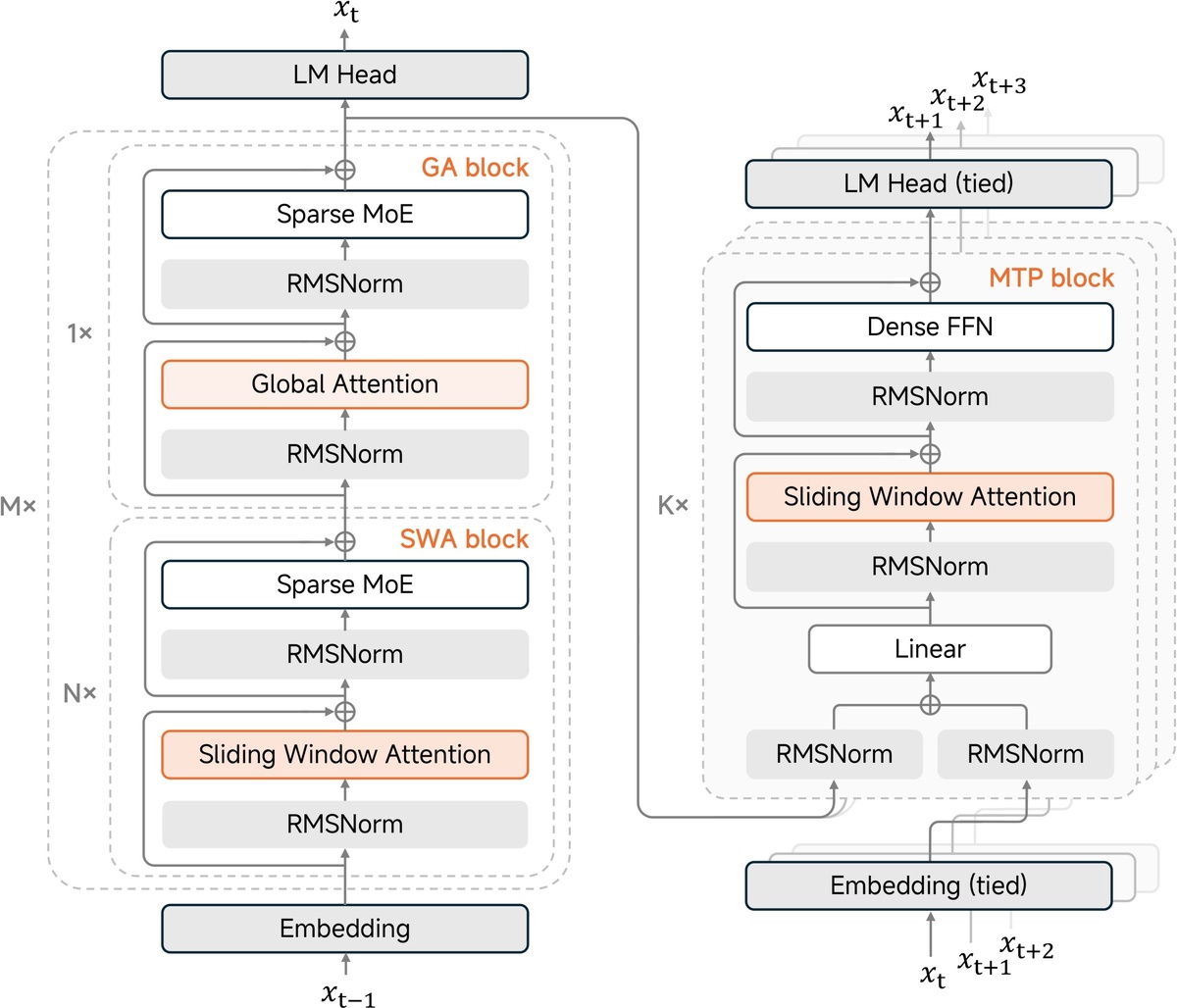
309 млрд параметров (всего) / 15 млрд активных параметров, гибридная архитектура внимания с соотношением Sliding Window Attention к Global Attention 5:1, Multi-Token Prediction (MTP) увеличивает скорость генерации в 3 раза
Контекст до 256K токенов, обучена на 27 триллионах токенов с использованием FP8 смешанной точности
🔘Технологии
Hybrid Sliding Window Attention
Новая архитектура внимания снижает требования к KV-кешу почти в 6 раз, используя агрессивное окно в 128 токенов при сохранении производительности на длинных контекстах
Multi-Token Prediction
Легковесный модуль MTP (всего 0.33B параметров на блок), подключили они егшо чтобы получить нативную поддержку спекулятивной декодировки, утраивая скорость вывода и ускоряя обучение с подкреплением
Multi-Teacher On-Policy Distillation (MOPD)
Подход к дистилляции знаний, формулирует процесс как задачу обучения с подкреплением с токен-уровневым руководством от экспертов
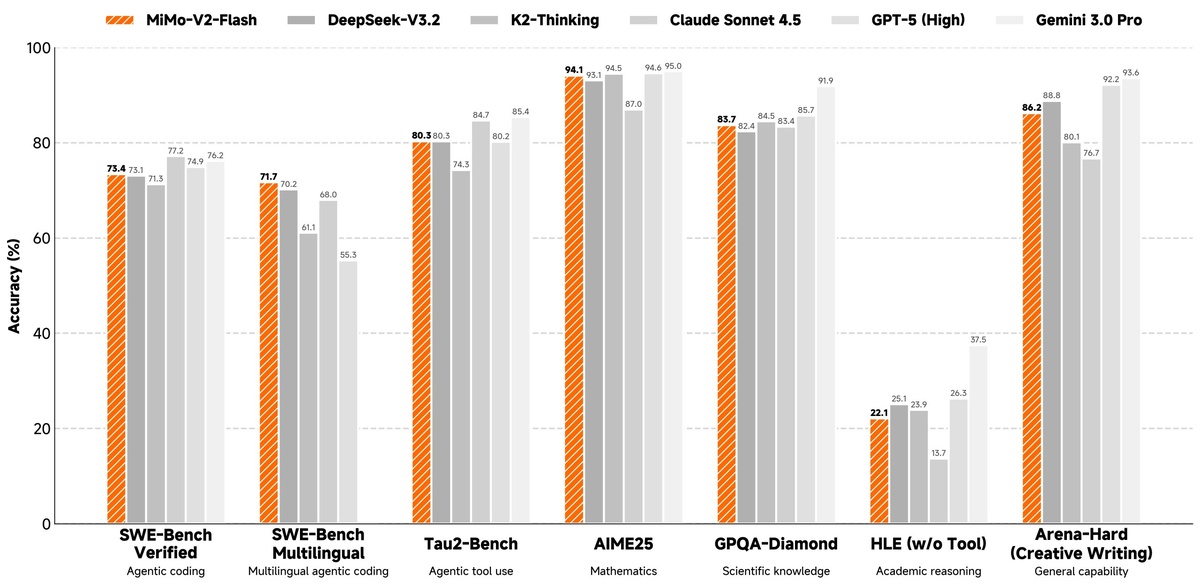
Бенчмарки базовой модели:
- AIME 24&25: 35.3% (лучше моделей с большим числом параметров)
- SWE-Bench: 30.8% (лидер среди моделей сопоставимого размера)
- NIAH-Multi 256K: 96.7% (работа с длинным контекстом)
- BigCodeBench: 70.1%
После пост-тренинга:
- AIME 2025: 94.1%
- SWE-Bench Verified: 73.4%
- GPQA-Diamond: 83.7%
- Arena-Hard (Creative Writing): 86.2%
🔘Агентные возможности
Масштабируемая кодовая среда: более 100,000 верифицируемых задач из реальных GitHub issues
Мультимодальный верификатор для WebDev: оценка кода через видеозаписи вместо статичных скриншотов
Кросс-доменная генерализация: обучение на кодовых агентах
🔘Развертывание
Поддерживает FP8 инференс и рекомендуется использовать SGLang для оптимальной производительности
pip install sglang
python3 -m sglang.launch_server \
--model-path XiaomiMiMo/MiMo-V2-Flash \
--enable-mtp
Рекомендуемые параметры сэмплинга:
- top_p=0.95
- temperature=0.8 для математики, написания текстов, веб-разработки
- temperature=0.3 для агентных задач